>>> class Student(object): ... pass ...
使用关键字class,Python解释器在执行的时候就会创建一个对象
以上代码段将在内存中创建一个对象,名字就是Student 这个对象(类对象Student)拥有创建对象(实例对象)的能力。但是,它的本质仍然是一个对象,于是乎你可以对它做如下的操作:
1.你可以将它赋值给一个变量
2.你可以拷贝它
3.你可以为它增加属性
4.你可以将它作为函数参数进行传递
>>> s = Student() >>> print(s) <__main__.Student object at 0x000001E168A65278> >>> print(Student) # 你可以打印一个类,因为类也是一个对象 <class ‘__main__.Student‘> >>> def echo(o): ... print(o) ... >>> echo(Student) # 可以将类作为参数传递给函数 <class ‘__main__.Student‘> >>> print(hasattr(Student,‘name‘)) False >>> Student.name = ‘hanmeimei‘ # 为类添加属性 >>> print(hasattr(Student,‘name‘)) True >>> print(Student.name) hanmeimei >>> Stu = Student # 将类赋值给一个变量 >>> print(Stu()) <__main__.Student object at 0x000001E168A653C8>
内建函数 type
>>> class Student(object): ... pass ... >>> s = Student() >>> print(type(1)) <class ‘int‘> # 数值的类型 >>> print(type(‘abc‘)) <class ‘str‘> # 字符串的类型 >>> print(type(s)) <class ‘__main__.Student‘> # 实例对象类型 >>> print(type(Student)) # 类的类型 <class ‘type‘> >>> type(str) <class ‘type‘> >>> type(int) <class ‘type‘> >>> type(dict) <class ‘type‘
使用type 动态创建类
函数type实际上是一个元类。type就是Python在背后用来创建所有类的元类。Python中所有的东西,包括整数、字符串、函数以及类,它们全部都是对象,而且它们都是从一个类创建而来,这个类就是type。
>>> age = 30 >>> age.__class__ <class ‘int‘> >>> name = ‘hanmeimei‘ >>> name.__class__ <class ‘str‘> >>> def foo(): ... pass ... >>> foo.__class__ <class ‘function‘> >>> class Bar(object): ... pass ... >>> b = Bar() >>> b.__class__ <class ‘__main__.Bar‘> >>> age.__class__.__class__ <class ‘type‘> >>> name.__class__.__class__ <class ‘type‘> >>> foo.__class__.__class__ <class ‘type‘> >>> b.__class__.__class__ <class ‘type‘>
type 创建类
type(类名, 由父类名称组成的元组(针对继承的情况,可以为空),包含属性的字典(名称和值))
>>> Foo = type(‘Foo‘,(),{‘bar‘:True}) >>> def echo_bar(self): # 普通方法 ... print(self.bar) ... >>> @staticmethod # 静态方法 ... def testStatic(): ... print("static method ......") ... >>> @classmethod # 类方法 ... def testClass(cls): ... print(cls.bar) ... >>> Foochild = type(‘Foochild‘,(Foo,),{"echo_bar":echo_bar,"testStatic":testStatic,"testClass":testClass}) >>> print(Foochild) <class ‘__main__.Foochild‘> >>> child = Foochild() # 实例化 >>> print(child) <__main__.Foochild object at 0x0000020A62AC54E0> >>> child.bar # 从父类继承的 bar 属性 True >>> child.echo_bar() # 调用普通方法 True >>> child.testStatic() # 调用静态方法 static method ...... >>> child.testClass() # 调用类方法 True
>>> class Person(object): ... def __init__(self,name=None,age=None): ... self.name=name ... self.age=age ... >>> p = Person(‘hanmeimei‘,20) >>> p.sex = ‘female‘ # 为对象动态添加属性 >>> p.sex ‘female‘ >>> p1 = Person(‘lilei‘,19) >>> p1.sex # 上面是为 p 对象添加属性,p1 并没有‘sex‘属性 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: ‘Person‘ object has no attribute ‘sex‘ >>> Person.sex=None # 为类动态添加属性 >>> p1 = Person(‘lilei‘,19) >>> print(p1.sex)# 为类动态添加属性后实例化出来的对象也就有sex属性 None >>> p.sex ‘female‘ >>> del p.sex # 动态删除对象属性 >>> print(p.sex) # 对象p仍有类属型sex None >>> del Person.sex # 动态删除类属性 >>> p.sex Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: ‘Person‘ object has no attribute ‘sex‘
>>> class Person(object): ... def __init__(self,name,age): ... self.name=name ... self.age=age ... >>> def run(self): ... print(‘------%s is running------‘ %self.name) ... >>> p = Person(‘lilei‘,20) >>> import types >>> p.run = types.MethodType(run,p) # 为对象动态添加方法 >>> p.run() ------lilei is running------ import types class Person(object): num = 0 def __init__(self, name = None, age = None): self.name = name self.age = age def eat(self): print("eat food") #定义一个实例方法 def run(self, speed): print("%s在移动, 速度是 %d km/h"%(self.name, speed)) #定义一个类方法 @classmethod def testClass(cls): cls.num = 100 #定义一个静态方法 @staticmethod def testStatic(): print("---static method----") #创建一个实例对象 P = Person("老王", 24) #调用在class中的方法 P.eat() #给这个对象添加实例方法 P.run = types.MethodType(run, P) #调用实例方法 P.run(180) #给Person类绑定类方法 Person.testClass = testClass #调用类方法 print(Person.num) Person.testClass() print(Person.num) #给Person类绑定静态方法 Person.testStatic = testStatic #调用静态方法 Person.testStatic() >>> eat food 老王在移动, 速度是 180 km/h 0 100 ---static method----
动态语言:可以在运行的过程中,修改代码
静态语言:编译时已经确定好代码,运行过程中不能修改
如果我们想要限制实例的属性怎么办?比如,只允许对Person实例添加name和age属性。
为了达到限制的目的,Python允许在定义class的时候,定义一个特殊的__slots__变量,来限制该class实例能添加的属性:
>>> class Person(object): ... __slots__ = (‘name‘,‘age‘) ... >>> p = Person() >>> p.name = ‘hanmeimei‘ >>> p.age = 19 >>> p.score = 90 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: ‘Person‘ object has no attribute ‘score‘
__slots__定义的属性仅对当前类实例起作用,对继承的子类是不起作用的
除非在子类中也定义__slots__,这样,子类实例允许定义的属性就是自身的__slots__加上父类的__slots__
在Python中,这种一边循环一边计算的机制,称为生成器:generator。
创建生成器的方式一:把列表生成式的[] 改为()
>>> L = [ x*2 for x in range(5)] >>> L [0, 2, 4, 6, 8] >>> G = ( x*2 for x in range(5) ) >>> G <generator object <genexpr> at 0x000001AF9F383AF0> >>> next(G) # 等价于 G.__next__() 0 >>> next(G) 2 >>> next(G) 4 >>> next(G) 6 >>> next(G) 8 >>> next(G) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>> G = ( x*2 for x in range(5) ) >>> for x in G: ... print(x) ... 0 2 4 6 8
生成器保存的是算法,每次调用 next(G) ,就计算出 G 的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出 StopIteration 的异常,
我们创建了一个生成器后,基本上永远不会调用 next() ,而是通过 for 循环来迭代它,并且不需要关心 StopIteration 异常。
创建生成器的方式二:利用 yield
>>> def fib(): ... print(‘------start------‘) ... a,b = 0,1 ... for i in range(5): ... print(‘------step1------‘) ... yield b ... print(‘------step2------‘) ... a,b = b,a+b ... print(‘------step3------‘) ... print(‘------end------‘) ... >>> fib() <generator object fib at 0x000001AF9F383AF0> >>> a = fib() >>> next(a) ------start------ ------step1------ 1 >>> next(a) ------step2------ ------step3------ ------step1------ 1 >>> next(a) ------step2------ ------step3------ ------step1------ 2 >>> next(a) ------step2------ ------step3------ ------step1------ 3 >>> next(a) ------step2------ ------step3------ ------step1------ 5 >>> next(a) ------step2------ ------step3------ ------end------ Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration def fib(): print(‘------start------‘) a,b = 0,1 for i in range(5): yield b a,b = b,a+b print(‘------end------‘) for num in fib(): # 利用循环遍历生成器 print(num) ‘‘‘ ------start------ 1 1 2 3 5 ------end------ ‘‘‘
send()方法
>>> def test(): ... i = 0 ... while i < 5: ... temp = yield i # yield i 表达式的值并不是 i 的值 ... print(temp) ... i += 1 ... >>> t = test() >>> t.__next__() 0 >>> t.__next__() None 1 >>> t.__next__() None 2 >>> t.send("haha...") # send()方法会执行__next()__ 并将参数作为表达式 yield i 的结果传给 temp haha... 3 >>> def test(): ... i = 0 ... while i < 5: ... temp = yield i ... print(temp) ... i += 1 ... >>> t = test() >>> t.send("haha...") # send()方法不能在生成器生成第一个时传入非空值 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can‘t send non-None value to a just-started generator >>> t.send(None) 0 >>> t.send("haha...") haha... 1 >>> t.__next__() None 2
完成多任务(协程)
def test1(): while True: print("------1------") yield None def test2(): while True: print("------2------") yield None t1 = test1() t2 = test2() while True: t1.__next__() t2.__next__() ------1------ ------2------ ------1------ ------2------ ------1------ ------2------ ------1------ ------2------ ------1------ ------2------ ......
可以直接作用于 for 循环的数据类型有以下几种:
一类是集合数据类型,如 list 、 tuple 、 dict 、 set 、 str 等;
一类是 generator ,包括生成器和带 yield 的generator function。
这些可以直接作用于 for 循环的对象统称为可迭代对象: Iterable 。
可以使用 isinstance() 判断一个对象是否是 Iterable 对象:
>>> from collections import Iterable >>> isinstance([],Iterable) True >>> isinstance({},Iterable) True >>> isinstance(‘hello‘,Iterable) True >>> isinstance((x for x in range(5)),Iterable) True >>> isinstance(100,Iterable) False
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
可以使用 isinstance() 判断一个对象是否是 Iterator 对象:
>>> from collections import Iterator >>> isinstance([],Iterator) False >>> isinstance({},Iterator) False >>> isinstance(‘hello‘,Iterator) False >>> isinstance((x for x in range(5)),Iterator) True >>> isinstance(100,Iterator) False
生成器都是 Iterator 对象,但 list 、 dict 、 str 虽然是 Iterable ,却不是 Iterator 。
把 list 、 dict 、 str 等 Iterable 变成 Iterator 可以使用 iter() 函数:
>>> from collections import Iterator >>> isinstance([1,2,3,4],Iterator) False >>> isinstance(iter([1,2,3,4]),Iterator) True >>> L = iter([1,2,3,4]) >>> L <list_iterator object at 0x000001D71021F780> >>> next(L) 1 >>> next(L) 2
函数调用
def test1(): print("--- in test1 func----") test1() # 调用函数 ret = test1 # 引用函数,ret和test1指向同一对象 print(id(ret)) print(id(test1)) ret() # 通过引用调用函数 ‘‘‘ --- in test1 func---- 1900388193688 1900388193688 --- in test1 func---- ‘‘‘
闭包
def test(number): # 定义一个函数 # 在函数内部再定义一个函数,并且这个函数用到了外边函数的变量, # 那么将这个函数以及用到的一些变量称之为闭包 def test_in(number_in): print("in test_in 函数, number_in is %d"%number_in) return number+number_in #其实这里返回的就是闭包的结果 return test_in # 给test函数赋值,这个20就是给参数number ret = test(20) # 注意这里的100其实给参数number_in print(ret(100)) # 注意这里的200其实给参数number_in print(ret(200)) ‘‘‘ in test_in 函数, number_in is 100 120 in test_in 函数, number_in is 200 220 ‘‘‘ def test(number): print("------1------") def test_in(number_in): print("------2------") print("in test_in 函数, number_in is %d"%number_in) return number+number_in print("------3------") return test_in ‘‘‘ >>> ret = test(20) ------1------ ------3------ >>> ret(100) ------2------ in test_in 函数, number_in is 100 120 ‘‘‘
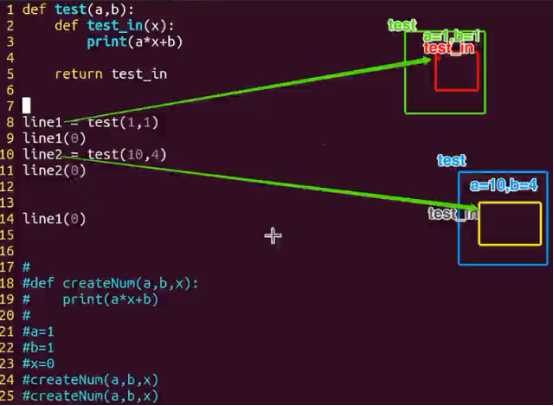
闭包可以简化函数的调用,如上若a,b的值不变,第一个函数可以只传参数x,而第二个函数每次调用时则要传a,b,x三个参数
由于闭包引用了外部函数的局部变量,则外部函数的局部变量没有及时释放,消耗内存
定义:装饰器本质是函数,用于装饰其他函数,就是为其他函数添加附加功能
原则:1. 不能修改被装饰函数的源代码
2. 不能修改被装饰的函数的调用方式
实现装饰器的知识储备:
函数即“变量”:函数体存在内存中,是一个变量,函数名指向函数体,是一个变量名,当函数体没有变量指向时,解析器会将函数体回收
def bar(): print(‘in the bar‘) def foo(): print(‘in the foo‘) bar() foo() ‘‘‘ in the foo in the bar ‘‘‘ def foo(): print(‘in the foo‘) bar() def bar(): print(‘in the bar‘) foo() ‘‘‘ in the foo in the bar ‘‘‘ def foo(): print(‘in the foo‘) bar() foo() def bar(): print(‘in the bar‘) ‘‘‘ in the foo Traceback (most recent call last): NameError: name ‘bar‘ is not defined ‘‘‘
高阶函数
a. 把一个函数名当作实参传给另一个函数(在不修改被装饰函数源代码的情况下为其添加功能)
import time def bar(): time.sleep(3) print(‘in the bar‘) #bar() def test1(func): start_time=time.time() func() stop_time=time.time() print(‘the func run time is %s‘ %(stop_time-start_time)) test1(bar) #为bar函数添加了计算函数运行时间的功能,但改变了函数的调用方式 ‘‘‘ in the bar the func run time is 3.0221872329711914 ‘‘‘
b. 返回值中包含函数名(不修改函数的调用方式)
import time def bar(): time.sleep(3) print(‘in the bar‘) def test2(func): print(func) return func #返回函数内存地址 bar=test2(bar) bar() #没改变函数的调用方式,但为bar函数添加了test2中打印函数内存地址的功能 ‘‘‘ <function bar at 0x000001B84932FBF8> in the bar ‘‘‘
c. 嵌套函数:函数内部再定义函数
def foo(): print(‘in the foo‘) def bar(): print(‘in the bar‘) bar() foo() ‘‘‘ in the foo in the bar ‘‘‘
装饰器的使用:@装饰器函数名
import time def timer(func): def deco(): start_time=time.time() func() stop_time=time.time() print(‘the func run time is %s‘ %(stop_time-start_time)) return deco @timer # 相当于test1=timer(test1) def test1(): time.sleep(3) print(‘in the test1‘) #test1=timer(test1) test1() ‘‘‘ in the test1 the func run time is 3.0173559188842773 ‘‘‘
函数参数问题:
import time def timer(func): def deco(*args,**kwargs): start_time=time.time() func(*args,**kwargs) stop_time=time.time() print(‘the func run time is %s‘ %(stop_time-start_time)) return deco @timer def test1(): time.sleep(3) print(‘in the test1‘) @timer def test2(name,age): time.sleep(1) print(‘test2:‘,name,age) test1() test2(‘goku‘,12)
装饰器原理:
def w1(func): def inner(): print("----验证----") func() return inner def f1(): print("-----f1----") f1 = w1(f1) f1() ‘‘‘ ----验证---- -----f1---- ‘‘‘
def w1(func): def inner(): print("---验证权限---") func() return inner @w1 # 等价于 f1 = w1(f1),为函数添加验证权限的功能 def f1(): print("---f1---") @w1 def f2(): print("---f2---") f1() f2() ‘‘‘ ---验证权限--- ---f1--- ---验证权限--- ---f2--- ‘‘‘
当函数被两个装饰器装饰的情况:
def makeBold(fn): def wrapped(): return "<b>" + fn() + "</b>" return wrapped def makeItalic(fn): def wrapped(): return "<i>" + fn() + "</i>" return wrapped # 装饰器装饰的是函数,当有两个装饰器时, # 先用 makeItalic 装饰函数,再用 makeBold 装饰 @makeBold @makeItalic def test(): return "hello world" print(test()) ‘‘‘ <b><i>hello world</i></b> ‘‘‘
装饰器的执行顺序:
def w1(func): print("---正在装饰1----") def inner(): print("---正在验证权限1----") func() return inner def w2(func): print("---正在装饰2----") def inner(): print("---正在验证权限2----") func() return inner @w1 @w2 def f1(): print("---f1---") f1() ‘‘‘ ---正在装饰2---- ---正在装饰1---- ---正在验证权限1---- ---正在验证权限2---- ---f1--- ‘‘‘
使用装饰器对无参数的函数进行装饰时的执行顺序
def func(functionName): print("---func---1---") def func_in(): print("---func_in---1---") functionName() print("---func_in---2---") print("---func---2---") return func_in @func def test(): print("----test----") test() ‘‘‘ ---func---1--- ---func---2--- ---func_in---1--- ----test---- ---func_in---2--- ‘‘‘
使用装饰器对有参数的函数进行装饰
1 def func(functionName): 2 print("---func---1---") 3 def func_in(a, b):# 如果a,b 没有定义,那么会导致13行的调用失败 4 print("---func_in---1---") 5 functionName(a, b) 6 # 如果没有把a,b当做实参进行传递,那么会导致调用11行的函数失败 7 print("---func_in---2---") 8 print("---func---2---") 9 return func_in 10 @func 11 def test(a, b): 12 print("----test-a=%d,b=%d---"%(a,b)) 13 test(11,22) 14 ‘‘‘ 15 ---func---1--- 16 ---func---2--- 17 ---func_in---1--- 18 ----test-a=11,b=22--- 19 ---func_in---2--- 20 ‘‘‘
使用装饰器对有不定长参数的函数进行装饰
def func(functionName): print("---func---1---") def func_in(*args, **kwargs): # 采用不定长参数的方式满足所有函数需要参数以及不需要参数的情况 print("---func_in---1---") functionName(*args, **kwargs) # 这个地方,需要写*以及**,如果不写的话,那么args是元组,而kwargs是字典 print("---func_in---2---") print("---func---2---") return func_in @func def test(a, b, c): print("----test-a=%d,b=%d,c=%d---"%(a,b,c)) @func def test2(a, b, c, d): print("----test-a=%d,b=%d,c=%d,d=%d---"%(a,b,c,d)) test(11,22,33) test2(44,55,66,77) ‘‘‘ ---func---1--- ---func---2--- ---func---1--- ---func---2--- ---func_in---1--- ----test-a=11,b=22,c=33--- ---func_in---2--- ---func_in---1--- ----test-a=44,b=55,c=66,d=77--- ---func_in---2--- ‘‘‘
使用装饰器对有返回值的函数进行装饰
def func(functionName): print("---func---1---") def func_in(): print("---func_in---1---") functionName() print("---func_in---2---") print("---func---2---") return func_in @func def test(): print("----test----") return "haha" ret = test() print("test return value is %s"%ret) ‘‘‘ ---func---1--- ---func---2--- ---func_in---1--- ----test---- ---func_in---2--- test return value is None ‘‘‘
1 def func(functionName): 2 print("---func---1---") 3 def func_in(): 4 print("---func_in---1---") 5 ret = functionName() # 保存返回来的haha 6 print("---func_in---2---") 7 return ret # 把haha返回到14行处的调用 8 print("---func---2---") 9 return func_in 10 @func 11 def test(): 12 print("----test----") 13 return "haha" 14 ret = test() 15 print("test return value is %s"%ret) 16 ‘‘‘ 17 ---func---1--- 18 ---func---2--- 19 ---func_in---1--- 20 ----test---- 21 ---func_in---2--- 22 test return value is haha 23 ‘‘‘
通用装饰器:对通用装饰器应满足三个条件,内部函数参数为(*args, **kwargs) ,返回函数参数为(*args, **kwargs) ,内部函数有返回值
def func(functionName): def func_in(*args, **kwargs): print("-----记录日志-----") ret = functionName(*args, **kwargs) return ret return func_in @func def test1(): print("----test1----") return "haha" @func def test2(): print("----test2---") @func def test3(a): print("-----test3--a=%d--"%a) ret = test1() print("test return value is %s"%ret) a = test2() print("test2 return value is %s"%a) test3(11) ‘‘‘ -----记录日志----- ----test1---- test return value is haha -----记录日志----- ----test2--- test2 return value is None -----记录日志----- -----test3--a=11-- ‘‘‘
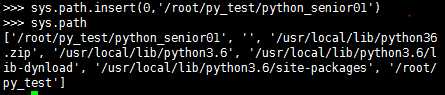
import搜索路径:导入模块时会从sys.path的目录里按顺序依次查找要导入的模块文件

添加导入模块路径:

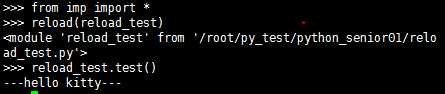
重新导入模块问题:
编写reload_test.py,运行


修改reload_test.py

修改后重新运行或再次导入运行,结果还是不变

采用reload方法重新导入即可得到修改后的结果
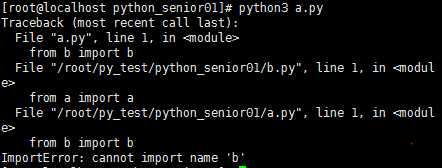
循环导入问题:
a.py

b.py

模块a,b相互导入时会报错
局部变量、全局变量 locals(),globals()
>>> A = 100 >>> B = 200 >>> def test(): ... a = 11 ... b = 22 ... print(locals()) ... >>> test() {‘a‘: 11, ‘b‘: 22} >>> globals() {‘__loader__‘: <class ‘_frozen_importlib.BuiltinImporter‘>, ‘B‘: 200, ‘__spec__‘: None, ‘test‘: <function test at 0x0000025142107F28>, ‘__package__‘: None, ‘__doc__‘: None, ‘__builtins__‘: <module ‘builtins‘ (built-in)>, ‘A‘: 100, ‘__name__‘: ‘__main__‘}
LEGB规则:Python 使用 LEGB 的顺序来查找一个符号对应的对象
locals > enclosing function > globals > builtins
abs = 100 # globals def test1(): abs = 200 # enclosing function def test2(): abs = 300 # locals print(abs) return test2 ret = test1() ret() ‘‘‘ 300 ‘‘‘ abs = 100 # globals def test1(): abs = 200 # enclosing function def test2(): # abs = 300 # locals print(abs) return test2 ret = test1() ret() ‘‘‘ 200 ‘‘‘ abs = 100 # globals def test1(): # abs = 200 # enclosing function def test2(): # abs = 300 # locals print(abs) return test2 ret = test1() ret() ‘‘‘ 100 ‘‘‘ # abs = 100 # globals def test1(): # abs = 200 # enclosing function def test2(): # abs = 300 # locals print(abs) return test2 ret = test1() ret() ‘‘‘ <built-in function abs> ‘‘‘
Is 是比较两个引用是否指向同一个对象(引用比较)
== 是比较两个对象是否相等
>>> a = [11,22,33] >>> b = [11,22,33] >>> a == b True >>> a is b False >>> c = a >>> a == c True >>> x = 100 >>> y = 100 >>> x == y True >>> x is y True >>> x = 10000 >>> y = 10000 >>> x == y True >>> x is y False >>> x = 257 >>> y = 257 >>> x is y False >>> x = 256 >>> y = 256 >>> x is y True >>> x = -5 >>> y = -5 >>> x is y True >>> x = -6 >>> y = -6 >>> x is y False
注意:整数在程序中的使用非常广泛,Python为了优化速度,使用了小整数对象池, 避免为整数频繁申请和销毁内存空间。Python 对小整数的定义是 [-5, 257) 这些整数对象是提前建立好的,不会被垃圾回收。在一个 Python 的程序中,所有位于这个范围内的整数使用的都是同一个对象。
浅拷贝只拷贝引用而没有拷贝内容
>>> a = [11,22,33] >>> b = a >>> b [11, 22, 33] >>> id(a) 140121014271944 >>> id(b) 140121014271944 >>> b.append(44) >>> a [11, 22, 33, 44]
深拷贝是对一个对象所有层次的拷贝
>>> import copy >>> a = [11,22,33] >>> b = copy.deepcopy(a) >>> b [11, 22, 33] >>> id(a) 139992231370056 >>> id(b) 139992231369992 >>> a.append(44) >>> a [11, 22, 33, 44] >>> b [11, 22, 33]
copy 与 deepcopy 的区别:
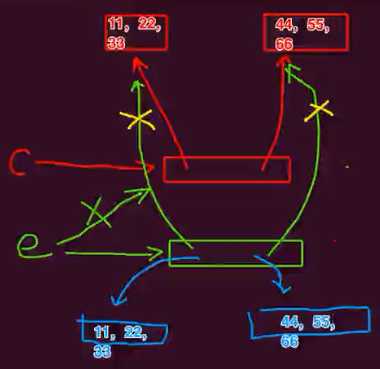
>>> a = [11,22,33] >>> b = [44,55,66] >>> c = [a,b] >>> d = c >>> import copy >>> e = copy.deepcopy(c) >>> id(c) 140313120705224 >>> id(d) 140313120705224 >>> id(e) 140313241857160 >>> a.append(44) >>> c [[11, 22, 33, 44], [44, 55, 66]] >>> e [[11, 22, 33], [44, 55, 66]]
deepcopy 如下图
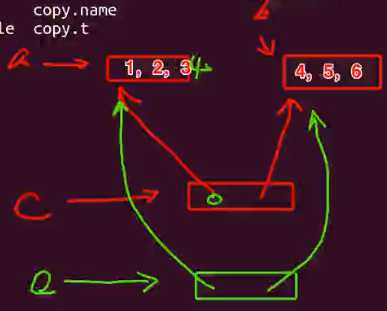
>>> import copy >>> a = [1,2,3] >>> b = [4,5,6] >>> c = [a,b] >>> d = copy.copy(c) >>> id(c) 139808598588552 >>> id(d) 139808477437448 >>> a.append(4) >>> c [[1, 2, 3, 4], [4, 5, 6]] >>> d [[1, 2, 3, 4], [4, 5, 6]]
copy 如下图
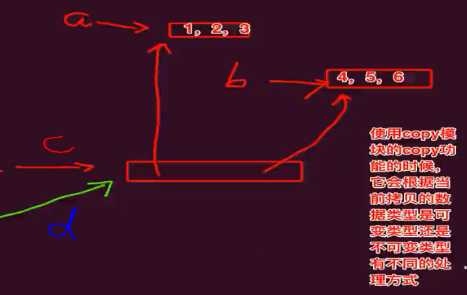
元组的copy问题:列表和元组的copy.copy()处理方式不一样
>>> a = [1,2,3] >>> b = [4,5,6] >>> c = (a,b) >>> import copy >>> d = copy.copy(c) >>> e = copy.deepcopy(c) >>> id(c) 140600696497992 >>> id(d) 140600696497992 >>> id(e) 140600696417608 >>> a.append(8) >>> c[0] [1, 2, 3, 8] >>> e[0] [1, 2, 3]
元组copy如下图
|
xx |
公有变量(public) |
|
_x |
单前置下划线,私有化属性或方法,from somemodule import *(包括双前置下划线)禁止导入,类对象和子类可以访问(protect) |
|
__xx |
双前置下划线,避免与子类中的属性命名冲突,无法在外部直接访问(名字重整所以访问不到),父类中属性名为__名字的,子类不继承,子类不能访问,如果在子类中向__名字赋值,那么会在子类中定义的一个与父类相同名字的属性(private) |
|
__xx__ |
双前后下划线,用户名字空间的魔法对象或属性。例如:__init__ , __ 不要自己发明这样的名字 |
|
xx_ |
单后置下划线,用于避免与Python关键词的冲突 |
# test.py num = 100 _num = 200 __num = 300 >>> from test import * >>> num 100 >>> _num Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name ‘_num‘ is not defined >>> __num Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name ‘__num‘ is not defined >>> import test >>> test.num 100 >>> test._num 200 >>> test.__num 300
# test.py class Person(object): def __init__(self,name = ‘haha‘,score = 80): self._name = name self.__score = score class Student(Person): pass >>> from test import * >>> Person._name Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: type object ‘Person‘ has no attribute ‘_name‘ >>> Person.__score Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: type object ‘Person‘ has no attribute ‘__score‘ >>> p = Person(‘hanmeimei‘,88) >>> p._name ‘hanmeimei‘ >>> p.__score # 私有属性,外部不能访问 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: ‘Person‘ object has no attribute ‘__score‘ >>> p._Person__score # 可通过 _Class__object 访问私有属性 88 >>> s = Student(‘lilei‘,60) >>> s._name # 子类可以访问 ‘lilei‘ >>> s.__scoer # 子类不能访问 Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: ‘Student‘ object has no attribute ‘__scoer‘ >>> s._Student__score Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: ‘Student‘ object has no attribute ‘_Student__score‘ >>> s._Person__score 60
property的使用:将方法进行封装
方式一
class Test(object): def __init__(self): self.__num = 100 def setNum(self,newNum): print("---setter---") self.__num = newNum def getNum(self): print("---getter---") return self.__num num = property(getNum,setNum) t = Test() t.num = 200 # 相当于调用 t.setNum(200) print(t.num) # 相当于调用 t.getNum() ‘‘‘ ---setter--- ---getter--- 200 ‘‘‘
方式二
class Test(object): def __init__(self): self.__num = 100 @property def num(self): print("---getter---") return self.__num @num.setter def num(self,newNum): print("---setter---") self.__num = newNum t = Test() t.num = 200 # 相当于调用 t.setNum(200) print(t.num) # 相当于调用 t.getNum() ‘‘‘ ---setter--- ---getter--- 200 ‘‘‘
class Student(object): @property def score(self): return self._score @score.setter def score(self, value): if not isinstance(value, int): raise ValueError(‘score must be an integer!‘) if value < 0 or value > 100: raise ValueError(‘score must between 0 ~ 100!‘) self._score = value
1) 小整数 [-5,257) 共用对象,常驻内存

2)单个字符共用对象,常驻内存

3)单个单词,不可修改,默认开启intern机制,共用对象,引用计数为0,则销毁 (python2)
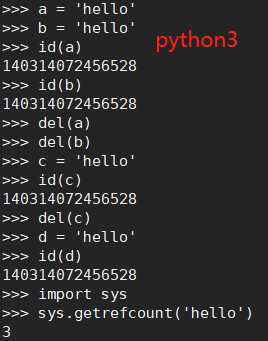
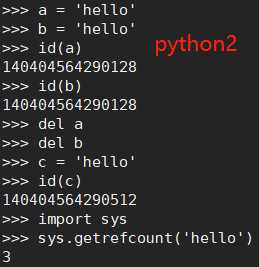
4)字符串(含有空格),不可修改,没开启intern机制,不共用对象,引用计数为0,销毁

5)大整数不共用内存,引用计数为0,销毁

6)数值类型和字符串类型在 Python 中都是不可变的,这意味着你无法修改这个对象的值,每次对变量的修改,实际上是创建一个新的对象

python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅(针对循环引用)的策略
1、导致引用计数+1的情况
2、导致引用计数-1的情况
3、查看一个对象的引用计数

可以查看a对象的引用计数,但是比正常计数大1,因为调用函数的时候传入a,这会让a的引用计数+1
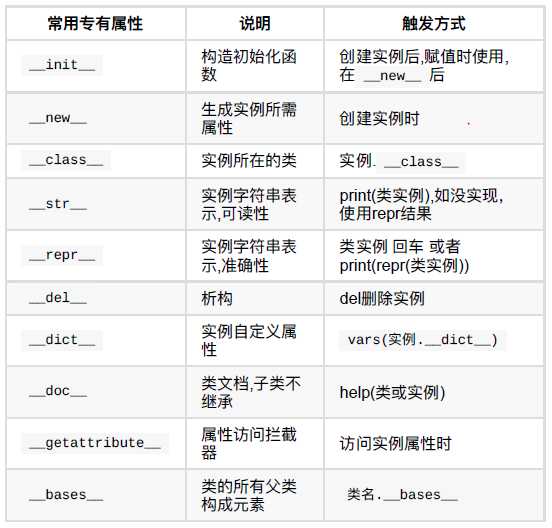
__getattribute__ 访问对象属性时触发
# 未重写__getattribute__方法时 class Course(object): def __init__(self,subject1): self.subject1 = subject1 self.subject2 = ‘cpp‘ s = Course("python") print(s.subject1) print(s.subject2) ‘‘‘ python cpp ‘‘‘ # 重写__getattribute__方法 class Course(object): def __init__(self,subject1): self.subject1 = subject1 self.subject2 = ‘cpp‘ # 属性访问拦截器,打印log def __getattribute__(self,obj): if obj == ‘subject1‘: print(‘subject1_log‘) return ‘python-python‘ else: return object.__getattribute__(self,obj) s = Course("python") print(s.subject1) print(s.subject2) ‘‘‘ subject1_log python-python cpp ‘‘‘ # 注释else,访问非subject1属性将返回None class Course(object): def __init__(self,subject1): self.subject1 = subject1 self.subject2 = ‘cpp‘ # 属性访问拦截器,打印log def __getattribute__(self,obj): if obj == ‘subject1‘: print(‘subject1_log‘) return ‘python-python‘ #else: # return object.__getattribute__(self,obj) s = Course("python") print(s.subject1) print(s.subject2) ‘‘‘ subject1_log python-python None ‘‘‘ class Course(object): def __init__(self,subject1): self.subject1 = subject1 self.subject2 = ‘cpp‘ def __getattribute__(self,obj): # 属性访问时拦截器,打log print("====1>%s" %obj) if obj == ‘subject1‘: print(‘log_subject1‘) return ‘python-python‘ else: temp = object.__getattribute__(self,obj) print("====2>%s" %str(temp)) return temp def show(self): print(‘hello......‘) s = Course("python") print(s.subject1) print(s.subject2) s.show() ‘‘‘ ====1>subject1 log_subject1 python-python ====1>subject2 ====2>cpp cpp ====1>show ====2><bound method Course.show of <__main__.Course object at 0x7fa4de183a20>> hello...... ‘‘‘
__getattribute__ 的坑
class Person(object): def __getattribute__(self, obj): print("---test---") if obj.startswith("a"): return "hahha" else: return self.test def test(self): print("heihei") t = Person() t.a # 返回hahha t.b # 会让程序死掉 ‘‘‘ (RecursionError: maximum recursion depth exceeded while calling a Python object) 原因是:当t.b执行时,会调用Person类中定义的__getattribute__方法,但是在这个方法的执行过程中 if条件不满足,所以 程序执行else里面的代码,即return self.test 问题就在这,因为return 需要把 self.test的值返回,那么首先要获取self.test的值,因为self此时就是t这个对象,所以self.test就是 t.test 此时要获取t这个对象的test属性,那么就会跳转到__getattribute__方法去执行,即此时产 生了递归调用,由于这个递归过程中 没有判断什么时候退出,所以这个程序会永无休止的运行下去,又因为 每次调用函数,就需要保存一些数据,那么随着调用的次数越来越多,最终内存吃光,所以程序 崩溃 注意:以后不要在__getattribute__方法中调用self.xxxx ‘‘‘
Build-in Function,启动python解释器,输入dir(__builtins__), 可以看到很多python解释器启动后默认加载的属性和函数,这些函数称之为内建函数, 这些函数因为在编程时使用较多,cpython解释器用c语言实现了这些函数,启动解释器时默认加载
range(start, stop[, step])
# python3 >>> from collections import Iterable >>> r = range(10) >>> r range(0, 10) >>> isinstance(r,Iterable) True >>> from collections import Iterator >>> isinstance(r,Iterator) False >>> r = iter(r) >>> r <range_iterator object at 0x7f538bfc9450> >>> isinstance(r,Iterator) True >>> next(r) 0 >>> next(r) 1 # python2 >>> range(10) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] >>> xrange(10) xrange(10)
map()
>>> ret = map(lambda x:x*x, [1,2,3]) >>> ret <map object at 0x7f5384b65908> >>> for item in ret: ... print(item) ... 1 4 9 >>> ret = map(lambda x,y:x+y, [1,2,3],[4,5,6]) >>> ret <map object at 0x7f538bf0ef60> >>> for item in ret: ... print(item) ... 5 7 9 >>> def func(x,y): ... return x + y ... >>> list1 = [1,2,3] >>> list2 = [4,5,6] >>> list3 = map(func,list1,list2) >>> list3 <map object at 0x7f53849476d8> >>> for item in list3: ... print(item) ... 5 7 9
filter()
filter函数会对序列参数sequence中的每个元素调用function函数,最后返回的结果包含调用结果为True的元素,返回值的类型和参数sequence的类型相同
>>> f = filter(lambda x:x%2, [1,2,3,4]) >>> f <filter object at 0x7f53849479e8> >>> for item in f: ... print(item) ... 1 3 >>> f = filter(None, [1,2,3]) >>> for item in f: ... print(item) ... 1 2 3
sorted()
>>> sorted([3,5,3,2,77,44,54]) [2, 3, 3, 5, 44, 54, 77] >>> sorted([‘n‘,‘c‘,‘m‘,‘b‘]) [‘b‘, ‘c‘, ‘m‘, ‘n‘] >>> sorted([4,2,6,‘a‘,‘m‘]) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: ‘<‘ not supported between instances of ‘str‘ and ‘int‘ >>> sorted([3,65,32,77,23],reverse=1) [77, 65, 32, 23, 3] >>> sorted((3,4,1)) [1, 3, 4]
reduce(function, sequence[, initial])
reduce(在python3中已被移除)依次从sequence中取一个元素,和上一次调用function的结果做参数再次调用function
>>> from functools import reduce >>> reduce(lambda x,y:x+y, [1,2,3]) 6 >>> reduce(lambda x,y:x+y, [1,2,3], 4) 10 >>> reduce(lambda x,y:x+y, [‘aa‘,‘bb‘,‘cc‘],‘dd‘) ‘ddaabbcc‘
集合与之前列表、元组类似,可以存储多个数据,但是这些数据是不重复的

集合运算

原文:https://www.cnblogs.com/brotherdong888/p/10664302.html