当数据集的数值属性具有非常大的比例差异,往往导致机器学习的算法表现不佳,当然也有极少数特例。在实际应用中,通过梯度下降法求解的模型通常需要归一化,包括线性回归、逻辑回归、支持向量机、神经网络等模型。但对于决策树不使用,以C4.5为例,决策树在进行节点分裂时主要依据数据集D关于特征X的信息增益比,而信息增益比根特征是否经过归一化是无关的。
同比例缩放所有属性常用的两种方法是:最小-最大缩放和标准化
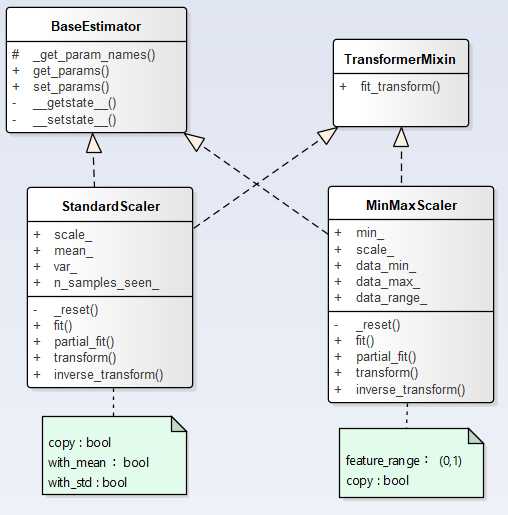
最小-最大缩放(又加归一化),将值重新缩放使其最终范围在0-1之间,(current - min)/ (max - min),Scikit-Learn提供了MinMaxSaler转换器可以完成该功能
标准化,(current - mean) / var,使得得到的结果分布具备单位方差,相比最小-最大缩放,标准化的方法受异常值的影响更小,同样Scikit-Learn也提供了StandScaler转换器
>>> from sklearn.preprocessing import MinMaxScaler >>> >>> data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]] >>> scaler = MinMaxScaler() >>> print(scaler.fit(data)) MinMaxScaler(copy=True, feature_range=(0, 1)) >>> print(scaler.data_max_) [ 1. 18.] >>> print(scaler.transform(data)) [[ 0. 0. ] [ 0.25 0.25] [ 0.5 0.5 ] [ 1. 1. ]] >>> print(scaler.transform([[2, 2]])) [[ 1.5 0. ]]
>>> data = [[0, 0], [0, 0], [1, 1], [1, 1]] >>> scaler = StandardScaler() >>> print(scaler.fit(data)) StandardScaler(copy=True, with_mean=True, with_std=True) >>> print(scaler.mean_) [ 0.5 0.5] >>> print(scaler.transform(data)) [[-1. -1.] [-1. -1.] [ 1. 1.] [ 1. 1.]] >>> print(scaler.transform([[2, 2]])) [[ 3. 3.]]
原文:https://www.cnblogs.com/xiaobingqianrui/p/10592250.html