2pc解决的是分布式事务问题。
2pc分为提交事务请求阶段和执行事务提交。
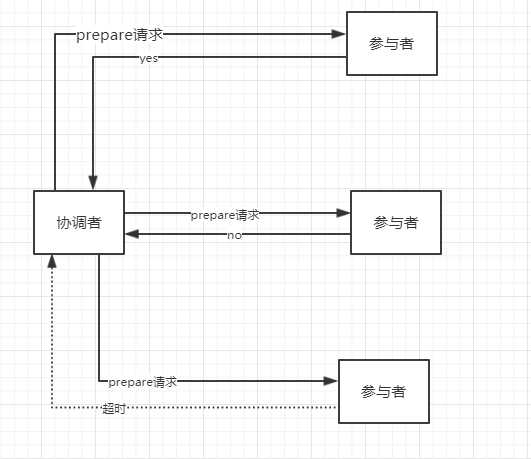
1.1 协调者向所有参与者发送事务内容,询问是否可以执行事务提交操作,等待响应或超时
1.2 各参与者执行事务操作,写入undo和redo日志
1.3 参与者返回响应
2.1 事务提交
如果阶段一参与者返回的都是yes响应,则执行事务提交
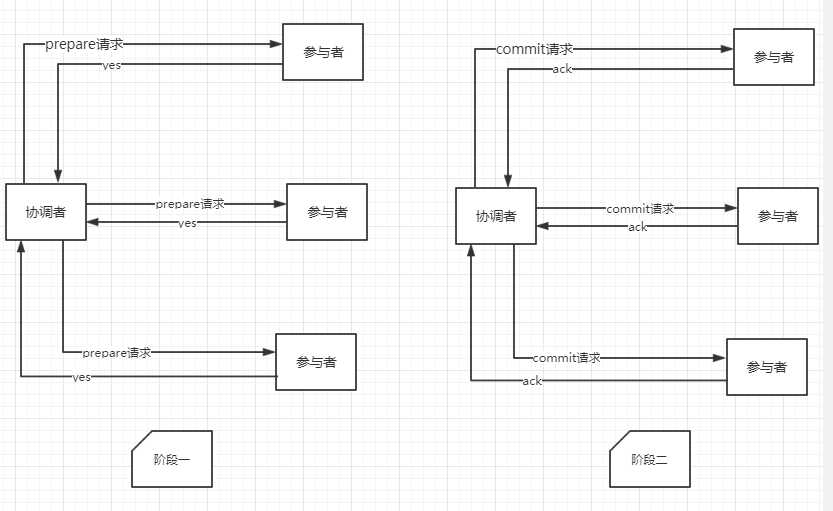
2.1.1 协调者发送事务提交请求
2.1.2 参与者执行commit操作
2.1.3 参与者返回ack消息
2.1.4 协调者接收到ack消息,事务完成
2.2 中断事务
如果阶段一任一参与者返回no响应,或协调者在等待参与者响应超时,将中断事务
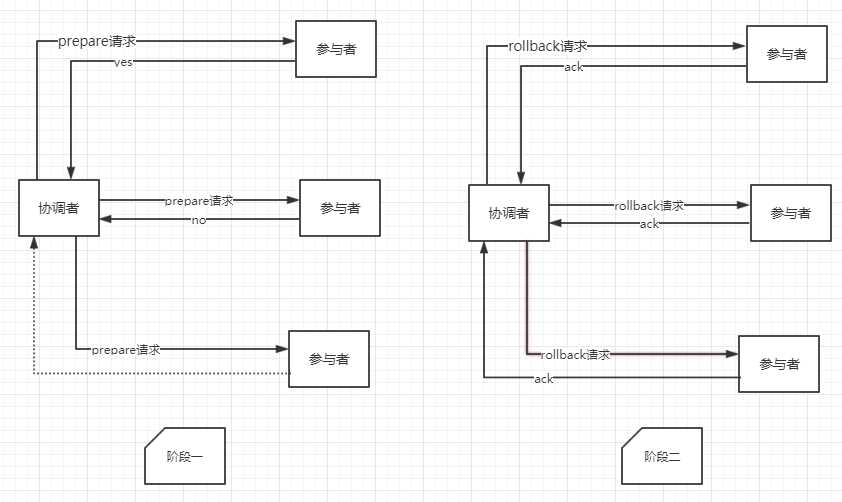
2.2.1 协调者发送rollback请求
2.2.2 参与者利用1.2的undo日志执行rollback
2.2.3 参与者返回ack
2.2.4 协调者接收到ack,完成事务中断
3pc是2pc的改进版,将2pc的阶段一提交事务请求一分为二,形成canCommnit、preCommit、doCommit。
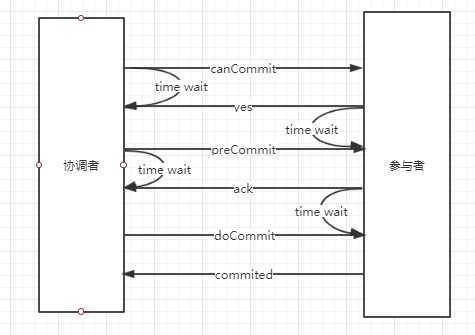
1.1 协调者向参与者发送事务内容,询问是否可以执行,等待响应
1.2 参与者判断是否可以执行,反馈yes或no
如果协调者收到的都是yes响应,则执行事务预提交。
2.1 协调者发送preCommit请求
2.2 参与者执行事务操作,写入undo和redo日志
2.3 参与者反馈ack,等待doCommit请求
如果任一参与者返回no,或者协调者等待超时,则向所有参与者发送中断事务请求;如果一个参与者在等待协调者preCommit超时,将中断事务。
协调者接收到所有ack请求,则执行提交
3.1 协调者发送doCommit请求
3.2 参与执行事务提交,反馈ack
3.3 完成事务
如果任一参与者返回no,或者协调者等待超时,则向所有参与者发送rollback请求;如果一个参与者在等待协调者doCommit超时,将自动执行commit操作。
3pc相对于2pc,在参与者引入了超时操作,减少了阻塞同时解决的单点问题。
但3pc也存在数据不一致问题,在阶段三,参与者在等待doCommit时,协调者给部分参与者发送了rollBack请求,随后故障,那么剩下的参与者将自动commit。
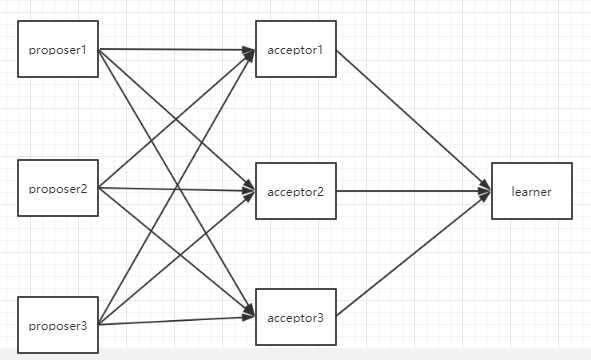
paxos是一种基于消息传递且具有高度容错特性的一致性算法,且是目前公认的解决分布式一致性问题最有效的算法之一。
paxos解决的是如何在集群内部对某个数据的值达成一致。
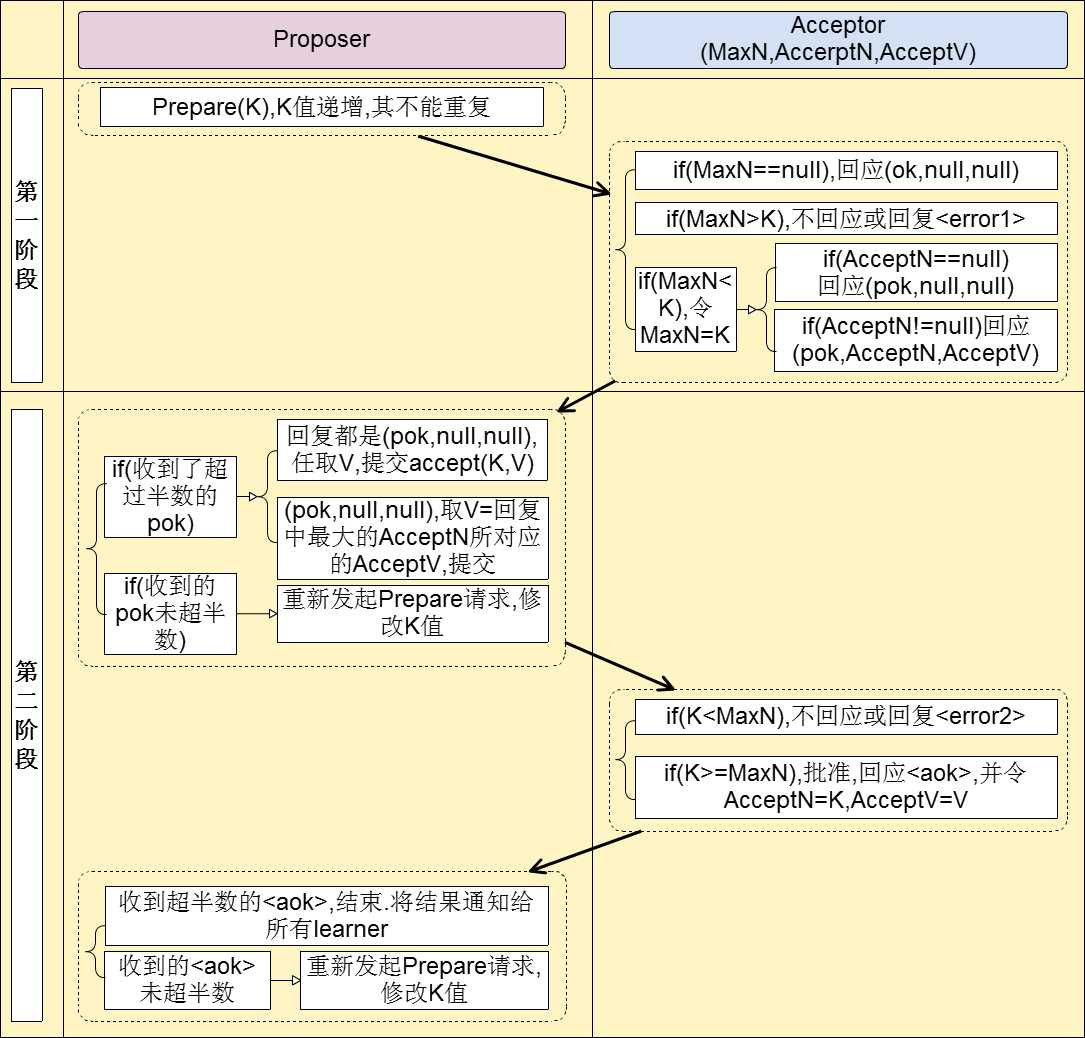
阶段一:
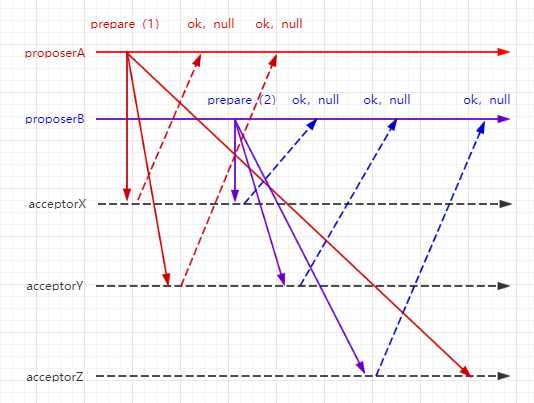
proposerA向acceptor发送prepare(1)的请求,acceptorX和acceptorY接收并返回ok,同时承诺不接受小于1的请求;
这时proposerB向acceptor发送prepare(2)的请求,acceptorX/Y/Z都接收并返回ok,同时承诺不接受小于2的请求;
到这时proposerA的prepare(1)才到达acceptorZ,但acceptorZ已经不接收小于2的请求,于是抛弃请求。
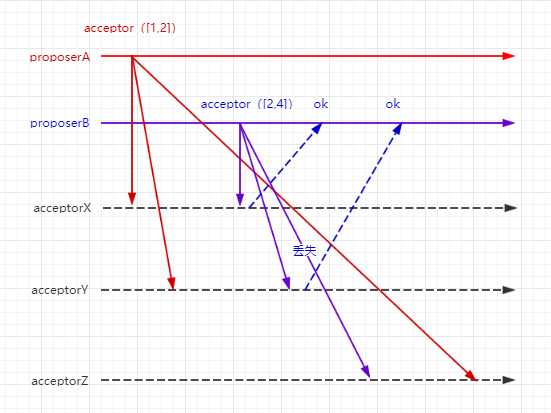
proposerA接收到acceptorX/Y的响应超过一半,但提案为null,于是发送acceptor([1,2])的请求给acceptor,但acceptor已经不接收小于2的请求,于是抛弃;
proposerB同样发送acceptor([2,4])的请求,acceptorX/Y接收并批准该提案,acceptorZ由于各种原因没有接收到,但批准已超过一半,于是提案成立。
如果acceptorA和acceptorB依次请求prepare,那就陷入死循环。
为了避免以上主循环,必须选取一个主proposer,规定只有主proposer才能提出提案。
主proposer的选举可以用paxos,上述问题用失败休眠随机时间减少冲突。
从Paxos到Zookeeper 分布式一致性原理与实践
https://angus.nyc/2012/paxos-by-example/
https://www.cnblogs.com/hugb/p/8955505.html
原文:https://www.cnblogs.com/wuweishuo/p/10640015.html