Robots协议(也称为爬虫协议、爬虫规则、机器人协议等)也就是robots.txt,网站通过robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
Robots协议是网站国际互联网界通行的道德规范,其目的是保护网站数据和敏感信息、确保用户个人信息和隐私不被侵犯。因其不是命令,故需要搜索引擎自觉遵守。
requests, urllib
http协议是超文本传输协议,被用于在web浏览器和网站服务器之间传递信息。http协议工作是以明文方式发送内容,不提供任何形式的数据加密,而这也是很容易被黑客利用的地方,如果黑客截取了web浏览器和网站服务器之间的传输信息,就可以直接读懂其中的信息,因此http协议不适合传输一些重要的、敏感的信息,比如信用卡密码及支付验证码等。
安全套接字层https协议就是为了解决http协议的这一安全缺陷而出生的,为了数据传输的安全,https在http的基础上加入了ssl协议,ssl依靠证书来验证服务器的身份,为浏览器和服务器之间的通信加密,这样的话即使黑客截取了发送过程中的信息,也无法破解读懂它,我们网站及用户的信息便得到了最大的安全保障。
通过headers反爬虫;
基于用户行为的发爬虫:同一IP短时间内访问的频率;
动态网页反爬虫(通过ajax请求数据,或者通过JavaScript生成);
验证码
数据加密
解决途径:
对于基本网页的抓取可以自定义headers,将header随request一起发送(一般是User-Agent,Cookie)
使用IP代理池爬取或者降低抓取频率
使用selenium + phantomjs 进行抓取抓取动态数据,或者找到动态数据加载的json页面
使用打码平台识别验证码
对部分数据进行加密的,可以使用selenium进行截图,使用python自带的pytesseract库进行识别,但是比较慢最直接的方法是找到加密的方法进行逆向推理。
GET数据传输安全性低,POST传输数据安全性高,因为参数不会被保存在浏览器历史或web服务器日志中;
在做数据查询时,建议用GET方式;而在做数据添加、修改或删除时,建议用POST方式;
GET在url中传递数据,数据信息放在请求头中;而POST请求信息放在请求体中进行传递数据;
GET传输数据的数据量较小,只能在请求头中发送数据,而POST传输数据信息比较大,一般不受限制;
在执行效率来说,GET比POST好
网站的反爬虫策略会检测到同一个IP访问次数频率过快,从而禁止该IP的访问。因此爬虫过程中需要IP代理避免该问题。
re.S为单行解析,解析的源码数据中可以有换行符,re.S会作用到整个被视为一个大字符串的页面源码数据中。re.M为多行解析,会将正则作用到源码的每一行中。在实战中使用的是re.S。
可以在浏览器中直接校验xpath表达式,校验成功后再将xpath作用到程序中。
//div[@class=‘xxx’] # 属性定位
//div[@id=’xxx’]/a[2]/span # 层级索引定位
//a[@href=’’and @class=’xxx’] # 逻辑运算
//div[contains(@class,’xx’)] # 模糊匹配
//div[starts-with(@class,’xx’)] # 模糊匹配
/div/text() or /div//text() # 取文本
/@属性 # 取属性find() # 找到第一个符合要求的标签
find_all() # 找到所有符合要求的标签
select() # 根据选择器找到符合要求的标签
div a ul li # 多层级选择器
div>a>ul>li # 单层层级选择器对携带验证码的页面数据进行抓取
将页面中的验证码进行解析, 将验证码图片下载到本地
将验证码图片提交给打码平台进行识别, 返回识别后的结果
云打码平台使用:
在官网中进行普通用户和开发者用户注册
登录开发者用户:
a) 示例代码下载:开发文档 --> 调用示例及最新DLL --> PythonHTTP示例下载
b) 创建一个软件:我的软件 --> 添加新的软件(后期会使用该软件的秘钥和id)
使用示例代码中的示例代码对保存本地的验证码进行识别
博客地址:https://www.cnblogs.com/bobo-zhang/p/10068994.html
# 详情步骤请查看视频:
链接:https://pan.baidu.com/s/1BiNd3IPA44xGszN9n93_hQ
提取码:6slk 端口号和允许抓取其他机器上的数据包的设置
https数据包抓取的设置
保证手机和fiddler所在的机器处在同一网段下
下载安全证书,且安装到手机上。在手机浏览器中录入fiddler机器的ip和fiddler的端口号进行证书的下载。
下载成功后进行证书的安装
详细步骤请参考 博客
将手机的网络和端口号设置成fiddler电脑的ip和fiddler的端口号
scrapy crawl 爬虫名称 -o xxx.json
scrapy crawl 爬虫名称 -o xxx.xml
scrapy crawl 爬虫名称 -o xxx.csv1. 将爬取到的数据封装在item对象中
2. 使用yield将item提交给管道
3. 在管道文件中的process_item方法中,将item中的数据进行持久化存储操作面试题:如果最终需要将爬取到的数据值一份存储到磁盘文件,一份存储到数据库中,则应该如何操作scrapy?
#该类为管道类,该类中的process_item方法是用来实现持久化存储操作的。
class DoublekillPipeline(object):
def process_item(self, item, spider):
#持久化操作代码 (方式1:写入磁盘文件)
return item
#如果想实现另一种形式的持久化操作,则可以再定制一个管道类:
class DoublekillPipeline_db(object):
def process_item(self, item, spider):
#持久化操作代码 (方式1:写入数据库)
return item
"""
需要注意的是, 在pipelines.py文件中, 如果pipeline要把该数据存储到不同的数据库, 就需要在pipelines.py文件中创建多个类, item会在每一个类中的process_item方法中进行传递(通过process_item方法中的return item), 因此除了最后一个类的process_item方法可以不return item外, 其余的类都必须return item
"""#下列结构为字典,字典中的键值表示的是即将被启用执行的管道文件和其执行的优先级。
ITEM_PIPELINES = {
'doublekill.pipelines.DoublekillPipeline': 300,
'doublekill.pipelines.DoublekillPipeline_db': 200,
}
"""
上述代码中,字典中的两组键值分别表示会执行管道文件中对应的两个管道类中的process_item方法,实现两种不同形式的持久化操作。
"""yield scrapy.Request(url,callback)
# 参数说明:
url: 请求的url
callback: 指定方法对请求到的页面进行解析操作重写父类的start_request方法,该方法会被调度器默认调用,在该方法中可以通过yield scrapy.FormRequest(url,callback,formdata)进行post请求发送。
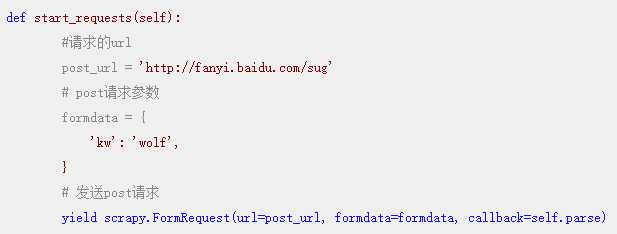
当需求中需要解析的数据值不在同一个页面中时, 必须用请求传参进行处理.
实现方式:yield scrapy.Request(url,callback,meta), 使用meta参数可以将item对象传递给callback指定的回调方法中. meta为字典类型.
博客地址: https://www.cnblogs.com/bobo-zhang/p/10013011.html
博客地址: https://www.cnblogs.com/bobo-zhang/p/10013045.html
当引擎将国内板块url对应的请求提交给下载器后, 下载器进行网页数据的下载, 然后将下载到的页面数据封装到response中, 提交给引擎, 引擎将response再转交给Spiders. Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的, 要想获取动态加载的新闻数据, 则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截, 且对其内部存储的页面数据进行篡改, 修改成携带了动态加载出的新闻数据, 然后将被篡改的response对象最终交给Spiders进行解析操作.
重写爬虫文件的构造方法, 在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次, 所以选择把它写在构造方法__init__中)
重写爬虫文件的closed(self, spider)方法, 在其内部关闭浏览器对象. 该方法是在爬虫结束时被调用的.
重写下载中间件的process_response方法, 让该方法对响应对象进行拦截, 并篡改response中存储的页面数据.
在配置文件中开启 下载中间件.
from scrapy_redis.spiders import RedisCrawlSpider将爬虫类的父类修改成RedisCrawlSpider
将起始url列表注释, 添加一个redis_key(调度器队列的名称)的属性
redisxxx.conf进行配置:
# bind 127.0.0.1protected-mode no对项目中settings进行配置
a) 配置redis服务器的ip和端口号:
REDIS_HOST = 'redis服务的ip地址'
REDIS_PORT = 6379
# REDIS_PARAMS = {‘password’:’123456’}b) 配置使用scrapy-redis组件中的调度器:
# 使用scrapy-redis组件的去重队列
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 是否允许暂停
SCHEDULER_PERSIST = Truec) 配置使用scrapy-redis组件中的管道:
ITEM_PIPELINES = {
#'wangyiPro.pipelines.WangyiproPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 400,
}d) 开启redis数据库的服务: redis-server 配置文件
e) 执行爬虫文件: scrapy runspider wangyi.py
f) 向调度器的队列中扔一个起始url:
- i. 开启redis客户端
- ii. lpush 爬虫文件名称 起始url1. 使用性能更好的机器
2. 使用光纤网络
3. 多进程
4. 多线程
5. 分布式基于requests模块的多线程爬取建议大家使用`multiprocessing.dummy.pool线程池, 爬取效率会显著提升.
代码展示:
import requests
from bs4 import Beautiful
#导入线程池
from multiprocessing.dummy import Pool
pool = Pool()#实例化线程池对象
#发起首页请求
page_text = requests.get(url='xxx')
#使用bs4解析首页中所有的a标签
soup = Beautiful(page_text)
a_list = soup.select('a')
#将a标签的href属性值和域名拼接,形成完整的url
url_list = ['www.xxx.com/'+url['href'] for url in a_list]
#封装请求函数,该函数可以获取请求对应的页面数据
request_page_text = lambda link:requests.get(link).text
#使用线程池的map方法异步进行请求发送,切获取响应回来的页面数据
page_text_list = pool.map(request_page_text, url_list)
#使用线程池异步进行解析操作
get_data = lambda data:parse(data)
pool.map(get_data, page_text_list)
#数据解析方法
def parse(data):
????pass默认scrapy开启的并发线程为32个, 可以适当进行增加. 在settings配置文件中修改`CONCURRENT_REQUESTS = 100值为100, 并发设置成了为100.
在运行scrapy时, 会有大量日志信息的输出, 为了减少CPU的使用率. 可以设置log输出信息为INFO或者ERROR. 在配置文件中编写: LOG_LEVEL = ‘INFO’
如果不是真的需要cookie, 则在scrapy爬取数据时可以进制cookie从而减少CPU的使用率, 提升爬取效率. 在配置文件中编写: COOKIES_ENABLED = False.
对失败的HTTP进行重新请求(重试)会减慢爬取速度, 因此可以禁止重试. 在配置文件中编写: RETRY_ENABLED = False
如果对一个非常慢的链接进行爬取, 减少下载超时可以能让卡住的链接快速被放弃, 从而提升效率. 在配置文件中进行编写: DOWNLOAD_TIMEOUT = 10 超时时间为10s.
i. 全国代理IP网:
ii. 西祠代理网:

iii. 快代理网:

(1)项目名称: 潮流穿衣搭配数据采集
(2)项目描述:
本项目采用scrapy框架对爱搭配网和穿衣打扮网等网站导航页下所有大类、小类中的相关子链接, 以及链接页面的相关内容进行爬取, 将数据写入数据库, 提供给公司做参考数据.
(3)责任描述:
a. 负责信息数据的爬取
b. 负责分析数据爬取的过程
c. 负责分析网站的反爬技术, 并提供反反爬策略
d. 采用线程池进行数据爬取, 采集了13w条数据
e. 负责将采集到的数据进行数据分析整理
(1)项目描述:
本项目采用基于RedisCrawlSpider的分布式爬虫, 对网易新闻、头条、新浪新闻等网站进行大类板块下新闻资讯数据的爬取, 将爬取到的数据调用百度AI接口进行关键字提取和文章分类检索. 设计库表进行数据存储.
(2)责任描述:
a. 搭建5台分布式机群进行新闻数据爬取
b. 分析数据爬取过程, 设计反反爬策略
c. 将分布爬取到的近30w条数据进行数据清洗和异常值过滤
d. 调用百度AI对新闻数据进行关键字提取和文章分类
原文:https://www.cnblogs.com/haitaoli/p/10631692.html