motivation:
作者发现对图片进行降采样有时能有助于检测精度的提升。具体来说,图片降采样能带来两方面的提升:
1)减少false positive(fp)的数量,过多地关注图片上不必要的细节会引入false positive。
2)增加true positive(tp)的数量,通过对图片进行缩放将object缩放至目标检测器所能处理的合理的尺寸。
图1表明,在ImageNet VID数据集上用R-FCN检测时,将图片进行下采样之后能得到更好的检测效果。
受此启发,作者提出了AdaScale用于现存的目标检测器上,用于将图片自适应地缩放至一个最佳尺寸,来得到更高的速度和精度。
具体来说,作者使用当前帧来预测下一帧的最佳尺寸。

Adaptive Scaling:
图2是AdaScale方法的概况。其中包含fine-tuning目标检测器,使用所得到的检测器来生成最优尺寸的label,用上一步生成的label训练一个scale regressor,以及将AdaScale部署在视频目标检测框架中。

optical scale:
首先定义一个有限的尺寸集合,本文S={600,480,360,240},这里S指图片最短边的像素数量。并选用目标检测器训练时的损失函数(1)作为度量,以此来衡量最优的scale。
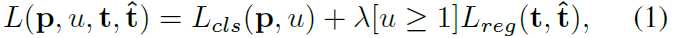
但直接使用损失函数会有这样一个问题,当预测得到的proposal和groundtruth的IoU较低时,会被分类为background,此时的损失函数中的回归损失为0,直接用该指标衡量不同图像尺寸会有问题,
该评价指标会比较喜欢前景框更少的图片尺寸,因为当前景框少时损失函数的值也会更小。
因此作者设计了一个新的评价指标,这个评价指标仅关注不同图片尺寸中的相同number的前景框。下面具体地来介绍这个评价指标:
设置\(L_{i,a}^m,\quad m\in S\)为利用公式(1)计算的图片i在尺度m上预测的bbox a的损失,设\(\hat{L_i^m},\quad m\in S\)为在图片i在尺度m下计算出的新的评价指标。
为了得到\(\hat{L_i^m}\), 首先计算预测的前景bbox的数量,\(n_{m,i}\)为图片i在任意尺度m的值,令\(n_{min,i}=min_{m}(n_{m,i})\). 然后得到我们提出的评价指标:
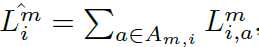
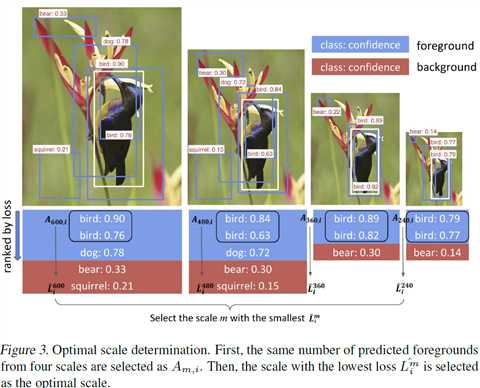
其中\(A_{m,i}\)是图片i在尺度m是预测得到的前景框集合,且\(|A_{m,i}|=n_{min,i}\).为了得到\(A_{m,i}\),对每一个scale,我们对预测的前景框按\(L_{i,a}^m\)进行排序,然后将第一个\(n_{min,i}\)预测加入集合\(A_{m,i}\。
这一过程在图3进行了可视化,得到图片i的最优尺寸公式:
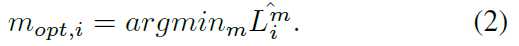
AdaScale: Towards Real-time video object detection using adaptive scaling
原文:https://www.cnblogs.com/hf19950918/p/10688839.html