2019年3月22日13:20:38
论文名:
Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning
from Monocular Videos
代码: https://github.com/tensorflow/models/tree/master/research/struct2depth
看论文效果,说是可以处理运动区域,甚至计算出面前的汽车的移动速度。
对tensorflow不熟,算是一边学tensorflow,一边看这个算法。
另外,jupyter notebook是个好东西,可以自己给自己写教程。。。
最后发现这个库的代码根本不完善!!!
说是可以预测移动的物体,但是:
Similar to the ego-motion model, it takes an RGB image sequence as input,
but this time complemented by pre-computed instance segmentation masks.
也就是先做了实例分割。
https://github.com/tensorflow/models/issues/6173
他们先用mask-rcnn在另一个数据集上训练了实例分割,生成了X-seg.png
用align.py对准后,生成了 X-fseg.png 图片。
这就有点死循环了,我还指望着深度估计能够提升语义分割和动态场景的处理的效果呢,结果这。。。
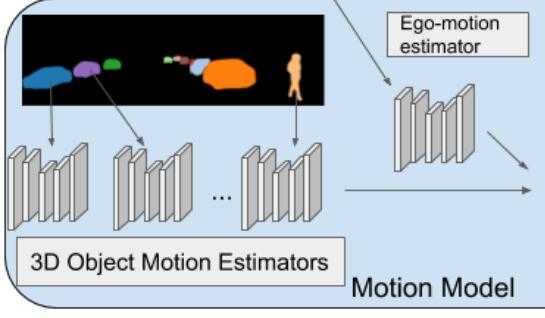
这个流程图里头,用于训练的也是实例分割图片,暗示这个网络就算处理移动物体,也是训练
过的类别才能处理。
在readme里头也不清清楚楚的写出来。。。
gen_data部分,针对 city 数据集和 kitti 数据集操作不一样。
因为要用align.py比对并产生fseg图片,city数据集有标注好的实例分割图片,
kitti没有,然而我没下city数据集。。。然后我就跳过handle_motion部分的代码了。
不过这个库本身已经包含了DDVO的深度正则化的步骤在里头了。
原文:https://www.cnblogs.com/shepherd2015/p/10577788.html