超详细官方教程解析
https://blog.csdn.net/fly_yr/article/details/51540269
实战过程:
【1】创建Scrapy项目
scrapy startproject TestDemo
若进入到相应的文件目录下,在地址栏输入cmd进入命令行界面,输入以上命令,则会在相应的文件目录下建立一个项目

创建spider.py命令:scrapy genspider -t basic 名字 网址
也可以手动创建
运行爬虫时,在项目所在目录的地址栏cmd,进入,输入 scrapy crawl 爬虫名字;
否则可能会提示没找到该命令
其他相关命令

【2】定义Item容器

添加字段位置
先建模 //左是名字 右边是 占位符
【3】编写爬虫:

实现爬虫的python文件应该在spiders文件夹下

#def parse是回调函数,从Downloader返回response后,接受response而执行的方法;分别裁剪xx作为文件名,将网页的<body>内容保存至两个文件;
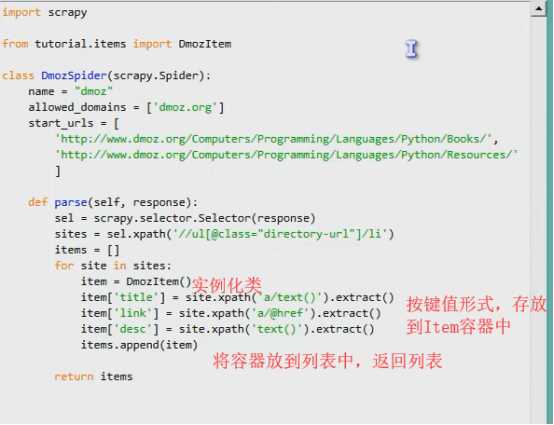
【3-1】爬“取”: ---------利用Xpath


XPath举例:

【3-2】重写spider的分析方法 【原方法是为了保存,验证用】

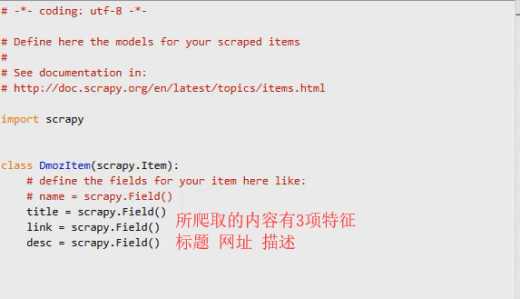
【4】将数据存放到Item容器中
【5】导出保存
scrapy crawl domz -o items.json -t json
#-o 指导出 后跟文件名字【需要后缀】
#-t 表示导出的格式,此处用json
#此处代码意思是,运行爬虫domz,并以json格式导出保存为items.json
实战中注意点:
1. 刚开始入门的时候,要爬取能爬的网站。。。有些是有反爬虫机制的,不然还会以为是代码错了导致没爬到数据
2. xpath() 中:
比如爬<html><head><title>xxx 的内容,
如果已经sites = sel.xpath(‘/html/head/title‘)
接下来用site = sites.xpath(‘text()‘).extract() 即可获取Selector对象的列表字符串化后的unicode字符串
而不是site = sites.xpath(‘/text()‘).extract() 或者 site = sites.xpath(‘title/text()‘).extract()
3.定义Item容器 中, 要和存放容器时使用的一致,不可无中生有


原文:https://www.cnblogs.com/expedition/p/10618234.html