一、微服务的注册与发现——Eureka
和许多分布式设计一样,分布式的应用一般都会有一个服务中心,用于记录各个机器的信息。微服务架构也一样,我们把一个大的应用解耦成这么多个那么多个服务,那么在想要调用这些服务的时候要怎么办呢?
这个时候就需要我们的Eureka了,它是用来发现和注册各个微服务的,简单理解这个东西的作用就是,告诉你现在有哪些微服务,他们的IP啊端口什么的,然后告诉你怎么去调用他们。
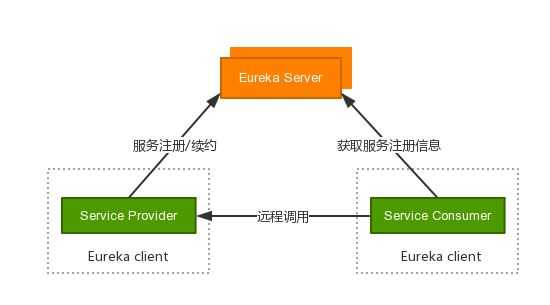
下面的图简单的描述了大致的过程:
Spring Cloud提供了多种注册中心的支持:如Eureka、consul、Zookeeper等,推荐使用Eureka。Spring Cloud Eureka是Spring Cloud Netflix微服务套件中的一部分,它基于Netflix,Eureka做了二次封装。主要负责完成微服务架构中的服务治理功能。
原理图如下所示: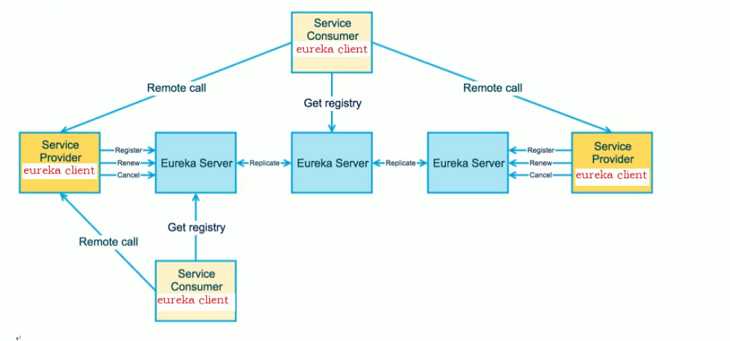
Server是服务端,Client是客户端,其中Eureka Server是一个Eureka的集群,作为注册中心,服务提供方将服务提交给注册中心,服务消费者从注册中心获取服务信息,进行调用。
Eureka包含两个组件:Eureka Server和Eureka Client。
Eureka Server提供服务注册服务,各个节点启动后,会在Eureka Server中进行注册,这样EurekaServer中的服务注册表中将会存储所有可用服务节点的信息,服务节点的信息可以在界面中直观的看到。
Eureka Client是一个java客户端,用于简化与Eureka Server的交互,客户端同时也就别一个内置的、使用轮询(round-robin)负载算法的负载均衡器。
在应用启动后,将会向Eureka Server发送心跳,默认周期为30秒,如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,Eureka Server将会从服务注册表中把这个服务节点移除(默认90秒)。
Eureka Server之间通过复制的方式完成数据的同步,Eureka还提供了客户端缓存机制,即使所有的Eureka Server都挂掉,客户端依然可以利用缓存中的信息消费其他服务的API。综上,Eureka通过心跳检查、客户端缓存等机制,确保了系统的高可用性、灵活性和可伸缩性。
服务提供者、服务消费者、服务发现组件这三者之间的关系:
大概的配制就是:
服务端
server: port:8761 eureka: client: registerWithEureka:false fetchRegistry:false serviceUrl: defaultZone:http://localhost:8761/eureka/ //配置解释: /* eureka.client.registerWithEureka:表示是否将自己注册到Eureka Server,默认为true。由于当前应用就是Eureka Server,故而设置为false。 eureka.client.fetchRegistry:表示是否从Eureka Server获取注册信息,默认为true。因为这是一个单点的Eureka Server,不需要同步其他的Eureka Server节点的数据,故而设置为false。 eureka.client.serviceUrl.defalseZone:设置与Eureka Server交互的地址,查询服务和注册服务都需要依赖这个地址,多个地址可用,用,分割。 */
客户端:

以上信息参考自文章:
https://blog.csdn.net/wangruoao/article/details/83038764——《Spring Cloud学习笔记之Eureka框架的原理》图片和原理的介绍是来自这里
https://www.cnblogs.com/liuzunli/articles/7978782.html——《微服务的注册与发现(基于Eureka)》三者关系来自这里,文章还有简单的实战
https://www.cnblogs.com/lfalex0831/p/9184428.html——《SpringCloud-微服务的注册与发现Eureka(二)》Eureka实战和高可用什么的
二、zuul网关
我们有那么多的微服务接口,每个服务都有自己的IP和端口,如果让客户端直接和这些服务通信,会很麻烦而且会有很多缺点:
让客户端直接与各个微服务通讯,会有以下的问题:
面对类似上面的问题,我们要如何解决呢?下面进入本文的正题:服务网关!
使用网关优点:
大概的配置样子:
URL配置:
spring.application.name=api-gateway server.port=5555 zuul.routes.api-test.path=/api-test/** zuul.routes.api-test.url=http://localhost:2223/,http://localhost:2221/
这是通过URL映射的方式来进行配置
什么意思呢,大概就是对所有api-test/开头的请求都拦截下来,然后交给本机ip的2223端口还有本机ip的2221端口来处理。

(用serviceI-id的配置)这个时候的配置是这样的:
spring.application.name=api-gateway server.port=5555 zuul.routes.api-test.path=/api-test/** zuul.routes.api-test.url=http://localhost:2223/ zuul.routes.api-a.path=/api-a/** zuul.routes.api-a.serviceId=COMPUTE-SERVICE zuul.routes.api-b.path=/api-b/** zuul.routes.api-b.serviceId=COMPUTE-SERVICE-B eureka.client.serviceUrl.defaultZone=http://localhost:1111/eureka/
service-id就是在Eureka中配置的那个微服务的主机名。
效果:

网关还可以起着服务过滤的作用,大概就是Filter这样,这里不细讲了。
Zuul的内容参见文章:
https://www.cnblogs.com/duanxz/p/7527765.html——《服务网关zuul之一:入门介绍》
三、Ribbon
这个是拿来做负载均衡的一个东西。
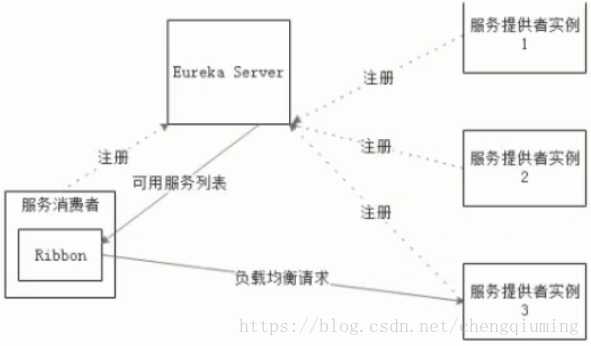
Ribbon是Netflix发布的负载均衡器,它有助于控制HTTP和TCP的客户端的行为。为Ribbon配置服务提供者地址后,Ribbon就可基于某种负载均衡算法,自动地帮助服务消费者去请求。Ribbon默认为我们提供了很多负载均衡算法,例如轮询、随机等。当然,我们也可为Ribbon实现自定义的负载均衡算法。
在Spring Cloud中,当Ribbon与Eureka配合使用时,Ribbon可自动从Eureka Server获取服务提供者地址列表,并基于负载均衡算法,请求其中一个服务提供者实例。
其他就不做介绍了hh
内容来自:
https://blog.csdn.net/chengqiuming/article/details/80711168——《Ribbon的基本应用》
四、Hystrix
在一个分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,如何能够保证在一个依赖出问题的情况下,不会导致整体服务失败,这个就是Hystrix需要做的事情。Hystrix提供了熔断、隔离、Fallback、cache、监控等功能,能够在一个、或多个依赖同时出现问题时保证系统依然可用。
Hystrix是这样一个框架,通过添加容忍延迟和容错逻辑,可帮助我们控制这些分布式服务之间的交互。 Hystrix通过隔离各个服务之间的访问点,减少服务之间的级联故障以及为我们提供回滚策略来实现这一点,所有这些都可以提高分布式系统的整体弹性。
大概就是一个保护分布式系统或者说这个微服务架构正常运行的一个东西吧~
原文:https://www.cnblogs.com/wangshen31/p/10536146.html