1.单机MySQL的美好年代
在90年代,一个网站的访问量一般都不大,用单个数据库完全可以轻松应付。
在那个时候,更多的都是静态网页,动态交互类型的网站不多。
上述架构下,我们来看看数据存储的瓶颈是什么?
1.数据量的总大小 一个机器放不下时
2.数据的索引(B+ Tree)一个机器的内存放不下时
3.访问量(读写混合)一个实例不能承受
如果满足了上述1 or 3个,进化......
2 .Memcached(缓存)+MySQL+垂直拆分
后来,随着访问量的上升,几乎大部分使用MySQL架构的网站在数据库上都开始出现了性能问题,web程序不再仅仅专注在功能上,同时也在追求性能。程序员们开始大量的使用缓存技术来缓解数据库的压力,优化数据库的结构和索引。开始比较流行的是通过文件缓存来缓解数据库压力,但是当访问量继续增大的时候,多台web机器通过文件缓存不能共享,大量的小文件缓存也带了了比较高的IO压力。在这个时候,Memcached就自然的成为一个非常时尚的技术产品。
Memcached作为一个独立的分布式的缓存服务器,为多个web服务器提供了一个共享的高性能缓存服务,在Memcached服务器上,又发展了根据hash算法来进行多台Memcached缓存服务的扩展,然后又出现了一致性hash来解决增加或减少缓存服务器导致重新hash带来的大量缓存失效的弊端
3. Mysql主从读写分离
由于数据库的写入压力增加,Memcached只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负,大部分网站开始使用主从复制技术来达到读写分离,以提高读写性能和读库的可扩展性。Mysql的master-slave模式成为这个时候的网站标配了。
4 .分表分库+水平拆分+mysql集群
在Memcached的高速缓存,MySQL的主从复制,读写分离的基础之上,这时MySQL主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发MySQL应用开始使用InnoDB引擎代替MyISAM。
同时,开始流行使用分表分库来缓解写压力和数据增长的扩展问题。这个时候,分表分库成了一个热门技术,是面试的热门问题也是业界讨论的热门技术问题。也就在这个时候,MySQL推出了还不太稳定的表分区,这也给技术实力一般的公司带来了希望。虽然MySQL推出了MySQL Cluster集群,但性能也不能很好满足互联网的要求,只是在高可靠性上提供了非常大的保证。
5 .MySQL的扩展性瓶颈
MySQL数据库也经常存储一些大文本字段,导致数据库表非常的大,在做数据库恢复的时候就导致非常的慢,不容易快速恢复数据库。比如1000万4KB大小的文本就接近40GB的大小,如果能把这些数据从MySQL省去,MySQL将变得非常的小。关系数据库很强大,但是它并不能很好的应付所有的应用场景。MySQL的扩展性差(需要复杂的技术来实现),大数据下IO压力大,表结构更改困难,正是当前使用MySQL的开发人员面临的问题。
NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”,
泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题,包括超大规模数据的存储。
(例如谷歌或Facebook每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
(1)易扩展
NoSQL数据库种类繁多,但是一个共同的特点都是去掉关系数据库的关系型特性。
数据之间无关系,这样就非常容易扩展。也无形之间,在架构的层面上带来了可扩展的能力。
(2)大数据量高性能
NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现优秀。
这得益于它的无关系性,数据库的结构简单。
一般MySQL使用Query Cache,每次表的更新Cache就失效,是一种大粒度的Cache,
在针对web2.0的交互频繁的应用,Cache性能不高。而NoSQL的Cache是记录级的,
是一种细粒度的Cache,所以NoSQL在这个层面上来说就要性能高很多了
(3)多样灵活的数据模型
NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。而在关系数据库里,
增删字段是一件非常麻烦的事情。如果是非常大数据量的表,增加字段简直就是一个噩梦
传统RDBMS VS NOSQL
RDBMS vs NoSQL
RDBMS
- 高度组织化结构化数据
- 结构化查询语言(SQL)
- 数据和关系都存储在单独的表中。
- 数据操纵语言,数据定义语言
- 严格的一致性
- 基础事务
NoSQL
- 代表着不仅仅是SQL
- 没有声明性查询语言
- 没有预定义的模式
-键 - 值对存储,列存储,文档存储,图形数据库
- 最终一致性,而非ACID属性
- 非结构化和不可预知的数据
- CAP定理
- 高性能,高可用性和可伸缩性
8.为什么用NoSQL
今天我们可以通过第三方平台(如:Google,Facebook等)可以很容易的访问和抓取数据。用户的个人信息,社交网络,地理位置,用户生成的数据和用户操作日志已经成倍的增加。我们如果要对这些用户数据进行挖掘,那SQL数据库已经不适合这些应用了, NoSQL数据库的发展也却能很好的处理这些大的数据。
Redis,memcache,Mongdb
10. 怎么玩
KV,Cache,Persistence,.......
(1)大数据时代的3V
海量Volume,多样Variety,实时Velocity
高并发,高可扩,高性能
以一个电商客户、订单、订购、地址模型来对比下关系型数据库和非关系型数据库
1.传统的关系型数据库你如何设计?
ER图(1:1/1:N/N:N,主外键等常见)
什么是BSON
BSON()是一种类json的一种二进制形式的存储格式,简称Binary JSON,
它和JSON一样,支持内嵌的文档对象和数组对象
给学生用BSon画出构建的数据模型
{
"customer":{
"id":1136,
"name":"Z3",
"billingAddress":[{"city":"beijing"}],
"orders":[
{
"id":17,
"customerId":1136,
"orderItems":[{"productId":27,"price":77.5,"productName":"thinking in java"}],
"shippingAddress":[{"city":"beijing"}]
"orderPayment":[{"ccinfo":"111-222-333","txnid":"asdfadcd334","billingAddress":{"city":"beijing"}}],
}
]
}
}
两者对比,问题和难点
为什么上述的情况可以用聚合模型来处理
高并发的操作是不太建议有关联查询的,互联网公司用冗余数据来避免关联查询
分布式事务是支持不了太多的并发的.
聚合模型
KV键值
,bson,
列族() 顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,
对针对某一列或者某几列的查询有非常大的IO优势。
图形
KV键值:典型介绍
新浪:BerkeleyDB+redis,美团:redis+tair,阿里、百度:memcache+redis
文档型数据库(bson格式比较多):典型介绍
CouchDB,MongoDB
MongoDB 是一个基于分布式文件存储的数据库。由 C++ 语言编写。旨在为 WEB 应用提供可扩展的高性能数据存储解决方案。
MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
列存储数据库
Cassandra, HBase
分布式文件系统
图关系数据库
它不是放图形的,放的是关系比如:朋友圈社交网络、广告推荐系统
社交网络,推荐系统等。专注于构建关系图谱
Neo4J, InfoGrid
关系型数据库遵循ACID规则
事务在英文中是transaction,和现实世界中的交易很类似,它有如下四个特性:
1、A (Atomicity) 原子性
原子性很容易理解,也就是说事务里的所有操作要么全部做完,要么都不做,事务成功的条件是事务里的所有操作都成功,只要有一个操作失败,整个事务就失败,需要回滚。比如银行转账,从A账户转100元至B账户,分为两个步骤:1)从A账户取100元;2)存入100元至B账户。这两步要么一起完成,要么一起不完成,如果只完成第一步,第二步失败,钱会莫名其妙少了100元。
2、C (Consistency) 一致性
一致性也比较容易理解,也就是说数据库要一直处于一致的状态,事务的运行不会改变数据库原本的一致性约束。
3、I (Isolation) 独立性
所谓的独立性是指并发的事务之间不会互相影响,如果一个事务要访问的数据正在被另外一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。比如现有有个交易是从A账户转100元至B账户,在这个交易还未完成的情况下,如果此时B查询自己的账户,是看不到新增加的100元的
4、D (Durability) 持久性
持久性是指一旦事务提交后,它所做的修改将会永久的保存在数据库上,即使出现宕机也不会丢失。
C:Consistency(强一致性)A:Availability(可用性)P:Partition tolerance(分区容错性)
CAP的3进2
CAP理论就是说在分布式存储系统中,最多只能实现上面的两点。
而由于当前的网络硬件肯定会出现延迟丢包等问题,所以
分区容忍性是我们必须需要实现的。
所以我们只能在一致性和可用性之间进行权衡,没有NoSQL系统能同时保证这三点。
=======================================================================================================================
C:强一致性 A:高可用性 P:分布式容忍性
CA 传统Oracle数据库
AP 大多数网站架构的选择
CP Redis、Mongodb
注意:分布式架构的时候必须做出取舍。
一致性和可用性之间取一个平衡。多余大多数web应用,其实并不需要强一致性。
因此牺牲C换取P,这是目前分布式数据库产品的方向
=======================================================================================================================
一致性与可用性的决择
对于web2.0网站来说,关系数据库的很多主要特性却往往无用武之地
数据库事务一致性需求
很多web实时系统并不要求严格的数据库事务,对读一致性的要求很低, 有些场合对写一致性要求并不高。允许实现最终一致性。
数据库的写实时性和读实时性需求
对关系数据库来说,插入一条数据之后立刻查询,是肯定可以读出来这条数据的,但是对于很多web应用来说,并不要求这么高的实时性,比方说发一条消息之 后,过几秒乃至十几秒之后,我的订阅者才看到这条动态是完全可以接受的。
对复杂的SQL查询,特别是多表关联查询的需求
任何大数据量的web系统,都非常忌讳多个大表的关联查询,以及复杂的数据分析类型的报表查询,特别是SNS类型的网站,从需求以及产品设计角 度,就避免了这种情况的产生。往往更多的只是单表的主键查询,以及单表的简单条件分页查询,SQL的功能被极大的弱化了。
CAP理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,
最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三 大类:
CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
CP - 满足一致性,分区容忍必的系统,通常性能不是特别高。
AP - 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
BASE就是为了解决关系数据库强一致性引起的问题而引起的可用性降低而提出的解决方案。
BASE其实是下面三个术语的缩写:
基本可用(Basically Available)
软状态(Soft state)
最终一致(Eventually consistent)
它的思想是通过让系统放松对某一时刻数据一致性的要求来换取系统整体伸缩性和性能上改观。为什么这么说呢,缘由就在于大型系统往往由于地域分布和极高性能的要求,不可能采用分布式事务来完成这些指标,要想获得这些指标,我们必须采用另外一种方式来完成,这里BASE就是解决这个问题的办法
分布式系统
分布式系统(distributed system)
由多台计算机和通信的软件组件通过计算机网络连接(本地网络或广域网)组成。分布式系统是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。分布式系统可以应用在在不同的平台上如:Pc、工作站、局域网和广域网上等。
简单来讲:
1分布式:不同的多台服务器上面部署不同的服务模块(工程),他们之间通过Rpc/Rmi之间通信和调用,对外提供服务和组内协作。
2集群:不同的多台服务器上面部署相同的服务模块,通过分布式调度软件进行统一的调度,对外提供服务和访问。
Redis
1.Redis:REmote DIctionary Server(远程字典服务器)
是完全开源免费的,用C语言编写的,遵守BSD协议,
是一个高性能的(key/value)分布式内存数据库,基于内存运行
并支持持久化的NoSQL数据库,是当前最热门的NoSql数据库之一,
也被人们称为数据结构服务器
2.Redis 与其他 key - value 缓存产品有以下三个特点
(1)Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用
(2)Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储
(3)Redis支持数据的备份,即master-slave模式的数据备份
2.能干吗?
内存存储和持久化:redis支持异步将内存中的数据写到硬盘上,同时不影响继续服务
取最新N个数据的操作,如:可以将最新的10条评论的ID放在Redis的List集合里面
模拟类似于HttpSession这种需要设定过期时间的功能
发布、订阅消息系统
定时器、计数器
3 去哪下
4 怎么玩
数据类型、基本操作和配置
持久化和复制,RDB/AOF
事务的控制
复制
......
VMWare虚拟机的安装
CentOS或者RedHad5的安装
如何查看自己的linux是32位还是64位
getconf LONG_BIT
返回是多少就是几位
假如出现了不支持虚拟化的问题
我的笔记本cpu是64位的,操作系统也是64位的,问题应该如虚拟机右下角提示所说,
是“宿主机BIOS设置中的硬件虚拟化被禁用了。”
需要打开笔记本BIOS中的IVT对虚拟化的支持。
找到菜单“Security”–“System Security”,
将Virtualization Technology(VTx)和Virtualization Technology DirectedI/O(VTd)设置为 Enabled。
保存并退出BIOS设置,重启电脑,
VMTools的安装
设置共享目录
上述环境都OK后开始进行Redis的服务器安装配置
Redis的安装
Window 下安装
下载地址:https://github.com/dmajkic/redis/downloads
下载到的Redis支持32bit和64bit。根据自己实际情况选择,将64bit的内容cp到自定义盘符安装目录取名redis。 如 C:\reids
打开一个cmd窗口 使用cd命令切换目录到 C:\redis 运行 redis-server.exe redis.conf 。
如果想方便的话,可以把redis的路径加到系统的环境变量里,这样就省得再输路径了,后面的那个redis.conf可以省略,
如果省略,会启用默认的。输入之后,会显示如下界面:
这时候另启一个cmd窗口,原来的不要关闭,不然就无法访问服务端了。
切换到redis目录下运行 redis-cli.exe -h 127.0.0.1 -p 6379 。
设置键值对 set myKey abc
取出键值对 get myKey
由于企业里面做Redis开发,99%都是Linux版的运用和安装,
几乎不会涉及到Windows版,上一步的讲解只是为了知识的完整性,
Windows版不作为重点,同学可以下去自己玩,企业实战就认一个版:Linux
Linux版安装

下载获得redis-3.0.4.tar.gz后将它放入我们的Linux目录/opt
/opt目录下,解压命令:tar -zxvf redis-3.0.4.tar.gz
解压完成后出现文件夹:redis-3.0.4
进入目录:cd redis-3.0.4
在redis-3.0.4目录下执行make命令
运行make命令时故意出现的错误解析:
(1)安装gcc
gcc是linux下的一个编译程序,是C程序的编译工具。
GCC(GNU Compiler Collection) 是 GNU(GNU‘s Not Unix) 计划提供的编译器家族,它能够支持 C, C++, Objective-C, Fortran, Java 和 Ada 等等程序设计语言前端,同时能够运行在 x86, x86-64, IA-64, PowerPC, SPARC 和 Alpha 等等几乎目前所有的硬件平台上。鉴于这些特征,以及 GCC 编译代码的高效性,使得 GCC 成为绝大多数自由软件开发编译的首选工具。虽然对于程序员们来说,编译器只是一个工具,除了开发和维护人员,很少有人关注编译器的发展,但是 GCC 的影响力是如此之大,它的性能提升甚至有望改善所有的自由软件的运行效率,同时它的内部结构的变化也体现出现代编译器发展的新特征。
(2)能上网:yum install gcc-c++
二次make
jemalloc/jemalloc.h:没有那个文件或目录
运行make distclean之后再make
Redis Test(可以不用执行)
下载TCL的网址:
http://www.linuxfromscratch.org/blfs/view/cvs/general/tcl.html
安装TCL
如果make完成后继续执行make install
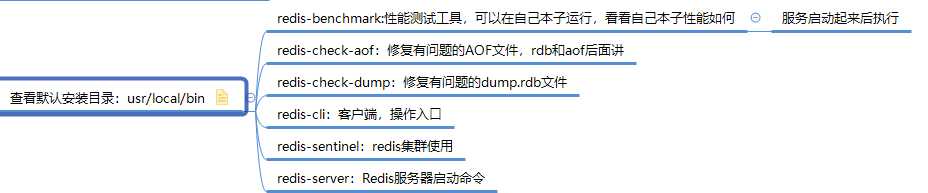
查看默认安装目录:usr/local/bin
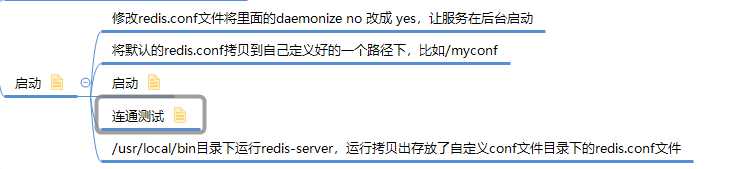

Redis启动后杂项基础知识讲解
原文:https://www.cnblogs.com/zhulina-917/p/10660930.html