Linux文本处理三剑客
grep:文本过滤(模式:pattern)工具
>grep, egrep, fgrep(不支持正则表达式搜索)- sed:stream editor,文本编辑工具
- awk:Linux上的实现gawk,文本报告生成器
格式:grep [OPTIONS] PATTERN [FILE...]
[OPTIONS]:
>--color=auto: 对匹配到的文本着色显示
>-m # 匹配#次后停止
>-v 显示不被pattern匹配到的行
>-I 忽略字符大小写
>-n 显示匹配的行号
>-c 统计匹配的行数
>-o 仅显示匹配到的字符串
>-q 静默模式,不输出任何信息
>-A # after, 后#行
>-B # before, 前#行
>-C # context, 前后各#行
>-e 实现多个选项间的逻辑or关系
>grep –e ‘cat ’ -e ‘dog’ file
>-w 匹配整个单词
>-E 使用ERE
>-F "grep -f"相当于fgrep命令,不支持正则表达式
>-f file 根据模式文件处理,就是把过滤条件写在文本里,可以是很多条件- PATTERN:(可以是字符也可以是正则表达式)
总结:
grep的工作方式是:逐行处理。grep有一个内存空间,假如有一个文件有六行,grep会先把文件的第一行放到内存空间进行处理,如果第一行有关键字就进行打印;接着把第二行放到内存空间处理,如果第二行没有关键字,就不管它;接着把第三行放到内存空间处理,依次类推处理文本的每一行。
示例1:
注意""和‘‘和所表示的含义。即""表示特定符号,如变量;‘‘表示字符,不管你是不是特定符号,在‘‘里面都将表示表面意思,即字符;表示命令的结果,即``里面可写命令,最后表现的结果就是命令的结果。
grep root /etc/passwd(过滤/etc/passwd文件中带root的行)
grep "$USER" /et/passwd(过滤/etc/passwd文件中带USER变量的行)
grep ‘$USER‘ /etc/passwd(过滤/etc/passwd文件中带$USER字符的行)
grepwhoami/etc/passwd(过滤/etc/passwd文件中带"whoami命令结果"的行)
示例2:挑选特定的行
挑选带root的行,找到一行就结束
grep -m1
whoami/etc/passwd
示例3:显示不被模式(PATTERN)匹配到的行
显示不匹配root的行
grep -v root /etc/passwd
示例4:忽略大小写
显示root,root忽略大小写
grep -i ROOT /etc/passwd
示例5:显示行号
显示匹配root的行并标明行号
grep -n root /etc/passwd
示例6:显示匹配的行数
显示匹配root的行数有几行
grep -c root /etc/passwd
示例7:仅显示匹配到的字符,并且每个字符为一行
仅显示匹配的root
grep -o root /etc/passwd
示例8:找到找不到,模式对不对都不显示
grep -q root /etc/passwd
执行完上面的命令后,上面的命令一般配合echo $?,如果结果为0便是“成功”;$?结果非0,表示“失败”。
示例9:找到行的前几行、后几行、中间几行
有时候我们要找的东西不是很容易找,但是它旁边的行比较容易找,所以“-A”选项找到指定行的后#行(包括指定行);“-B” 选项找到指定行的前#行(包括指定行); “-C”选项找到指定行的前后#行(包括指定行)。
示例10:包含多个字符串的行
使用“-e”,或的意思。如下面例子,显示/etc/passwd中root或wang的字符
grep -e root -e wang /etc/passwd
显示/etc/passwd中root并且bash的字符
grep root /etc/passwd | grep bash
示例11:显示匹配单词的行
“-w”选项表示匹配单词为什么什么的行(如root的行),如果不加“-w”显示匹配什么字符的行(如root的行也算,roother的行也算)。单词的范围是字母数字下划线(如1root、2_root),如果标点符号就不是单词(如“;root”和“;root-”,注意双引号不能丢)。
grep -w root /etc/passwd
正则表达式是处理文件内容的,通配符是处理文件名的。如果用正则表达式处理文件名也行,就是把正则表达式当成字符串,如加“\”符号,所以没人这么用。
介绍:
- REGEXP:Regular Expressions(正则表达式),由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能,例如“通配符”。
- 支持:grep,sed,awk,vim, less,nginx,varnish等
分两类,两个只是写法有点区别,实现功能都一样:
> 基本正则表达式:BRE(写法:grep -E)
> 扩展正则表达式:ERE(写法:egrep)- 正则表达式引擎:
正则表达式由于要匹配字符,所以背后有一些算法来支撑处理这些字符的功能,在不同的算法中,PCRE(Perl Compatible Regular Expressions)是著名的检查处理正则表达式算法的软件模块之一,PCRE是基于Perl语言实现的(老牌语言)。- 表达正则表达式的元字符的分类:
字符匹配、匹配次数、位置锚定、分组- 正则表达式的帮助:man 7 regex
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符,示例:[wang]包含w,a,n,g字符的行
[^] 匹配指定范围外的任意单个字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母 [:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字 [:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
示例:匹配/etc/passwd文件中大写字母的行
grep ‘[[:upper:]]‘ /etc/passwd
用在要指定次数的字符后面,用于指定前面的字符要出现的次数

示例1:*的贪婪模式,有多少都要匹配
匹配a字符
echo aaabc | grep "a*"
aaabc(匹配成功)
注释:下面的示例因为文本编辑器不支持“\"号,所以用图片表示。

练习题:使用grep前面已知的知识,匹配出当前的IP地址
答案:


注意:[^#]是匹配不是#号开头的一个字符的行;“^#”是匹配#号开头且位于行首的行
示例1:行首锚定,用于模式的最左侧
匹配root,位于行首的行
grep "^root" /etc/passwd
示例2:行尾锚定,用于模式的最右侧
匹配以“bash”结尾的行
grep "bash$" /etc/passwd
示例3:匹配文本中的空行
grep "^$" /etc/fstab
示例4:匹配文本中的空白行
grep "^[[:space:]]*$"
示例5:匹配单词词首,匹配的字符位于模式的最左侧(注意不是行的最左侧)
匹配单词root,位于词首
grep " \ <root" /etc/passwd -->注意:反斜线和小于号之间没有空格,因为文本编辑器的原因我只能加空格才能显示。
或者
grep "\broot" /etc/passwd
示例6:匹配单词词尾,匹配的字符位于模式的最右侧(注意不是行的最右侧)
匹配单词root,位于词尾
grep "root\ >" /etc/passwd ->注意:反斜线和小于号之间没有空格,因为文本编辑器的原因我只能加空格才能显示。
或者
grep "root\b" /etc/passwd
示例7:匹配整个单词
匹配单词是root的行
grep "\ <root\ >" /etc/passwd -->注意反斜线和小于号之间没有空格
或者
grep "\broot\b" /etc/passwd

示例1:匹配abc为整体的行

示例2:多次分组
显示分组abcabcabc和xyz

示例3:多次分组和后续引用
显示分组abcabcabc和xyz和abc
**注意:“\1”表示第一个分组中,最后匹配的最终结果,而不是单纯的如示例中的abc;那么“\2”就表示第二个分组中,最后匹配的最终结果。如果不明白请看示例4。

示例4:多次分组和后续引用
“\1”表示匹配第一个分组中,最后匹配的最终结果。但有一个前提,最终结果不能是一个。例如用下面图片说明:因为rXXt在后面没有出现过,所以尝试redt,发现redt出现过一次,后面又出现了,符合(“\1”表示匹配第一个分组中,最后匹配的最终结果),所以结果是匹配是字符是redt root redt,而不是rXXt,也不是root。

示例5:多次分组后续引用
“\1”表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
“\2”表示小括号里面的小括号string2
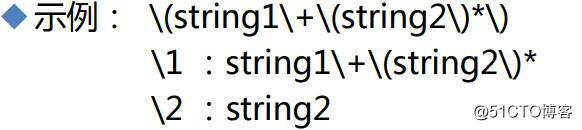
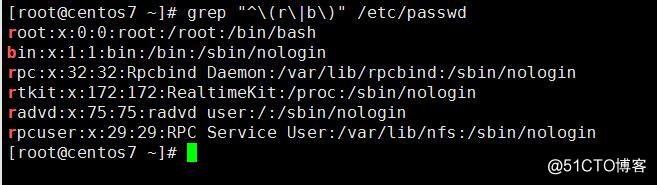
示例6:或者
匹配/etc/passwd文件中以r开头或者以b开头的行
示例7:或者
匹配abc或d

示例8:或者
匹配abc或abd

练习
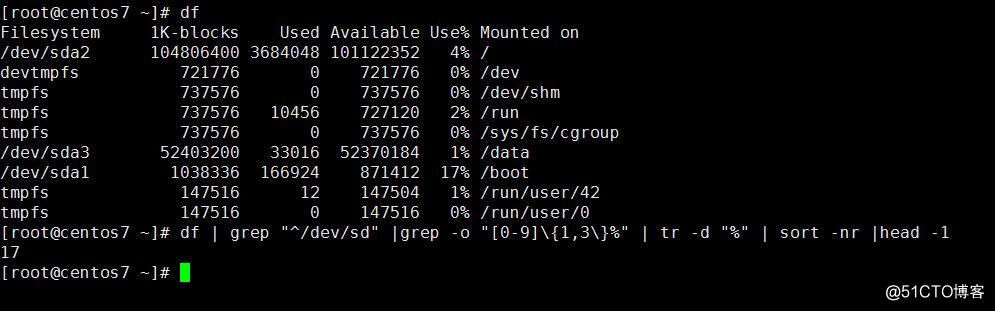
1.取出分区利用率最大值
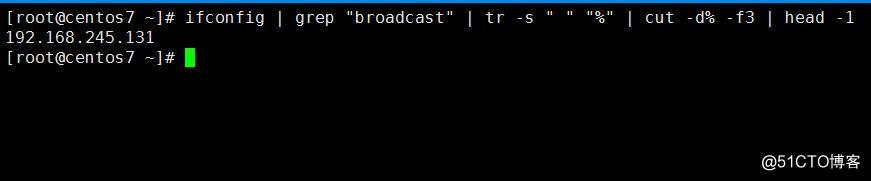
2.取出IP地址
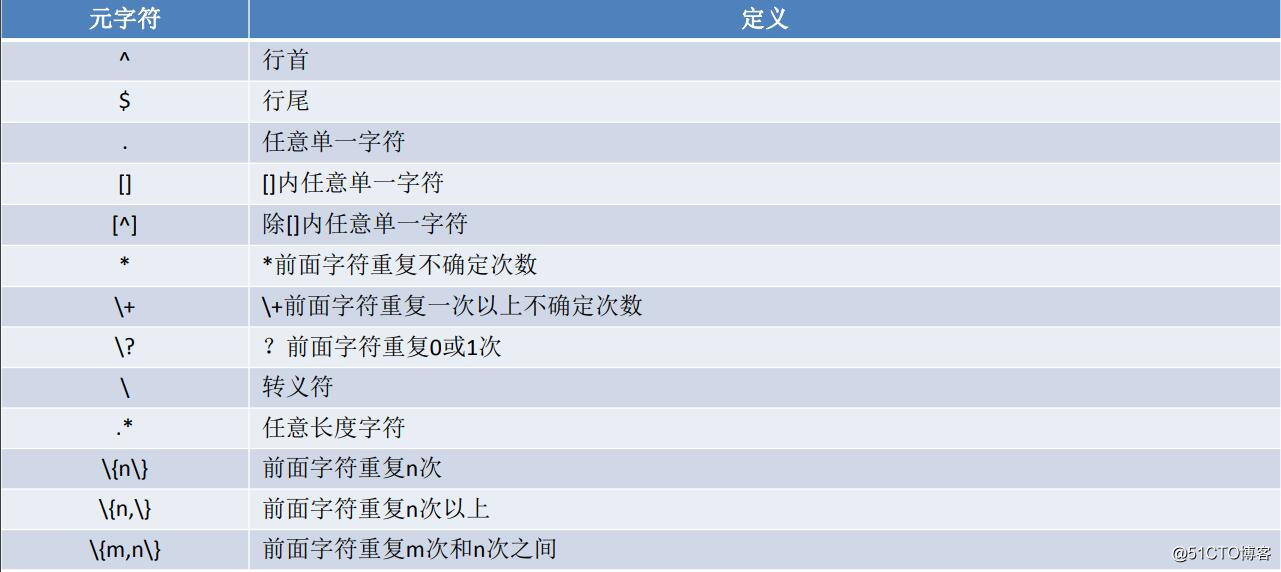
元字符表

练习题

扩展正则表达式和基本正则表达式只是写法有一点区别,实现的功能都一样。写法的区别在于:书写基本正则表达式时,加上“-E”选项或者grep写成egrep,然后基本正则表达式后面的“\”都不用写,就是扩展正则表达式(有一个例外,就是位置锚定的词首词尾的“\”不能不写)。那么大家可能会说基本正则表达式的书写太难记了,直接记扩展正则表达式。很严重的告诉你不行,因为有些命令或有些脚本等情况,只支持基本正则表达式,或者只支持扩展正则表达式,或者想grep都支持,所以两个都要掌握。
egrep = grep -E
egrep [OPTIONS] PATTERN [FILE...]
扩展正则表达式的元字符:(参考基本正则表达式,下面是一些示例)
. 任意单个字符
[] 指定范围的字符
[^] 不在指定范围的字符



练习题

示例:显示IP地址

原文:https://blog.51cto.com/13465487/2365974