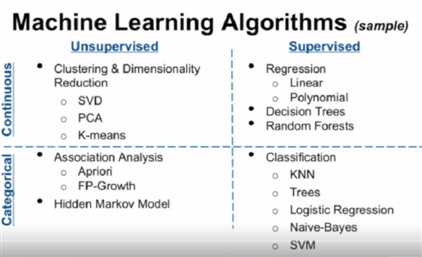
(from 七月在线-kaggle竞赛视频)。

(样本不均衡的坏处,如1:100,把数据都判断为负类,在训练时数据误差很低,但是预测时很不准确)
1)将正样本上采样(正样本重复若干次)
2)损失函数(加大正样本的loss)
3)把负样本分成10分,分别与正样本去训练。如bagging去投票
pandas:数据量大的时候,一个特征维度的去做。
hive sql / spark sql
缺省很小:填充
缺省很大:舍去
缺省适中:把缺省当作一个特征
当前数据域分布没有规律,可以变换到log域、指数域----可能数据会呈现一定的规律
时间类数据:间隔、与其他特征组合、离散型、时间段
文本型数据:n-gram、bag of words、TF-IDF、wordvec
统计型特征:min、max、中位数
preprocessing 以及 feature_extraction
https://scikit-learn.org/stable/modules/preprocessing.html
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.feature%20extraction

blending

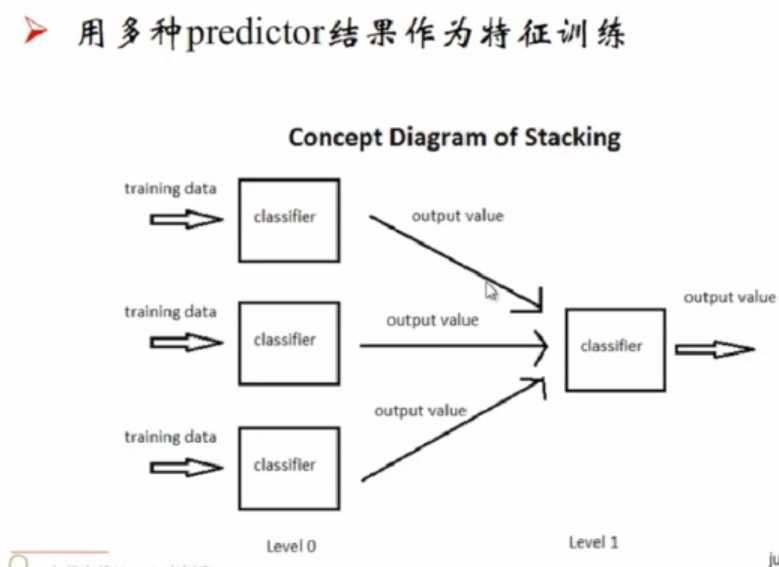
使用不同的分类器,产生不同的分类结果。将这些结果作为输入,

如果使用这些结果的的linear取加权平均。就是blending方法。(没有再sklearn中封装)
Adaboost: 调样本的权重
xgboost / lightgbm
https://www.zybuluo.com/hanxiaoyang/note/545131
https://github.com/dmlc/xgboost 有一些xgboost的demo
原文:https://www.cnblogs.com/GuoXinxin/p/10686887.html