一 高性能IO模型
1. 同步IO、异步IO、阻塞IO、非阻塞IO
通过IO模型介绍异步、同步、阻塞、非阻塞的IO看,本节参考文章:
https://www.cnblogs.com/euphie/p/6376508.html
这里统一使用Linux下的系统调用recv作为例子,它用于从套接字上接收一个消息,因为是一个系统调用,所以
调用时会从用户进程空间切换到内核空间运行一段时间再切换回来。默认情况下recv会等到网络数据到达并且复制到
用户进程空间或者发生错误时返回,而第4个参数flags可以让它马上返回。
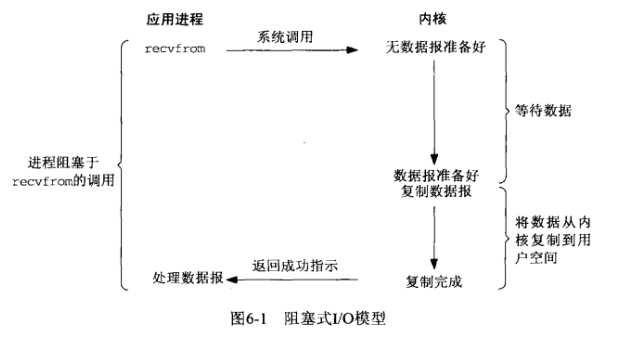
(1)阻塞IO模型
使用recv的默认参数一直等数据直到拷贝到用户空间,这段时间内进程始终阻塞。A同学用杯子装水,打开
水龙头装满水然后离开。这一过程就可以看成是使用了阻塞IO模型,因为如果水龙头没有水,他也要等到有水
并装满杯子才能离开去做别的事情。很显然,这种IO模型是同步的。
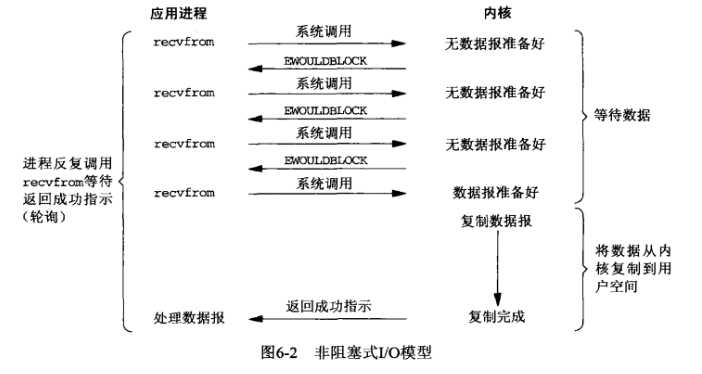
(2)非阻塞IO模型
改变flags,让recv不管有没有获取到数据都返回,如果没有数据那么一段时间后再调用recv看看,如此循
环。B同学也用杯子装水,打开水龙头后发现没有水,它离开了,过一会他又拿着杯子来看看……在中间离开的
这些时间里,B同学离开了装水现场(回到用户进程空间),可以做他自己的事情。这就是非阻塞IO模型。但是它
只有是检查无数据的时候是非阻塞的,在数据到达的时候依然要等待复制数据到用户空间(等着水将水杯装满),
因此它还是同步IO。
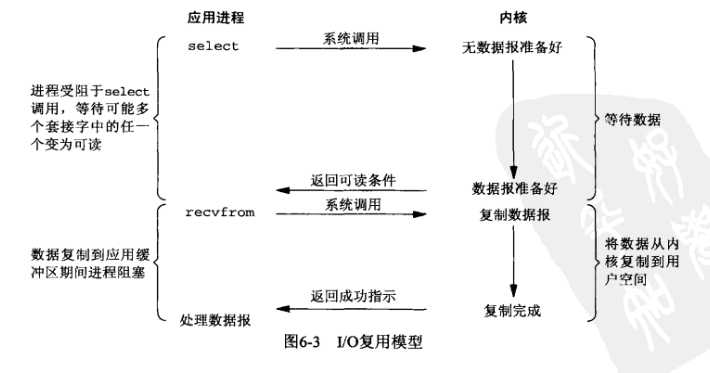
(3)IO复用模型
这里在调用recv前先调用select或者poll,这2个系统调用都可以在内核准备好数据(网络数据到达内核)时告
知用户进程,这个时候再调用recv一定是有数据的。因此这一过程中它是阻塞于select或poll,而没有阻塞于
recv,有人将非阻塞IO定义成在读写操作时没有阻塞于系统调用的IO操作(不包括数据从内核复制到用户空间时
的阻塞,因为这相对于网络IO来说确实很短暂),如果按这样理解,这种IO模型也能称之为非阻塞IO模型,但是
按POSIX来看,它也是同步IO,那么也和楼上一样称之为同步非阻塞IO吧。这种IO模型比较特别,分个段。因
为它能同时监听多个文件描述符(fd)。这个时候C同学来装水,发现有一排水龙头,舍管阿姨告诉他这些水龙头
都还没有水,等有水了告诉他。于是等啊等(select调用中),过了一会阿姨告诉他有水了,但不知道是哪个水龙
头有水,自己看吧。于是C同学一个个打开,往杯子里装水(recv)。这里再顺便说说鼎鼎大名的epoll(高性能的代
名词啊),epoll也属于IO复用模型,主要区别在于舍管阿姨会告诉C同学哪几个水龙头有水了,不需要一个个打
开看(当然还有其它区别)。
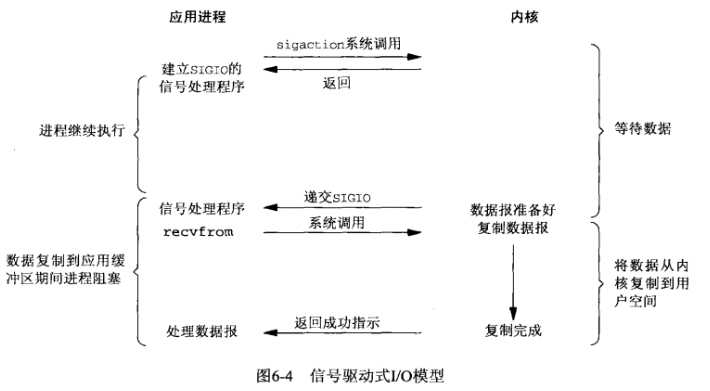
(4)信号驱动IO模型
通过调用sigaction注册信号函数,等内核数据准备好的时候系统中断当前程序,执行信号函数(在这里面调
用recv)。D同学让舍管阿姨等有水的时候通知他(注册信号函数),没多久D同学得知有水了,跑去装水。是不是
很像异步IO?很遗憾,它还是同步IO(省不了装水的时间啊)。
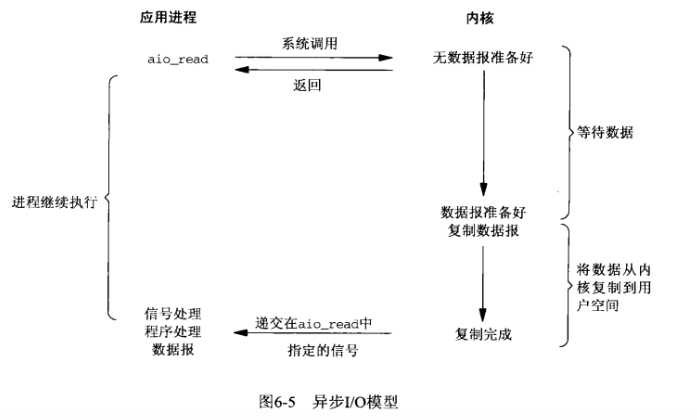
(5)异步IO模型
调用aio_read,让内核等数据准备好,并且复制到用户进程空间后执行事先指定好的函数。E同学让舍管阿
姨将杯子装满水后通知他。整个过程E同学都可以做别的事情(没有recv),这才是真正的异步IO。
2. 常见的IO模型
(1)同步阻塞IO(BIO)
同步阻塞IO模型是最简单的IO模型,用户线程在内核进行IO操作时被阻塞。
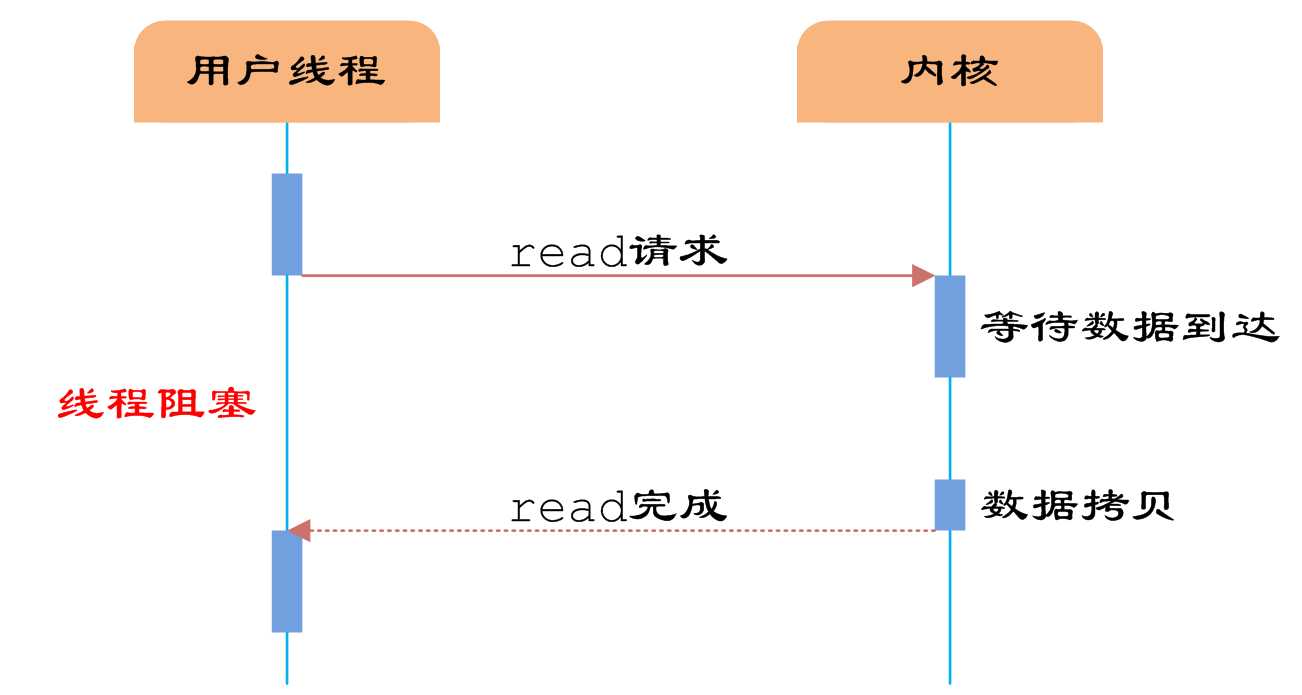
如图所示,用户线程通过系统调用read发起IO读操作,由用户空间转到内核空间。内核等到数据包到达后,
然后将接收的数据拷贝到用户空间,完成read操作。
伪代码描述:
{
read(socket, buffer);
process(buffer);
}
即用户需要等待read将socket中的数据读取到buffer后,才继续处理接收的数据。整个IO请求的过程中,用
户线程是被阻塞的,这导致用户在发起IO请求时,不能做任何事情,对CPU的资源利用率不够。
(2)同步非阻塞
同步非阻塞IO是在同步阻塞IO的基础上,将socket设置为NONBLOCK。这样做用户线程可以在发起IO请求
后可以立即返回。
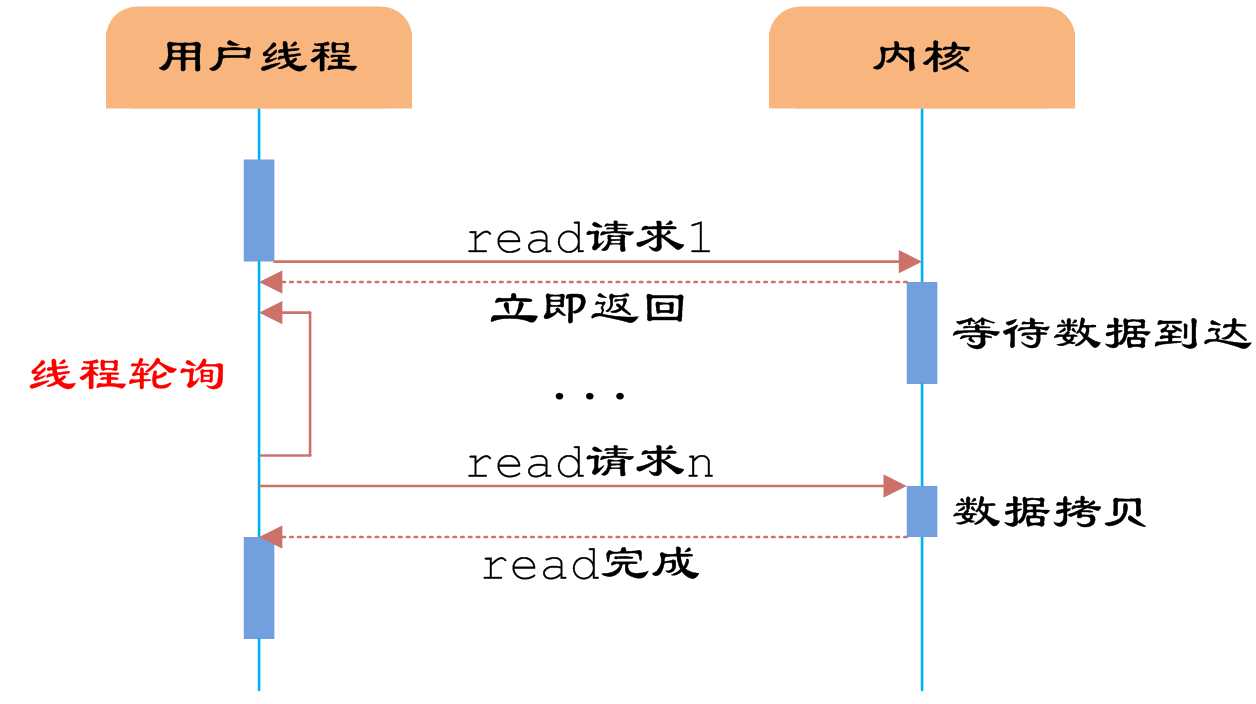
如图所示,由于socket是非阻塞的方式,因此用户线程发起IO请求时立即返回。但并未读取到任何数据,用
户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。用户线程使用同步非阻塞IO模
型的伪代码描述为:
{
while(read(socket, buffer) != SUCCESS)); process(buffer); }
即用户需要不断地调用read,尝试读取socket中的数据,直到读取成功后,才继续处理接收的数据。整个IO
请求的过程中,虽然用户线程每次发起IO请求后可以立即返回,但是为了等到数据,仍需要不断地轮询、重复请
求,消耗了大量的CPU的资源。一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
(3)IO多路复用
IO多路复用模型是建立在内核提供的多路分离函数select、poll、epoll(这个比价好)基础之上的,使用
select函数可以避免同步非阻塞IO模型中轮询等待的问题。
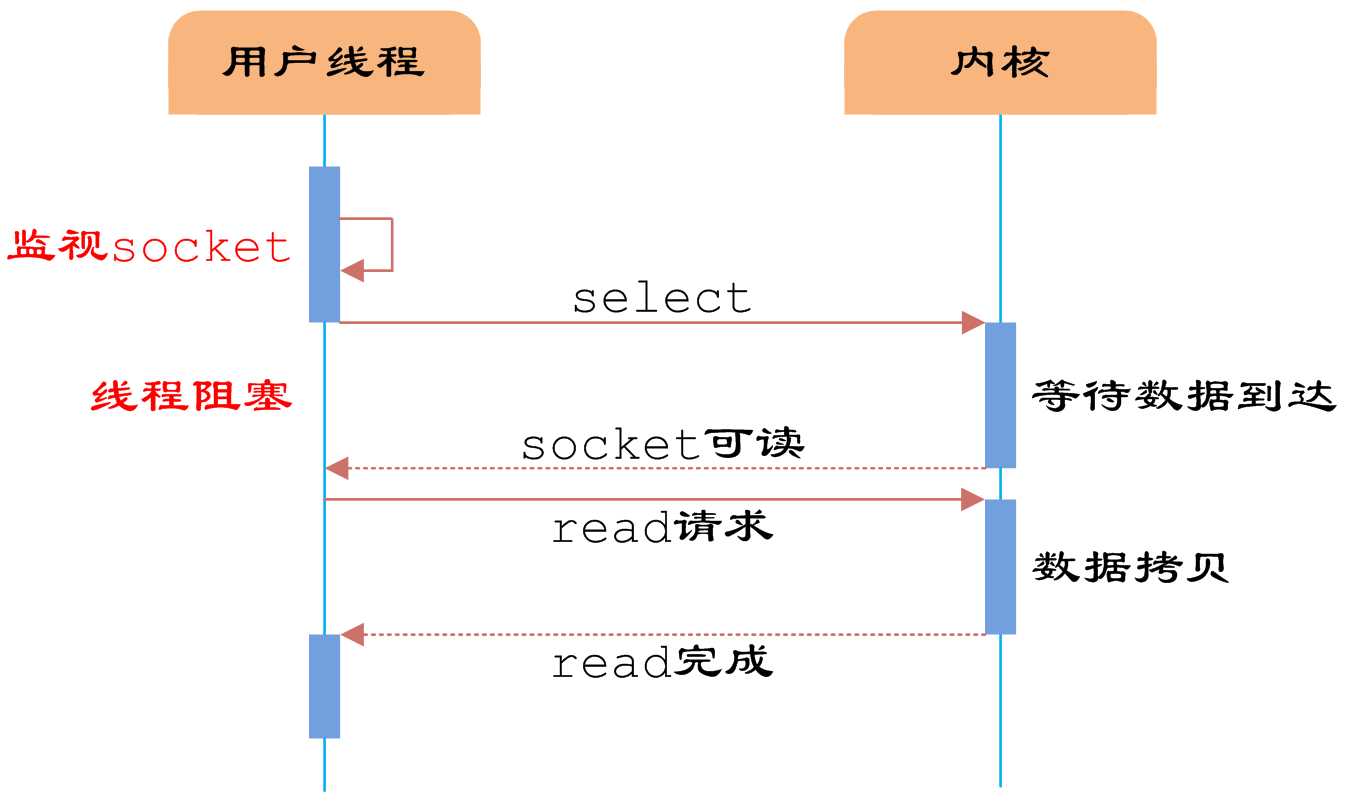
如图所示,用户首先将需要进行IO操作的socket添加到select中,然后阻塞等待select系统调用返回。当数
据到达时,socket被激活,select函数返回。用户线程正式发起read请求,读取数据并继续执行。从流程上来看,
使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视socket,以及调用select函数
的额外操作,效率更差。但是,使用select以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请
求。用户可以注册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程内同时处理
多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达到这个目的。
{ select(socket); while(1) { sockets = select(); for(socket in sockets) {
if(can_read(socket)) { read(socket, buffer); process(buffer); } } } }
其中while循环前将socket添加到select监视中,然后在while内一直调用select获取被激活的socket,一旦
socket可读,便调用read函数将socket中的数据读取出来。
然而,使用select函数的优点并不仅限于此。虽然上述方式允许单线程内处理多个IO请求,但是每个IO请
求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只注册
自己感兴趣的socket或者IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用
率。
原文:https://www.cnblogs.com/jialanshun/p/10628371.html