在之前的学习中,我们执行sql语句,需要频繁的开流,关流比较麻烦,为了更加的简化代码,我们使用Spring 的jdbc模板jdbcTemplate来简化我们的代码量;需要导入的包有:
我们在之前的druid连接池的基础上来使用该模板:
在这里先介绍一个Spring 的Test类;我们可以用它来完成代码的测试,不需要建立main方法来调用方法,直接测试;具体如下:
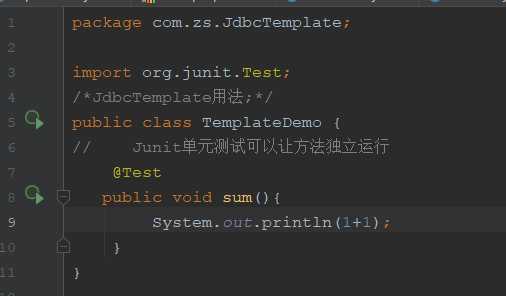 注意:导入junit.Test包,输入@Test报红字,然后alt+enter键导入Jutil包;
注意:导入junit.Test包,输入@Test报红字,然后alt+enter键导入Jutil包;
可以发现在方法左边有运行图标,可以直接运行方法,不需要通过main方法;在jdbc模板中我们的不需要关其他的流,所以之前的连接池工具类我们需要做一下修改,添加一个获得连接池对象的方法;
package JDBCUtils; import com.alibaba.druid.pool.DruidDataSourceFactory; import javax.sql.DataSource; import java.io.InputStream; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; import java.sql.SQLException; import java.util.Properties; /*Druid连接池工具类*/ public class JDBCUtils { private static DataSource ds; // 静态代码块获取配置文件内容 static{ Properties p = new Properties(); InputStream in = JDBCUtils.class.getClassLoader().getResourceAsStream("druid.properties"); try { p.load(in); ds = DruidDataSourceFactory.createDataSource(p); } catch (Exception e) { e.printStackTrace(); } } // 创建获得连接对象方法 public static Connection getConnection() throws SQLException { return ds.getConnection(); } // 创建关闭方法 关闭方法中的conn.close()是归还连接对象给连接池,并不是释放资源 public static void close(Connection conn, PreparedStatement pre){ if (pre!=null) { try { pre.close(); } catch (SQLException e) { e.printStackTrace(); } } if (conn!=null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } // 重载关闭方法 public static void close(Connection conn, PreparedStatement pre, ResultSet rs) { if (rs != null) { try { rs.close(); } catch (SQLException e) { e.printStackTrace(); } } if (pre != null) { try { pre.close(); } catch (SQLException e) { e.printStackTrace(); } } if (conn != null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } // 重载关闭方法 public static void close(Connection conn){ if (conn != null) { try { conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } // 创建获得连接池方法 public static DataSource getDateSource(){ return ds; } }
jdbc模板使用:
package com.zs.JdbcTemplate; import JDBCUtils.JDBCUtils; import org.junit.Test; import org.springframework.jdbc.core.JdbcTemplate; import java.util.List; import java.util.Map; /*JdbcTemplate用法;*/ public class TemplateDemo { JdbcTemplate jt=new JdbcTemplate(JDBCUtils.getDateSource()); // Junit单元测试可以让方法独立运行 // 插入数据方法 @Test public void insert(){ String sql="insert into login value(?,?,?);"; int i = jt.update(sql, 3, "泰罗", "12345"); System.out.println(i); } // 修改数据方法 @Test public void update(){ String sql="update login set sname = ? where id = ? ;"; int i = jt.update(sql, "赛文", 1); System.out.println(i); } // 查询方法 @Test public void select(){ String sql = "select * from login;"; // 执行查询语句将结果放入集合中,默认每一个结果用map集合来保存,用列名来做键 List<Map<String, Object>> maps = jt.queryForList(sql); for (Map<String, Object> map : maps) { System.out.println(map); } } }
在之前我们将结果集封装到对象中,结果赋值语句需要先rs.getObject(),再将结果通过set方法赋值给对象,比较繁琐,在这里也有讲结果集赋值给对象的,我们先建对象类:
package com.zs.JdbcTemplate; import java.util.Date; public class Emp { // 在创建对象的类中,为了防止赋值时出现数据不匹配的情况,尽量都使用引用类型,要注意与表数据类型一致 private Integer id; private String ename; private Integer job_id; private Integer mgr; private Date joindate; private Double salary; private Double bonus; private Integer dept_id; public Integer getId() { return id; } public void setId(Integer id) { this.id = id; } public String getEname() { return ename; } public void setEname(String ename) { this.ename = ename; } public Integer getJob_id() { return job_id; } public void setJob_id(Integer job_id) { this.job_id = job_id; } public Integer getMgr() { return mgr; } public void setMgr(Integer mgr) { this.mgr = mgr; } public Date getJoindate() { return joindate; } public void setJoindate(Date joindate) { this.joindate = joindate; } public Double getSalary() { return salary; } public void setSalary(Double salary) { this.salary = salary; } public Double getBonus() { return bonus; } public void setBonus(Double bonus) { this.bonus = bonus; } public Integer getDept_id() { return dept_id; } public void setDept_id(Integer dept_id) { this.dept_id = dept_id; } @Override public String toString() { return "Emp{" + "id=" + id + ", ename=‘" + ename + ‘\‘‘ + ", job_id=" + job_id + ", mgr=" + mgr + ", joindate=" + joindate + ", salary=" + salary + ", bonus=" + bonus + ", dept_id=" + dept_id + ‘}‘; } }
将查询结果放入对象,再将对象放入集合:
package com.zs.JdbcTemplate; import JDBCUtils.JDBCUtils; import org.junit.Test; import org.springframework.jdbc.core.BeanPropertyRowMapper; import org.springframework.jdbc.core.JdbcTemplate; import java.util.List; import java.util.Map; /*JdbcTemplate用法;*/ public class TemplateDemo { JdbcTemplate jt=new JdbcTemplate(JDBCUtils.getDateSource());// 将结果放入对象中,将对象放入集合中 @Test public void select1(){ String sql = "select * from emp;"; List<Emp> rs = jt.query(sql, new BeanPropertyRowMapper<Emp>(Emp.class)); for (Emp r : rs) { System.out.println(r); } } }
可以发现,不仅代码量少了,而且也不需要频繁开关流了
原文:https://www.cnblogs.com/Zs-book1/p/10651079.html