给定一篇新闻的链接newsUrl,获取该新闻的全部信息
标题、作者、发布单位、审核、来源
发布时间:转换成datetime类型
点击:
整个过程包装成一个简单清晰的函数。
尝试去爬取一个你感兴趣的网页。
import requests from bs4 import BeautifulSoup from datetime import datetime import re if __name__ == ‘__main__‘:#"https://www.bilibili.com/read/cv1119650?from=search" def bzNews(url): #url不合法会崩掉 res=requests.get(url) type(res) res.encoding="utf-8" soup1=BeautifulSoup(res.text,‘html.parser‘) #此网页发布时间处理 dateTime = soup1.find(‘meta‘,{‘itemprop‘:‘datePublished‘}) type(dateTime) dateTime = str(dateTime) #分隔时间格式 DT = re.findall("(\d{4}-\d{1,2}-\d{1,2}\s\d{1,2}:\d{1,2}:\d{1,2})",dateTime) #作者名称 au=soup1.select(‘.author-name‘)[0].text #标题 title=soup1.select(‘.title‘)[2].text time = DT #处理时间 pubtime= datetime.strptime(time[0],‘%Y-%m-%d %H:%M:%S‘) pubtime = pubtime.strftime(‘%Y{y}%m{m}%d{d} %U{a}%w %H{h}%M{f}%S{s}%p‘).format(y=‘年‘,m=‘月‘,d=‘日‘,h=‘时‘,f=‘分‘,s=‘秒‘,a=‘周 星期‘) print(" 作者:",au,‘\n‘,"标题:",title,‘\n‘,"发布时间:",pubtime,‘\n‘) def main(): while(1): url =input("输入哔哩哔哩的新闻网址:") bzNews(url) ending =int(input("输入0退出")) if(ending==0):break main()
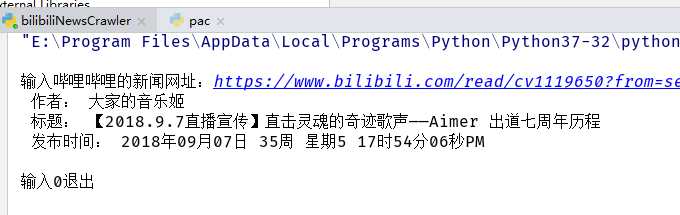
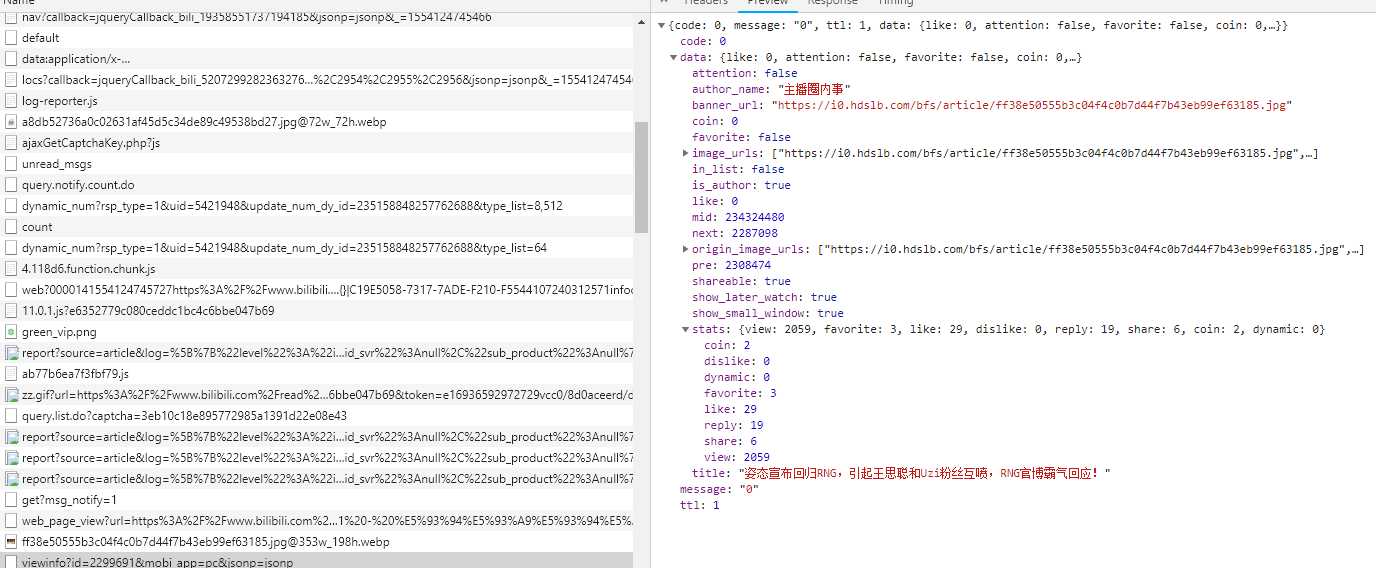
另外通过查看network发现在一个viewinfo的requests对象中有存放点赞,观看数的json数据,下次再做解析json数据
原文:https://www.cnblogs.com/FreyjaFs/p/10639224.html