
这两天一直在做课件,我个人一直不太喜欢PPT这个东西……能不用就不用,我个人特别崇尚极简风。
谁让我们是程序员呢,所以就爱上了Jupyter写课件,讲道理markdown也是个非常不错的写书格式啊。
安装Jupyter其实非常简单,你会python就应该会用jupyter,起码简单的 pip install jupyter, jupyter notebook 要会对伐~
好那接下来就是使用jupyter了,启动jupyter后,使用浏览器访问相应IP:Port就可以使用了。没错,jupyter就是这么一个可以用网站来写python的地方。
但是发讲义给同学们看,ipynb格式的文件肯定不方便啊,别人还没上课呢,哪知道那么多?再者PDF传阅起来也随时随地能打开啊。所以我就想转换成PDF。
但是打开文件,点击下载,发现出现了Error
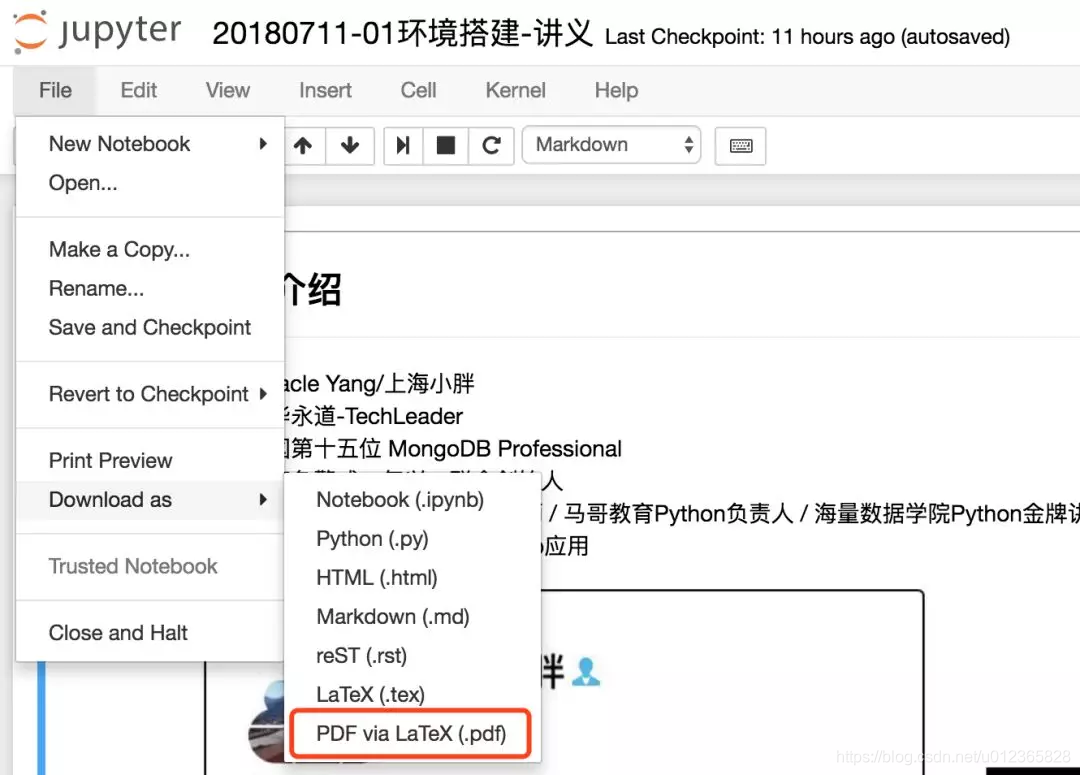

然后照着这个Error,就去谷歌了,发现说的最多的就是要装一个latex环境,mac下完整的安装包要将近3个G!我就为了一个PDF还不需要这么大一个包吧?所以寻思其他方法。
虽然jupyter对PDF支持的不是那么的友善,但是对于html是非常棒的,只不过html是一个html嘛(这不是废话)……不过我可以利用html转换到pdf上啊。
后来了解到python有一个包叫 pdfkit,专门用来转换pdf文件。那我现在只需要在mac上得到pdfkit的支持就好啦?所以接下来就是尝试的过程了。
安装pdfkit,pip install pdfkit
在这里下载对应系统的安装包 http://wkhtmltopdf.org/ ,这个只有48MB。
最后就是为什么说python是「多膜优秀」的原因了!直接看代码
‘‘‘
需要安装pdfkit, pip install pdfkit
自行下载并安装wkhtmltopdf-binary, http://wkhtmltopdf.org/
‘‘‘
import sys
import subprocess
import pdfkit
# 获得ipynb文件
inputfile = sys.argv[1].replace(" ", "\ ")
# 截取ipynb前面的名字,并保留一份html临时文件
# 这份文件会在转换过程中需要
# 因为我是利用jupyter对于html的支持,使用pdfkit对html文件进行转换
temp_html = inputfile[0:inputfile.rfind(‘.‘)]+‘.html‘
# 转换ipynb文件为html
# 调用了ipython接口
command = ‘ipython nbconvert --to html ‘ + inputfile
# shell端执行command
subprocess.call(command, shell=True)
print(‘============success===========‘)
# 拼接一个pdf名字
output_file = inputfile[0:inputfile.rfind(‘.‘)]+‘.pdf‘
# 大杀器出场,pdfkit直接将html转换成pdf
pdfkit.from_file(temp_html, output_file)
# 删除html临时文件
subprocess.call(‘rm ‘+temp_html, shell=True)操作起来也很简单:
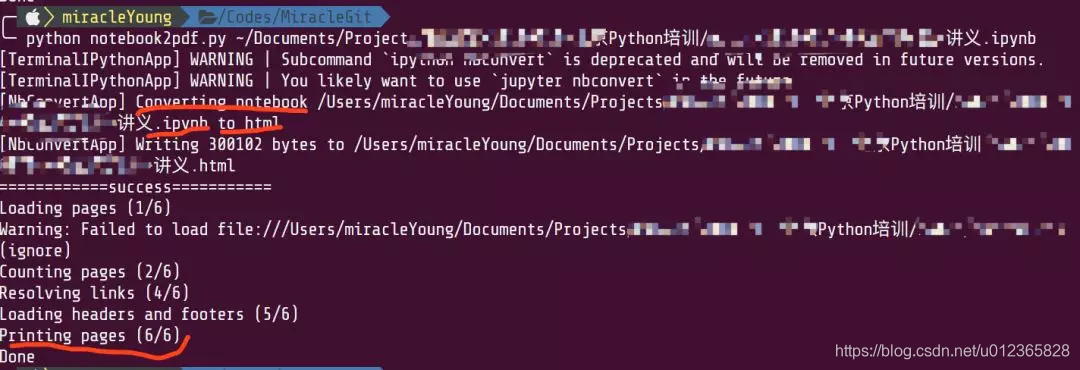
至此,ipynb文件已成功转换成pdf文件,并且颜色、格式全都保留!
关注公众号「Python专栏」,后台回复「zsxq06」,获取本文全套源码!

原文:https://www.cnblogs.com/moonhmily/p/10625174.html