建两个.py文件分别是是读取xlsx文件内容,一个是测试用例使用ddt驱动
import xlrd class ParseExcel(object): def __init__(self,path,sheelName): self.wa = xlrd.open_workbook(path) self.sheet = self.wa.sheet_by_name(sheelName) self.max = self.sheet.nrows def getDatasFromSheet(self): dataList = [] list = 0 for list in range(1,self.max): print(self.sheet.row_values(list)) lin = self.sheet.row_values(list) print(lin[1]) tmpList = [] tmpList.append(lin[1]) tmpList.append(lin[2]) dataList.append(tmpList) return dataList
import ddt from selenium import webdriver import unittest from Extel import ParseExcel import time from selenium.common.exceptions import NoSuchElementException path = "D:\\测试数据.xlsx" sheelName = "Sheet1" excel = ParseExcel(path,sheelName) @ddt.ddt class TestDemo(unittest.TestCase): def setUp(self): self.deriver = webdriver.Chrome() @ddt.data(*excel.getDatasFromSheet()) def test_dataDrivenByFile(self,data): TestData,expectData = tuple(data) url = "http://www.baidu.com" self.deriver.get(url) self.deriver.maximize_window() print(TestData,expectData) self.deriver.implicitly_wait(10) try: self.deriver.find_element_by_id("kw").send_keys(TestData) print(‘执行了‘) self.deriver.find_element_by_id("su").click() time.sleep(3) print(‘执行了‘) source = self.deriver.page_source self.assertTrue(expectData in source) except NoSuchElementException: print("查找页面元素不存在") except AssertionError: print(u"搜索%s期望%s,失败" % (TestData, expectData)) except Exception: print(‘报错‘) else: print(u"搜索%s期望%s,通过"%(TestData,expectData)) def tearDown(self): self.deriver.quit() if __name__ == "__main__": unittest.main()
表格内容
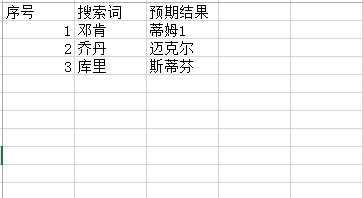
后期可以接入logging打印日志
原文:https://www.cnblogs.com/zhmiao/p/10536290.html