所以,为了得到泛化误差小的模型,在构建机器模型时,通常将数据集拆分为相互独立的训练数据集、验证数据集和测试数据集等,而在训练过程中使用验证数据集来评估模型并据此更新超参数,训练结束后使用测试数据集评估训练好的最终模型的性能。
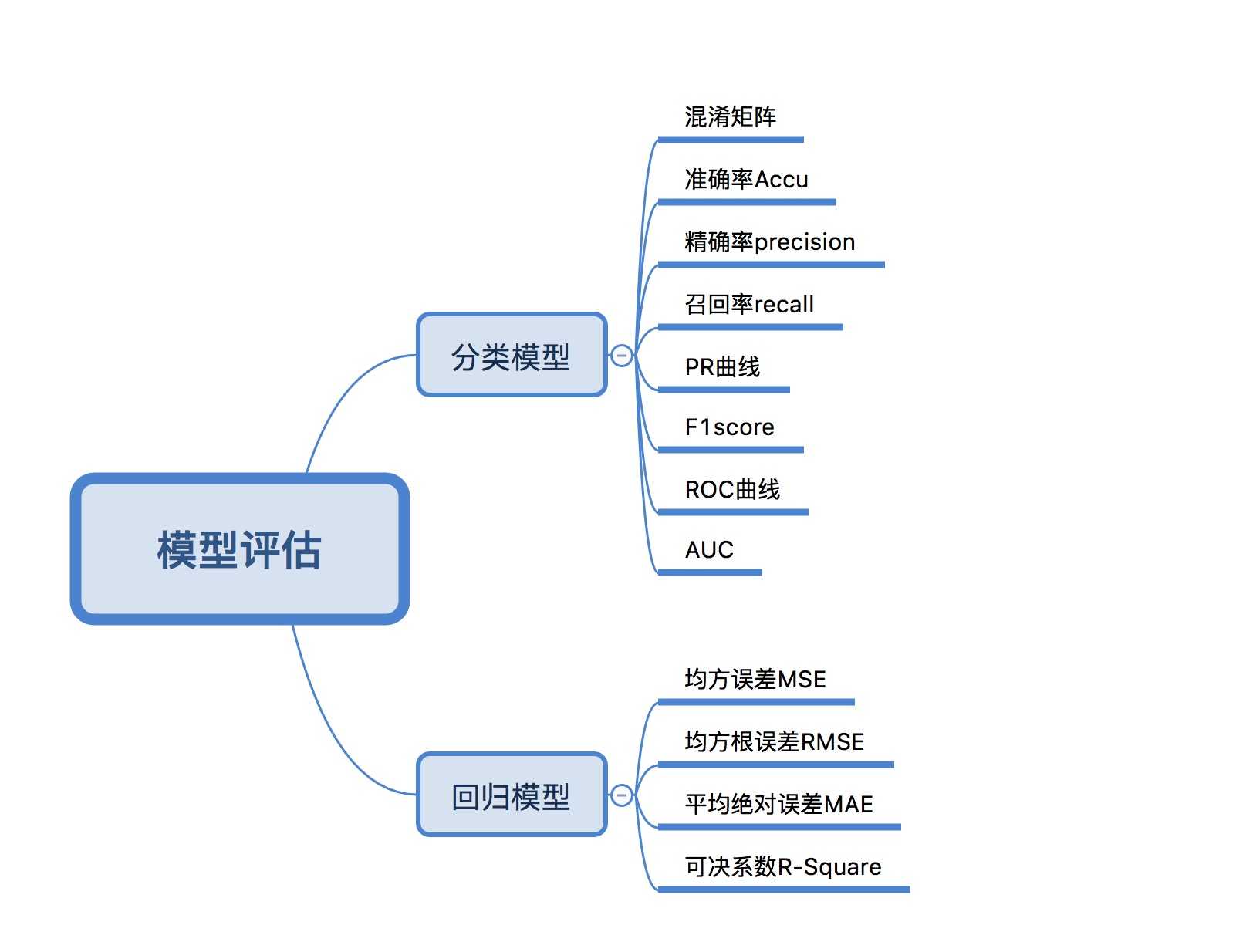
| 指标 | 描述 | Scikit-learn函数 |
|---|---|---|
| Confusion Matrix | 混淆矩阵 | from sklearn.metrics import confusion_matrix |
| Precision | 精确率 | from sklearn.metrics import precision_score |
| Recall | 召回率 | from sklearn.metrics import recall_score |
| F1 | F1值 | from sklearn.metrics import f1_score |
| ROC | ROC曲线 | from sklearn.metrics import roc |
| AUC | ROC曲线下的面积 | from sklearn.metrics import auc |
其中,\(\hat{y_i}\)是预测值,\(\bar{y_i}\)是预测值的平均值。\(R^2<=1\)且越大越好。
| 指标 | 描述 | Scikit-learn函数 |
|---|---|---|
| Mean Square Error (MSE, RMSE) | 平均方差 | from sklearn.metrics import mean_squared_error |
| Absolute Error (MAE, RAE) | 绝对误差 | from sklearn.metrics import mean_absolute_error, median_absolute_error |
| R-Squared | R平方值 | from sklearn.metrics import r2_score |
原文:https://www.cnblogs.com/zingp/p/10612558.html