等同于xgboost是个准曲率很高的集成学习框架,在很多比赛中成绩优异。
大多数的集成学习都使用决策树作为基分类器,主要是因为本身要训练多个分类器,而决策树速度很快,总体时间相对较少。
决策树
在讲xgboost之前,先描述一下决策树,后面要用到这些符号
决策树是把输入x映射到一个叶节点中,这个过程我们记为q(x)
叶节点总数记为T,每个叶节点有个标签(分类)或者预测值(回归)w,即W=[w1,w2,...wT]
那么决策过程就是 f(x)=W[q(x)],记为wq(x)
决策树的复杂度
决策树很容易过拟合,过拟合是因为树太深,模型过于复杂,限制过拟合主要是避免树太深,可以限制叶节点的个数不能太多,也可以限制叶节点中样本数不能太少,当然还有很多方法,
这里我们提出一个概念叫树的复杂度,可以用叶节点的个数T和叶节点的标签w来衡量,标签w可以理解为节点中样本较多,取平均会比较平滑,类似于 batch,
当然也可以用其他方式来衡量
xgboost通俗理解
本文以xgboost回归为例进行讲解
单个决策树很难保障准确率,假设单个决策树预测为y’,真实值为y,于是产生了一个误差y-y‘,
xgboost针对这个误差又建立了一棵决策树,分析误差产生的原因,从而弥补这个误差,新的决策树又会产生一个误差,那么继续建立一棵决策树,如此迭代下去,这就是xgboost的大致过程。
这个过程好比我们写代码,先大致写个框架,运行一下,看看哪不对,改一下,再运行一下,看看哪不对,再改一下,如此迭代,直至完全正确。
注意我们写代码时很少一下从头写到尾,因为这样很不方便调试,如果错误太多,还不如重新写,
对应到决策树就是树太深,过拟合,可能需要重新训练,所以xgboost每一棵树不能太深,这个例子不太合适,只是帮助理解
假设决策树的预测为y‘,真实值为y,我们把误差记为 l(y, y‘),为了约束决策树的复杂度,xgboost加上了正则项,我们用 Ω(f) 来表示,f代表决策树
xgboost需要建立多棵决策树,假设y‘初始值为0,即瞎猜,没有任何预测时为0,那么整个过程如下
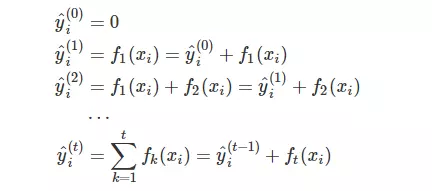
i表示样本,t表示第几棵树,yt表示前t棵树的预测值,ft(x)表示新建的第t棵树的预测值,
最终的预测值就是
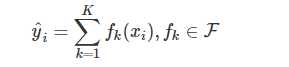
k表示决策树的个数。
建树原则
那么问题来了,如何建树?
普通的决策树是利用信息增益、信息增益率或者基尼系数来建树,那么xgboost建树的指标是什么呢?
树的损失函数
之前说决策树有个损失函数
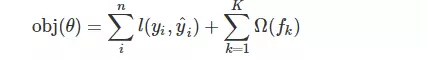
n表示样本数
根据经验,我们需要使得损失函数最小,这就是建树的原则。
那么怎么最小化损失函数呢?正常我们都会有个线性变换、激活函数,这里是一棵树,怎么办呢? 可能一时半会真想不到,先把公式变换一下吧
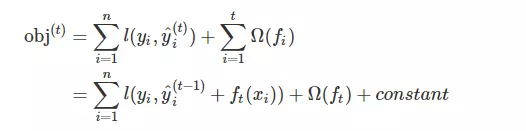
这个 constant 就是前t-1棵树的复杂度,Ω (ft)是第t棵树的复杂度。
假设l损失为均方差,上式变为
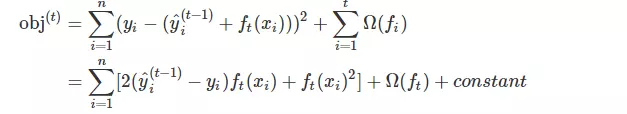
这里重新回忆一下,xgboost是一棵树一棵树的建立,也就是说在建立第t棵树时,第t-1棵树的预测值是已知的,也就是上式中 y, yt-1是已知的,故其运算值是常数,所以上式是这样的
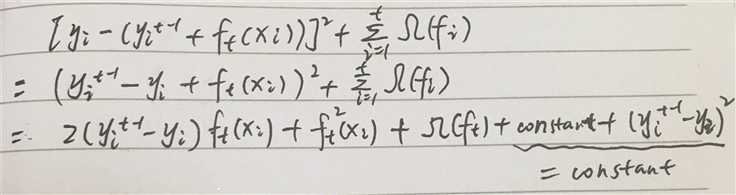
注意xgboost有个特点就是允许自定义损失函数,那么如果我们定义的损失函数不是均方差,那是不是得重新研究一下算法呢? 是的,确实要重新研究,但是xgboost为了避免这种麻烦,采用了损失函数的二阶近似
二阶Taylor展开
这里简单介绍下
泰勒级数:把非线性函数f(x)=0在x0处展开成泰勒级数,注意x0是个已知数
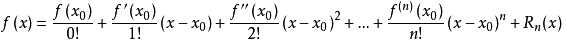
然后取前3项作为近似值。
损失函数 l(y,yt-1+ft(x)) 是关于 yt-1+ ft(x) 的方程,yt-1+ ft(x)对应为泰勒展开中的x,yt-1是常数,对应为泰勒展开中的x0
所以损失函数 l(y,yt-1+ft(x)) 二阶近似为
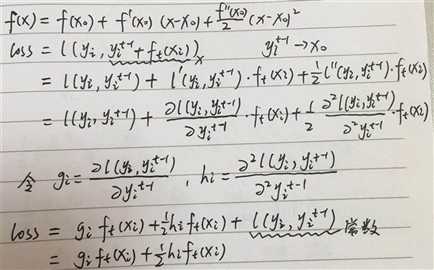
注意这里是对 l(y,yt-1+ft(x)) 的展开。
这里需要理解下gi,hi是什么东西?貌似不是很清楚。
我们以均方差为例来看下

可以看到gi和hi就是损失函数对 预测值 的一阶导和二阶导,
而且gi和hi可以并行计算,并且是根据上一棵树来计算的,也就是在新建树时,他们是已知值。
树损失函数展开为
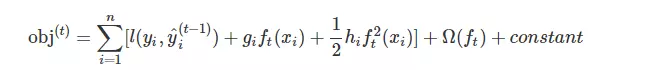
去掉常数项
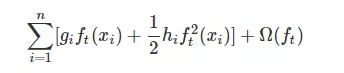
树模型 正则化 Ω(ft)
前面说到决策树的复杂度,假如用决策树的叶节点数T和叶节点的预测值w来对树进行正则化的,当然你也可以自定义其正则化的方式,合理即可,
T尽量少,w尽量平滑,所以
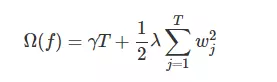
γ λ 是惩罚系数,需要自己定义,γ 越大,表示数结构越简单,其对较多叶节点的树(整棵树的叶节点)惩罚越大,λ 同理。
这种正则方式被作者证明效果很好。
树损失函数变形
ft(x)=wq(x)
故树损失函数变为
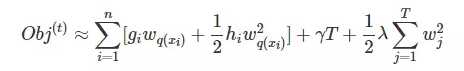
这样的式子真的没法处理,需要进一步变换
先看这张图
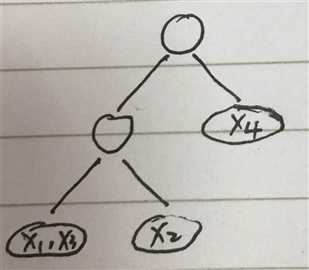
可以看到T个叶节点中包含了所有样本,也就是说遍历叶节点可以获取所有样本,且同一个叶节点中样本的预测值即wq(x)相同,
那么上式可以转化为
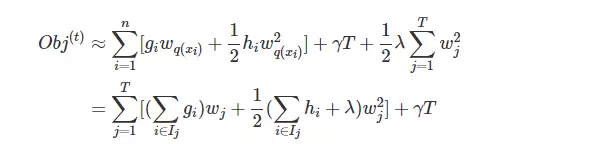
Ij表示第j个叶节点
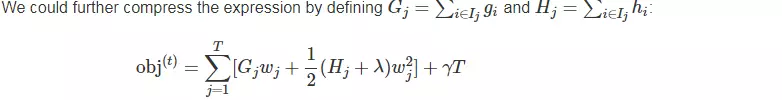
注意,对于一棵确定的树,G H 都是确定的,λ也是确定的,所有上式是一个关于w的二次函数,方程的解是 -b/2a,解带入方程就是二次曲线的最小值
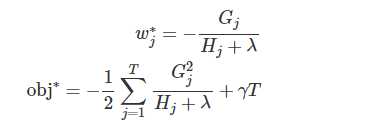
如果能使损失最小,那就是最好的树。
obj 可以理解为树的错误率,错误率越小越好。
这就对应了信息增益等指标,就是分裂的评价指标,选择obj最小的属性进行分裂。
大致如图所示

这里稍微总结一下:
xgboost在上一棵树的基础上,新建一棵树,这棵树根据上一棵树的一阶导和二阶导确定最优的分裂方式。
建树
回忆一下传统的决策树如何建立,以id3为例,先根据一定的原则逐个按属性分裂,然后计算分裂前后的信息增益,选择增益最大的属性进行分裂。
xgboost貌似也是这个逻辑,因为没有其他好办法。
逐个按属性进行分裂,计算分裂前后的的损失(错误率),相减,取损失为正/负的,看谁减谁。
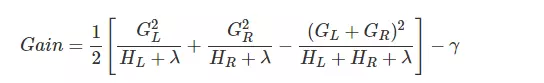

在分的属性中选择绝对值最大的,这里理解就好,语言表述会有些绕。
分裂节点
那按属性怎么分裂?方法几乎无限多,枚举肯定不现实。
回忆一下传统id3决策树,属性分裂有离散和连续之分,离散按属性值划分,连续只能二划分,排序,每两个值之间取个数(如均值)进行划分,
xgboost的属性是离散还是连续呢? 理论上也是都可以,不过回归应该是连续的。
xgboost在分裂时会防止过拟合,所以它尽可能的会减少叶节点的数量,也就是每次只进行2分裂,所以xgboost回归对应的基决策树是cart决策树。
实际分裂也大致等同于cart决策树,每次分裂都会计算损失
精确搜索法

怎么理解呢?大致思路等同于连续值处理

但是当样本太大时,这种方法也会很慢,于是作者提出了一种加速方法
近似搜索法
思路大致同精确搜索,只是在确定分裂点时,不是逐个探索,而是在对特征进行排序后,找出几个区间,作为分裂点
如先观察特征的分布情况,划分区间,再分裂。

具体作者又提出了一些选择
全局近似:即在训练前就确定分裂点,后面每棵树都用这些分裂点,这样提出候选分裂点的次数少,而每棵树探索的分裂点多,因为这种方法往往要多设一些分裂点,不然到后面就分不开了
局部近似:即每次建树时重新确定分裂点,这种方法每次尝试的少,对层数较深的树比较合适
参考资料:
https://www.jianshu.com/p/7467e616f227
https://xgboost.readthedocs.io/en/latest/tutorials/model.html
https://www.hrwhisper.me/machine-learning-xgboost/ 此文章还有很多我这里没讲到
原文:https://www.cnblogs.com/yanshw/p/10631440.html