先安装好jieba库
下载好你需要的txt文件

(注:文件必须改为utf-8编码)
import jieba
txt = open(r‘D:\\三国演义 (2).txt‘, "r", encoding=‘utf-8‘).read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1: #排除单个字符的分词结果
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
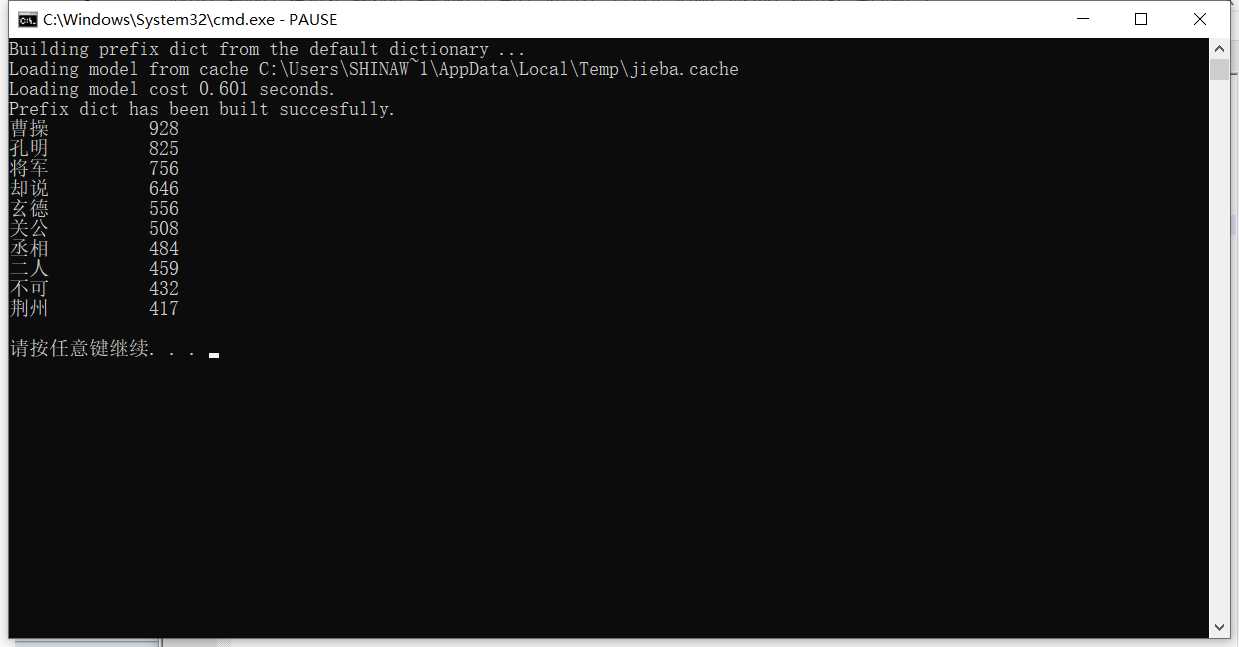
for i in range(10):
word, count = items[i]
print ("{0:<10}{1:>5}".format(word, count))
原文:https://www.cnblogs.com/shinawear/p/10652400.html