conda install scrapy
scrapy startproject douban
# -*- coding: utf-8 -*- # Scrapy settings for douban project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # http://doc.scrapy.org/en/latest/topics/settings.html # http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html # http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html BOT_NAME = ‘douban‘ SPIDER_MODULES = [‘douban.spiders‘] NEWSPIDER_MODULE = ‘douban.spiders‘ # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = ‘douban (+http://www.yourdomain.com)‘ # USER_AGENT = ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:52.0) Gecko/20100101 Firefox/52.0‘ USER_AGENT=‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36‘ # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # ‘Accept‘: ‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, # ‘Accept-Language‘: ‘en‘, #} # Enable or disable spider middlewares # See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html #SPIDER_MIDDLEWARES = { # ‘douban.middlewares.DoubanSpiderMiddleware‘: 543, #} # Enable or disable downloader middlewares # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html #DOWNLOADER_MIDDLEWARES = { # ‘douban.middlewares.MyCustomDownloaderMiddleware‘: 543, #} # Enable or disable extensions # See http://scrapy.readthedocs.org/en/latest/topics/extensions.html #EXTENSIONS = { # ‘scrapy.extensions.telnet.TelnetConsole‘: None, #} # Configure item pipelines # See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { ‘douban.pipelines.DoubanPipeline‘: 300, } # Enable and configure the AutoThrottle extension (disabled by default) # See http://doc.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = ‘httpcache‘ #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = ‘scrapy.extensions.httpcache.FilesystemCacheStorage‘
import scrapy from douban.items import DoubanItem class MeijuSpider(scrapy.Spider): name = ‘doubanmovie‘ allowed_domains=[‘book.douban.com‘] start_urls=[‘https://book.douban.com/tag/%E4%BA%92%E8%81%94%E7%BD%91‘] number=1; def parse(self, response): self.number = self.number+1; # print(response.text) objs=response.xpath(‘//*[@id="subject_list"]/ul/li‘) # print(objs) # print(‘test‘,response.xpath(‘//*[@id="content"]/div/div[1]/div/div/table[1]/tr/td[2]/div/a/text()‘).extract_first()) print(len(objs)) for i in objs : item=DoubanItem() item[‘name‘]=i.xpath(‘./div[2]/h2/a/text()‘).extract_first() or ‘‘ item[‘score‘]=i.xpath(‘./div[2]/div[2]/span[2]/text()‘).extract_first() or ‘‘ item[‘author‘]=i.xpath(‘./div[2]/div[1]/text()‘).extract_first() or ‘‘ item[‘describe‘]=i.xpath(‘./div[2]/p/text()‘).extract_first() or ‘‘ yield item next_page = response.xpath(‘//*[@id="subject_list"]/div[2]/span[4]/a/@href‘).extract() print(self.number); if(self.number >11): next_page = response.xpath(‘//*[@id="subject_list"]/div[2]/span[5]/a/@href‘).extract() print(next_page) if next_page: next_link=next_page[0]; print("https://book.douban.com"+next_link) yield scrapy.Request("https://book.douban.com"+next_link,callback=self.parse)
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don‘t forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html class DoubanPipeline(object): def process_item(self, item, spider): with open(‘douban.txt‘,‘a‘,encoding=‘utf-8‘) as file: file.write(str(item[‘name‘].replace("\n","").replace("\t","").replace(",",",").replace("\r","").strip() ) +‘,‘+item[‘score‘].replace("\n","").replace("\t","").replace(",",",").replace("\r","").strip() +‘,‘+str(item[‘author‘]).replace("\n","").replace("\t","").replace(",",",").replace("\r","").strip() +‘,‘+item[‘describe‘].replace("\n","").replace("\t","").replace(",",",").replace("\r","").strip() + "\n" )
from scrapy.cmdline import execute execute("scrapy crawl doubanmovie".split())
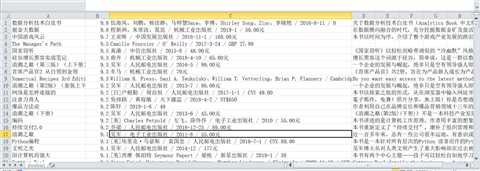
原文:https://www.cnblogs.com/dzhou/p/10587094.html