一。pipeline
一个典型的机器学习过程从数据收集开始,要经历多个步骤,才能得到需要的输出。这非常类似于流水线式工作,即通常会包含源数据ETL(抽取、转化、加载),数据预处理,指标提取,模型训练与交叉验证,新数据预测等步骤。
在介绍工作流之前,我们先来了解几个重要概念:
Estimator:翻译成估计器或评估器,它是学习算法或在训练数据上的训练方法的概念抽象。在 Pipeline 里通常是被用来操作 DataFrame 数据并生产一个 Transformer。从技术上讲,Estimator实现了一个方法fit(),它接受一个DataFrame并产生一个转换器。如一个随机森林算法就是一个 Estimator,它可以调用fit(),通过训练特征数据而得到一个随机森林模型。
Parameter:Parameter 被用来设置 Transformer 或者 Estimator 的参数。现在,所有转换器和估计器可共享用于指定参数的公共API。ParamMap是一组(参数,值)对。
PipeLine:翻译为工作流或者管道。工作流将多个工作流阶段(转换器和估计器)连接在一起,形成机器学习的工作流,并获得结果输出。
工作流如何工作
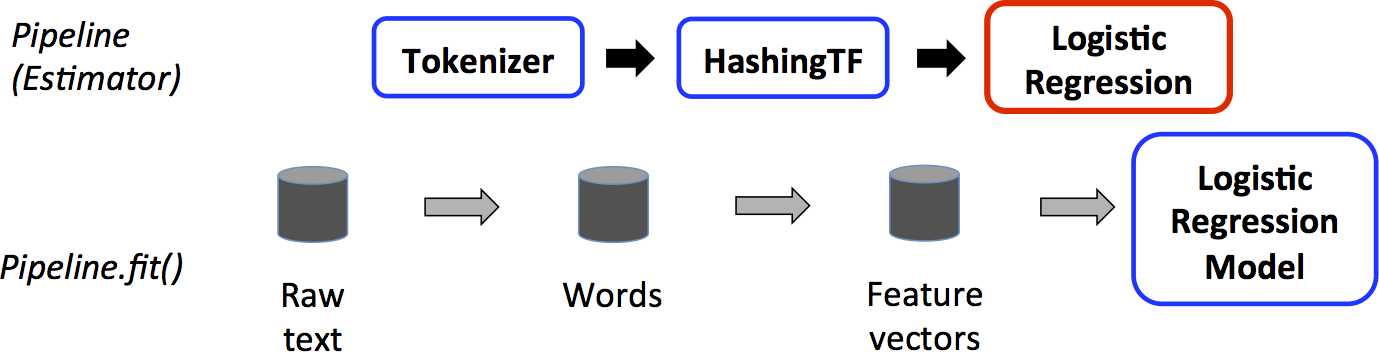
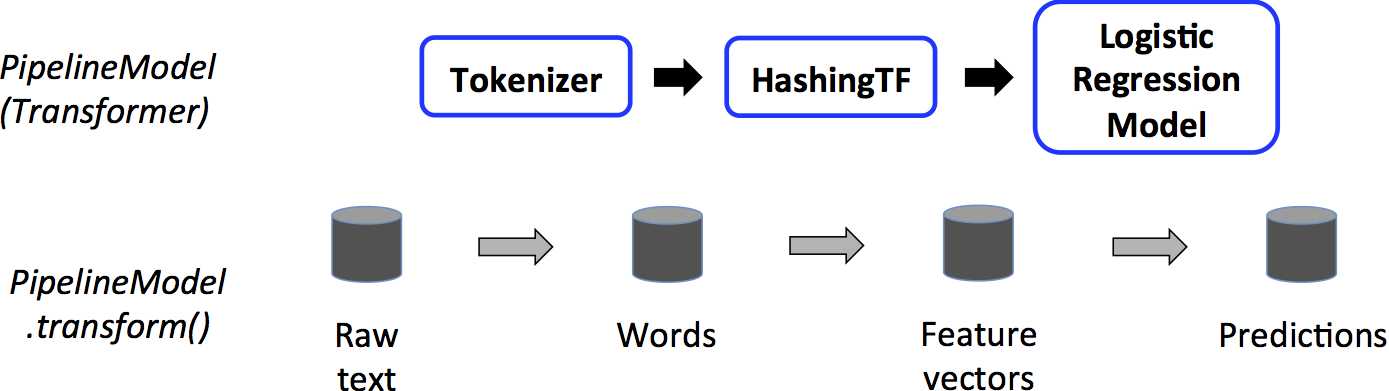
二。构建 ml pipeline
Spark2.0起,SQLContext、HiveContext已经不再推荐使用,改以SparkSession代之,故本文中不再使用SQLContext来进行相关的操作,关于SparkSession的具体详情,这里不再赘述,可以参看Spark2.0的官方文档
Spark2.0以上版本的pyspark创建一个名为spark的SparkSession对象,当需要手工创建时,SparkSession可以由其伴生对象的builder()方法创建出来
from pyspark.ml import Pipeline from pyspark.ml.classification import LogisticRegression from pyspark.ml.feature import HashingTF, Tokenizer # Prepare training documents from a list of (id, text, label) tuples. training = spark.createDataFrame([ (0, "a b c d e spark", 1.0), (1, "b d", 0.0), (2, "spark f g h", 1.0), (3, "hadoop mapreduce", 0.0) ], ["id", "text", "label"]) tokenizer = Tokenizer(inputCol="text", outputCol="words") hashingTF = HashingTF(inputCol=tokenizer.getOutputCol(), outputCol="features") lr = LogisticRegression(maxIter=10, regParam=0.001) pipeline = Pipeline(stages=[tokenizer, hashingTF, lr]) model = pipeline.fit(training) test = spark.createDataFrame([ (4, "spark i j k"), (5, "l m n"), (6, "spark hadoop spark"), (7, "apache hadoop") ], ["id", "text"]) prediction = model.transform(test) selected = prediction.select("id", "text", "probability", "prediction") for row in selected.collect(): rid, text, prob, prediction = row print("(%d, %s) --> prob=%s, prediction=%f" % (rid, text, str(prob), prediction)) //输出 (4, spark i j k) --> prob=[0.155543713844,0.844456286156], prediction=1.000000 (5, l m n) --> prob=[0.830707735211,0.169292264789], prediction=0.000000 (6, spark hadoop spark) --> prob=[0.0696218406195,0.93037815938], prediction=1.000000 (7, apache hadoop) --> prob=[0.981518350351,0.018481649649], prediction=0.000000
通过上述结果,我们可以看到,第4句和第6句中都包含”spark”,其中第六句的预测是1,与我们希望的相符;而第4句虽然预测的依然是0,但是通过概率我们可以看到,第4句有46%的概率预测是1,而第5句、第7句分别只有7%和2%的概率预测为1,这是由于训练数据集较少,如果有更多的测试数据进行学习,预测的准确率将会有显著提升。
原文:https://www.cnblogs.com/dhName/p/10700132.html