学习来源 公众号:有三AI https://mp.weixin.qq.com/s/u-QTHFSA-8rwvL0KBVYXjQ
深度学习模型评估指标
一个深度学习模型在各类任务中的表现都需要定量的指标进行评估,才能够进行横向的对比比较,包含了分类、回归、质量评估、生成模型中常用的指标。
1 分类评测指标
图像分类是计算机视觉中最基础的一个任务,也是几乎所有的基准模型进行比较的任务,从最开始比较简单的10分类的灰度图像手写数字识别mnist,到后来更大一点的10分类的cifar10和100分类的cifar100,到后来的imagenet,图像分类任务伴随着数据库的增长,一步一步提升到了今天的水平。现在在Imagenet这样的超过1000万图像,2万类的数据集中,计算机的图像分类水准已经超过了人类。
图像分类,顾名思义就是一个模式分类问题,它的目标是将不同的图像,划分到不同的类别,实现最小的分类误差,这里只考虑单标签分类问题,即每一个图片都有唯一的类别。
对于单个标签分类的问题,评价指标主要有Accuracy,Precision,Recall,F-score,PR曲线,ROC和AUC。
在计算这些指标之前,先计算几个基本指标,这些指标是基于二分类的任务,也可以拓展到多分类:
标签为正样本,分类为正样本的数目为True Positive,简称TP;
标签为正样本,分类为负样本的数目为False Negative,简称FN;
标签为负样本,分类为正样本的数目为False Positive,简称FP;
标签为负样本,分类为负样本的数目为True Negative,简称TN。
判别是否为正例只需要设一个概率阈值T,预测概率大于阈值T的为正类,小于阈值T的为负类,默认就是0.5。如果我们减小这个阀值T,更多的样本会被识别为正类,这样可以提高正类的召回率,但同时也会带来更多的负类被错分为正类。如果增加阈值T,则正类的召回率降低,精度增加。如果是多类,比如ImageNet1000分类比赛中的1000类,预测类别就是预测概率最大的那一类。
1. 准确率Accuracy
单标签分类任务中每一个样本都只有一个确定的类别,预测到该类别就是分类正确,没有预测到就是分类错误,因此最直观的指标就是Accuracy,也就是准确率。
Accuracy=(TP+TN)/(TP+FP+TN+FN),表示的就是所有样本都正确分类的概率,可以使用不同的阈值T。
在ImageNet中使用的Accuracy指标包括Top_1 Accuracy和Top_5 Accuracy,Top_1 Accuracy就是前面计算的Accuracy。
记样本xi的类别为yi,类别种类为(0,1,…,C),预测类别函数为f,则Top-1的计算方法如下:
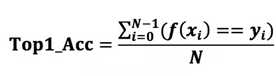
如果给出概率最大的5个预测类别,只要包含了真实的类别,则判定预测正确,计算出来的指标就是Top-5。目前在ImageNet上,Top-5的指标已经超过95%,而Top-1的指标还在80%左右。
2. 精确度Precision和召回率Recall
如果只考虑正样本的指标,有两个很常用的指标,精确度和召回率。
正样本精确率为:Precision=TP/(TP+FP),表示的是召回为正样本的样本中,到底有多少是真正的正样本。
正样本召回率为:Recall=TP/(TP+FN),表示的是有多少样本被召回类。当然,如果对负样本感兴趣的,也可以计算对应的精确率和召回率,这里记得区分精确率和准确率的分别。
通常召回率越高,精确度越低,根据不同的值可以绘制Recall-Precision曲线,如下图:
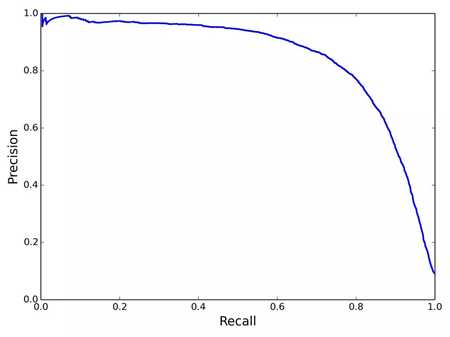
横轴就是recall,纵轴就是precision,曲线越接近右上角,说明其性能越好,可以用该曲线与坐标轴包围的面积来定量评估,值在0~1之间。
3. F1 score
有的时候关注的不仅仅是正样本的准确率,也关心其召回率,但是又不想用Accuracy来进行衡量,一个折中的指标是采用F-score。
F1 score=2·Precision·Recall/(Precision+Recall),只有在召回率Recall和精确率Precision都高的情况下,F1 score才会很高,因此F1 score是一个综合性能的指标。
4.混淆矩阵
如果对于每一类,若想知道类别之间相互误分的情况,查看是否有特定的类别之间相互混淆,就可以用混淆矩阵画出分类的详细预测结果。对于包含多个类别的任务,混淆矩阵很清晰的反映出各类别之间的错分概率,如下图:
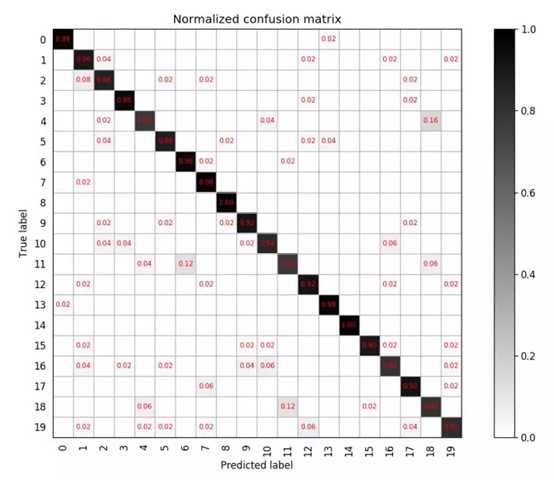
上图表述的是一个包含20个类别的分类任务,混淆矩阵为20*20的矩阵,其中第i行第j列,表示第i类目标被分类为第j类的概率,越好的分类器对角线上的值更大,其他地方应该越小。
5.ROC曲线与AUC指标
以上的准确率Accuracy,精确度Precision,召回率Recall,F1 score,混淆矩阵都只是一个单一的数值指标,如果想观察分类算法在不同的参数下的表现情况,就可以使用一条曲线,即ROC曲线,全称为receiver operating characteristic。
ROC曲线可以用于评价一个分类器在不同阈值下的表现情况。在ROC曲线中,每个点的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR),描绘了分类器在True Positive和False Positive间的平衡,两个指标的计算如下:
TPR=TP/(TP+FN),代表分类器预测的正类中实际正实例占所有正实例的比例。
FPR=FP/(FP+TN),代表分类器预测的正类中实际负实例占所有负实例的比例,FPR越大,预测正类中实际负类越多。
ROC曲线通常如下:
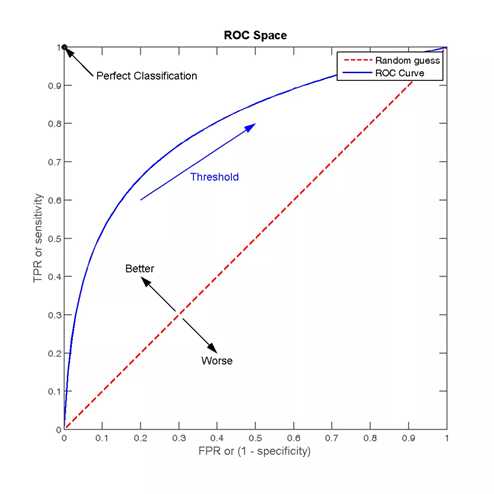
其中有4个关键的点:
点(0,0):FPR=TPR=0,分类器预测所有的样本都为负样本;
点(1,1):FPR=TPR=1,分类器预测所有的样本都为正样本;
点(0,1):FPR=0, TPR=1,此时FN=0且FP=0,所有的样本都正确分类;
点(1,0):FPR=1,TPR=0,此时TP=0且TN=0,最差分类器,避开了所有正确答案。
ROC曲线相对于PR曲线有个很好的特性:
当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变,即对正负样本不均衡问题不敏感。比如负样本的数量增加到原来的10倍,TPR不受影响,FPR的各项也是成比例的增加,并不会有太大的变化。所以不均衡样本问题通常选用ROC作为评价标准。
ROC曲线越接近左上角,该分类器的性能越好,若一个分类器的ROC曲线完全包住另一个分类器,那么可以判断前者的性能更好。
如果想通过两条ROC曲线来定量评估两个分类器的性能,就可以使用AUC指标。
AUC(Area Under Curve)为ROC曲线下的面积,它表示的就是一个概率,这个面积的数值不会大于1。随机挑选一个正样本以及一个负样本,AUC表征的就是有多大的概率,分类器会对正样本给出的预测值高于负样本,当然前提是正样本的预测值的确应该高于负样本。
6. TAR,FRR,FAR
这几个指标在人脸验证中被广泛使用,人脸验证即匹配两个人是否是同一个人,通常用特征向量的相似度进行描述,如果相似度概率大于阈值T,则被认为是同一个人。
TAR(True Accept Rate)表示正确接受的比例,多次取同一个人的两张图像,统计该相似度值超过阈值T的比例。FRR(False Reject Rate)就是错误拒绝率,把相同的人的图像当做不同人的了,它等于1-TAR。
与之类似,FAR(False Accept Rate)表示错误接受的比例,多次取不同人的两张图像,统计该相似度值超过T的比例。
增大相似度阈值T,FAR和TAR都减小,意味着正确接受和错误接受的比例都降低,错误拒绝率FRR会增加。减小相似度阈值T,FAR和TAR都增大,正确接受的比例和错误接受的比例都增加,错误拒绝率FRR降低。
2 检索与回归指标
1.IoU
IoU全称Intersection-over-Union,即交并比,在目标检测领域中,定义为两个矩形框面积的交集和并集的比值,IoU=A∩B/A∪B。
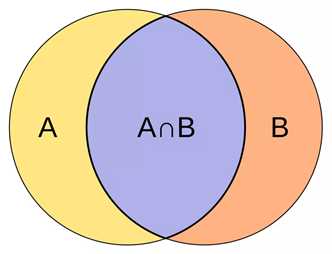
如果完全重叠,则IoU等于1,是最理想的情况。一般在检测任务中,IoU大于等于0.5就认为召回,如果设置更高的IoU阈值,则召回率下降,同时定位框也越更加精确。
在图像分割中也会经常使用IoU,此时就不必限定为两个矩形框的面积。比如对于二分类的前背景分割,那么IoU=(真实前景像素面积∩预测前景像素面积)/(真实前景像素面积∪预测前景像素面积),这一个指标,通常比直接计算每一个像素的分类正确概率要低,也对错误分类更加敏感。
2.AP和mAP
Average Precision简称AP,这是一个在检索任务和回归任务中经常使用的指标,实际等于Precision-Recall曲线下的面积,这个曲线在上一小节已经说过,下面针对目标检测中举出一个例子进行计算,这一个例子在网上也是广泛流传。
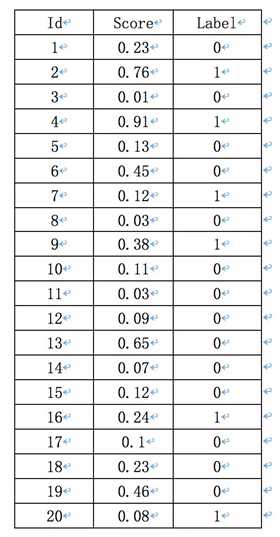
假如一幅图像,有10个人脸,检索出来了20个目标框,每一个目标框的概率以及真实的标签如下,真实标签的计算就用检测框与真实标注框的IoU是否大于0.5来计算。
第一步,就是根据模型得到概率,计算IoU得到下面的表:
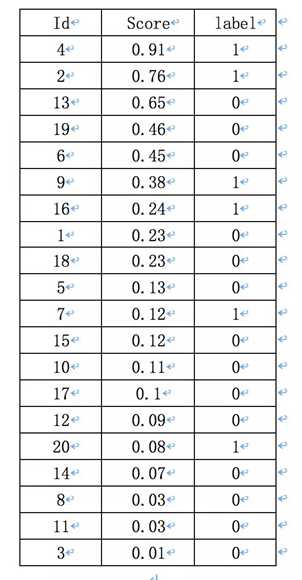
第二步,将上面的表按照概率进行排序
Precision的计算如下,以返回的top-5结果为例:
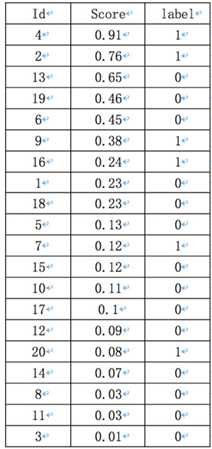
在这个例子中,true positives就是真正的人脸,从Label一栏可以看出,指的是id = 4,2,7,9,16,20的样本。
前5个概率值最大的id中13,19,6是false positives。所以此时的Precision=2/5=40%,即选定了5个人脸,但是只有两个是对的。recall=2/6=33.3%,即总共有6个人脸,但是只召回了2个。
在一个实际的目标检测任务中,目标的数量不一定是5个,所以不能只通过top-5来来衡量一个模型的好坏,选定的id越多,recall就越高,precision整体上则会呈现出下降趋势,因为排在前面的概率高的,一般更有可能是真实的样本,而后面概率低的更有可能是负样本。
令N是所有id,如果从top-1到top-N都统计一遍,得到了对应的precision和recall,以recall为横坐标,precision为纵坐标,则得到了检测中使用的precision-recall曲线,虽然整体趋势和意义与分类任务中的precision-recall曲线相同,计算方法却有很大差别。
PASCAL VOC 2010年提出了一个更好的指标mAP,对于样本不均衡的类的计算更加有效。假设有N个id,其中有M个label,则取M个recall节点,从0到1按照1/M的等间距,对于每个recall值,计算出大于该recall值的最大precision,然后对这M个precision值取平均得到最后的AP值,mAP的计算方法不变。
AP衡量的是学出来的模型在一个类别上的好坏,mAP衡量的是学出的模型在所有类别上的好坏。
3 图像质量评价指标
图像在获取,压缩,存储,传输,解压缩,显示,甚至打印的过程中,都有可能受到环境的干扰造成质量下降。图像的质量,通常跟图像噪声,模糊,对比度,美学等有关系。
在图像质量评估的指标中,根据对原始无损图像的要求,通常分为三大类,分别是Full Reference Image Quality Assessment(FR-IQA)全参考图像评价,Reduced Reference Image Quality Assessment(FR-IQA)半参考图像评价,No Reference Image Quality Assessment(FR-IQA)无参考图像评价。
Full Reference Image Quality Assessment(FR-IQA)全参考图像评价,需要原始的高质量的图像。常见的(FR-IQA)包括峰值信噪比PSNR,结构一致性相似因子structural similarity index measurement(SSIM),视觉信息保真度 (Visual information fidelity, VIF),视觉信噪比 (Visual signal-to-noise ratio, VSPR),最显著失真 (Most apparent distortion, MAD)等。
Reduced Reference Image Quality Assessment(RR-IQA)半参考图像评价,不需要原始图像本身,但是需要一些特征,在卫星和遥感图像中被使用的较多。RR-IQA类方法常常在不同的特征空间中使用,主要思路是对FR-IQA类评价指标进行近似。
No Reference Image Quality Assessment(NR-IQA)无参考图像评价,完全基于图像本身,不再需要原始图。不过由于没有原始的图像,需要对原始的图像进行统计建模,同时还要兼顾人眼的视觉特征,本来这就有一定的主观和不确定性。虽然研究人员提出了数十个NR-IQA指标,但是真正广泛使用的没有几个。另外无参考的美学质量评估也是当前比较开放的一个问题,它需要更多考虑摄影学等因素。
质量评价因子非常的多,限于篇幅仅介绍其中4个:
1.信噪比SNR与峰值信噪比PSNR
信噪比,即SNR(SIGNAL-NOISE RATIO),是信号处理领域广泛使用的定量描述指标。它原是指一个电子设备或者电子系统中信号与噪声的比例,计量单位是dB,其计算方法是10*lg(Ps/Pn),其中Ps和Pn分别代表信号和噪声的有效功率,也可以换算成电压幅值的比率关系:20*lg(Vs/Vn),Vs和Vn分别代表信号和噪声电压的“有效值”。
在图像处理领域,更多的是采用峰值信噪比PSNR (Peak Signal to NoiseRatio),它是原图像与处理图像之间均方误差(Mean Square Error)相对于(2^n-1)^2 的对数值,其中n是每个采样值的比特数,8位图像即为256。
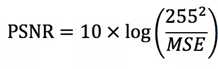
PSNR越大表示失真越小,均方误差的计算如下:
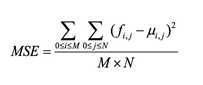
其中M,N为图像的行与列数,μi,j是像素灰度平均值,fi,j即像素灰度值。
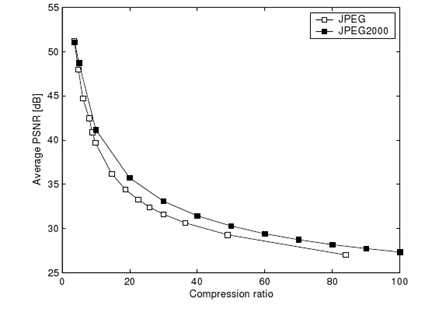
下面展示了JPEG和JPEG2000算法在不同压缩率下的PSNR,通常PSNR大于35的图像质量会比较好。
2.结构一致性相似因子SSIM
PSNR从底层信噪的角度来评估图像的质量,但是人眼对质量的评价关注的层次其实更高。根据Human visual system model,人眼观察图像有几个特点:
(1)低通过滤器特性,即人眼对于过高的频率难以分辨。(2)人眼对亮度的敏感大于对颜色的敏感。(3)对亮度的响应不是线性变换的,在平均亮度大的区域,人眼对灰度误差不敏感。(4)边缘和纹理敏感,有很强的局部观察能力。
structural similarity index measurement(SSIM)是一种建立在人眼的视觉特征基础上的用于衡量两幅图像相似度的指标,结果在0~1之间。
结构相似性理论认为自然图像信号是高度结构化的,空域像素间有很强的相关性并蕴含着物体结构的重要信息。它没有试图通过累加与心理物理学简单认知模式有关的误差来估计图像质量,而是直接估计两个复杂结构信号的结构改变,并将失真建模为亮度、对比度和结构三个不同因素的组合。用均值作为亮度的估计,标准差作为对比度的估计,协方差作为结构相似程度的度量。
PSNR忽略了人眼对图像不同区域的敏感度差异,在不同程度上降低了图像质量评价结果的可靠性,而SSIM能突显轮廓和细节等特征信息。
SSIM具体的计算如下:首先结构信息不应该受到照明的影响,因此在计算结构信息时需要去掉亮度信息,即需要减掉图像的均值;其次结构信息不应该受到图像对比度的影响,因此计算结构信息时需要归一化图像的方差。
通常使用的计算方法如下,其中C1,C2,C3用来增加计算结果的稳定性,光度L,对比度C,结构对比度S计算如下:
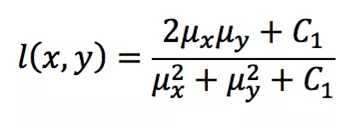
ux,uy为图像的均值
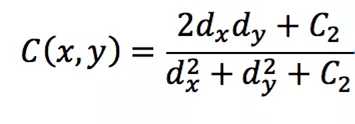
dx,dy为图像的方差
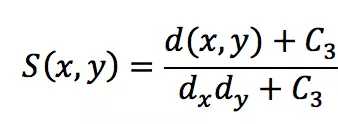
d(x,y)为图像x,y的协方差。而图像质量SSIM = L(x,y)^aC(x,y)^bS(x,y)^c,其中a,b,c分别用来控制三个要素的重要性,为了计算方便可以均选择为1,C1,C2,C3为比较小的数值,通常C1=(K1×L)^2, C2=(K2×L)^2,C3 = C2/2, K1 << 1, K2 << 1,L为像素的最大值(通常为255)。当a,b,c都等于1,C3=C2/2时,SSIM的定义式就为:
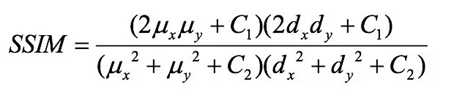
SSIM发展出了许多的改进版本,其中较好的包括Fast SSIM,Multi-scale SSIM。
3.无参考锐化因子CPBD
上面说的这两个,都是需要参考图像才能进行评价的,而CPBD即cumulative probability of blur detection (CPBD),是一种无参考的图像锐化定量指标评价因子。它是基于模糊检测的累积概率来进行定义,是基于分类的方法。
首先要说Just-noticeable-distortion-model,简称JND模型,即恰可察觉失真模型,它建模人眼能够察觉的图像底层特征,只有超过一定的阈值才会被察觉为失真图像。如果在空间域计算,一般会综合考虑亮度,纹理等因素,比如用像素点处局部平均背景亮度值作为亮度对比度阈值,用各个方向的梯度作为纹理阈值。如果在变换域计算,则可以使用小波系数等,这里对其计算方法就不再详述。
在给定一个对比度高于JND (Just Noticeable Difference)参考的情况下,定义JNB (Just-noticeable-blue)指标为感知到的模糊像素的最小数目,边缘处像素的模糊概率定义如下:
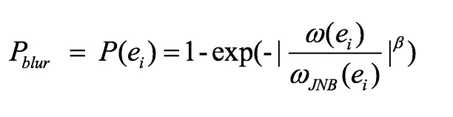
其中分子是基于局部对比度的JNB边缘宽度,而分母是计算出的边缘宽度。对于每一幅图像,取子块大小为64×64,然后将其分为边缘块与非边缘块,非边缘块不做处理。对于每一个边缘块,计算出块内每个边缘像素的宽度。当pblur<63%,该像素即作为有效的像素,用于计算CPBD指标,定义如下:
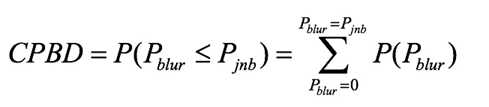
CPBD的作者采用了高斯模糊的图像与JPEG压缩图像进行实验,表明CPBD是符合人类视觉特性的图像质量指标,值越大,所反映出的细节越清晰,模糊性越弱。因此,可以将此指标用于定量评判滤波后的图像的锐化质量。
4 图像生成评价指标
当需要评估一个生成模型的性能的时候,有2个最重要的衡量指标。
(1) 确定性:生成模型生成的样本一定属于特定的类别,也就是真实的图像,而且必须要是所训练的图片集,不能用人脸图像训练得到了手写数字。
(2) 多样性:样本应该各式各样,如果用mnist进行训练,在没有条件限制的条件下,应该生成0,1,2,3…,而不是都是0,生成的各个数字也应该具有不同的笔触,大小等。除此之外,还会考虑分辨率等。
1.inception score
inception score是最早的用于GAN生成的图像多样性评估的指标,它利用了google的inception模型来进行评估,背后的思想就完美满足上面的两个衡量指标。
Inception图像分类模型预测结果是一个softmax后的向量,即概率分布p(y|x)。一个好的分类模型,该向量分布的熵应该尽可能地小,也就是样本必须明确符合某一个类,其中的一个值很大,剩下的值很小。另外,如果把softmax后的向量组合并在一起形成另一个概率分布p(y),为了满足多样性,这个分布的熵应该是越大越好,也就是各种类别的样本都有。
具体实现就是让p(y|x)和p(y)之间的KL散度越大越好,连续形式的表达如下:
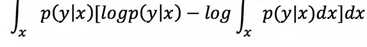
实际的计算就是将积分换成求和:
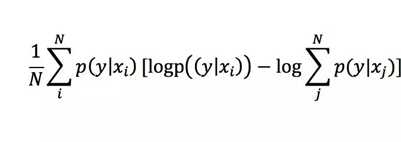
Inception Score是一个非常好的评价指标,它同时评估生成图像的质量和多样性,前段时间大火的BigGAN,就是将Inception Score提升为原来最好模型的3倍不止。
不过Inception Score也有缺陷,因为它仅评估图像生成模型,没有评估生成的图像与原始训练图像之间的相似度,因此虽然鼓励模型学习了质量好,多样性好的图像,但是却不能保证是我们想要的图像。Mode分数对其进行了改进,增加了KL散度来度量真实分布P_r与生成分布P_g之间的差异。
2.Kernel MMD
最大平均差异maximum mean discrepancy Kernel也是一个用于判断两个分布p和q是否相同的指标。它的基本假设就是如果两个样本分布相似,那么通过寻找在样本空间上的连续函数f,求不同分布的样本f函数的均值,计算均值的差作为两个分布在f函数下的平均差异,选择其中最大值就是MMD。
对于深度学习任务来说,可以选择各种预训练模型的特征空间,比如性能很好的ResNet。MMD方法的样本复杂度和计算复杂度都比较低,不过是有偏的,关键就在于用于选择的函数空间是否足够丰富。
除了以上指标外,还有Wasserstein距离,Fréchet Inception距离等。
原文:https://www.cnblogs.com/jeshy/p/10585905.html