有向图强连通分量就是在一个强连通分量里面,每个点都能到达分量里面其他所有点。
那么,如何求?
我们定义一个low数组与一个dfs数组与一个ts(时间戳,不需要过多理解,下文看了就知道功能了)
我们要明白Tarjan算法其实就是利用DFS序来完成工作的。
而且一个点只能在一个强连通分量里面。
首先,我们找到一个点x,然后\(low[x]=dfs[x]=++ts\),这个时候,然后我们用x继续去找其他点。
找到了一个没被找过的点(\(dfn[y]==0\)),对y进行dfs
于是我们得到了一个DFS序

那么,现在怎么做?
dfn是存DFS序的,那么low呢?
LOOK
4现在找到了3,发现3并没有在一个已经找完的强连通分量里面,说明什么?(现在可能看不懂,看下去就懂了)
1、 3号点在DFS树中是4的祖先,3还没便历完,这个时候,3可以沿着DFS树中的边到4,4也可以到3,岂不妙哉?于是我们可以知道DFS树中3->4上所有的点都是一个分量里的,这个时候,我们用low[4]=dfn[3]。
2、 3号点在DFS树上是4的祖先的另外一个分支,但是3并没在一个分量里面,而且按照DFS的规则,只有便利完一个分支才能便历另一个分支,所以,3肯定与3、4的最近共同祖先是一个分量里的,那么,祖先可以到4,而4也可以先走到3在走到祖先,那么low[4]=dfn[3](注:3先被发现,所以DFS序要小),情况大概如下图。

3、 3号点为4号点的DFS树中儿子,其实不能说是找到了儿子,毕竟如果他没被找过,找到了,3号才是4号儿子,如果3号被找过了,那么3号应该是别人儿子(除非有重边),就是情况2,那我们就考虑假设找到一个没被找过的点怎么办?
先DFS一遍3,发现3还是没有在一个已经找完的强连通分量,说明3的low指向的是4甚至更高的祖先,难道我们又要让low[x]=low[y]?但是,既然是儿子的,我们为什么不能在他DFS完后\(low[x]=min(low[x],low[y]);\)岂不妙哉?
4、4找到了孙子或更低的3,这时,4找完了儿子,儿子也认4为儿子...,总之4在3下面,所以4找过了,老道理,4还是在一个已经找完的强连通分量,但是我们不能像以前\(low[4]=dfn[3]\)了,因为3的DFS序大于4的,我们会发现,一个点的low必须小于等于dfn,难道要\(low[4]=low[3]\),不用,我们会发现,等4的儿子便历完后传回来的low[y],其实就已经包括了\(low[3]\)了,所以我们只需让\(low[4]=min(low[4],dfn[3])\)
那么,通过上面我们可以知道,如果我们找到了一个点,没被找过,我们就让他去DFS,并且更新,找过了,但所在的分量没更新完,也是这样更新。
重点来了。
一个分量怎样算找完?
我们设立一个栈,每次找到一个点就把他推入栈,当\(low[x]==dfn[x]\)时,我们就把x包括x以上所有点算在一个分量里面,想想就知道,这时可行的。
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
int belong[61000],dfn[61000],cnt,low[61000],n,m,id;
struct node
{
int y,next;
}a[210000];int len,last[61000];
void ins(int x,int y)
{
len++;
a[len].y=y;a[len].next=last[x];last[x]=len;
}//边目录
int sta[61000],p;//栈
bool v[61000];//所在的分量找完没?
void dfs(int x)
{
dfn[x]=low[x]=++id;sta[++p]=x;
for(int k=last[x];k;k=a[k].next)
{
int y=a[k].y;
if(dfn[y]==0)
{
dfs(y);//便历
low[x]=min(low[x],low[y]);
}
else if(v[y]==false)low[x]=min(low[x],dfn[y]);//low[x]=min(low[x],low[y]);也不会错
}
if(low[x]==dfn[x])
{
int now=0;cnt++;
do
{
now=sta[p--];
v[now]=true;//找完了
belong[now]=cnt;//所在的分量
}while(now!=x && p>0);
}
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++)
{
int x,y;scanf("%d%d",&x,&y);
ins(x,y);
}
for(int i=1;i<=n;i++)
{
if(dfn[i]==0)dfs(i);//便历
}
printf("%d\n",cnt);
return 0;
}这道题目难度有点大,我们做一遍Tarjan算法,然后把每个强连通分量当成一个点,计算每个点的入度与出度,我们需要知道,为什么这些点(我们已经把所有强连通分量缩点了)不在一个强连通分量里面?
比如:
我们可以姑且的认为,一个长得像\(1->2->3->4->...\)的点叫伪点(非专业术语)
而一个伪点一般有一个点入度为0,一个点出度为0,当然,即使有特殊情况使得某个为0也是没问题的,代表他和其他伪点已经有联系了。
那么,我们只需要把一个伪点没入度的连向没出度的(当然,只有一个分量的话要特判,直接输出0),也就是max(rdcnt,cdcnt)。
虽然很难理解,但是画以下图就知道了。
#include<cstdio>
#include<cstring>
#include<cstdlib>
using namespace std;
int flog[21000],fa[21000],biao[21000],id,n,m,cnt,t;
struct node
{
int x,y,next;
}a[51000];int last[21000],len,list[21000],top;
bool v[21000];
void ins(int x,int y)
{
len++;
a[len].x=x;a[len].y=y;a[len].next=last[x];last[x]=len;
}
inline int mymin(int x,int y){return x<y?x:y;}
inline int mymax(int x,int y){return x>y?x:y;}
void dfs(int x)
{
fa[x]=biao[x]=++id;
list[++top]=x;v[x]=true;
for(int k=last[x];k;k=a[k].next)
{
int y=a[k].y;
if(biao[y]==0)
{
dfs(y);
fa[x]=mymin(fa[x],fa[y]);
}
else
{
if(v[y]==true)fa[x]=mymin(fa[x],fa[y]);
}
}
if(biao[x]==fa[x])
{
int i=0;cnt++;
while(i!=x)
{
i=list[top--];
flog[i]=cnt;
v[i]=false;
}
}
}
int rd[21000],cd[21000];
int main()
{
//freopen("b.in","r",stdin);
//freopen("1.out","w",stdout);
scanf("%d",&t);
while(t--)
{
memset(fa,0,sizeof(fa));
memset(biao,0,sizeof(biao));cnt=0;len=0;id=0;
memset(last,0,sizeof(last));top=0;
memset(rd,0,sizeof(rd));memset(cd,0,sizeof(cd));
scanf("%d%d",&n,&m);
int ans1=0,ans2=0;
for(int i=1;i<=m;i++)
{
int x,y;scanf("%d%d",&x,&y);
ins(x,y);
}
for(int i=1;i<=n;i++)
{
if(biao[i]==0)dfs(i);
}
if(cnt==1)
{
printf("0\n");
continue;
}
for(int i=1;i<=m;i++)
{
int tx=flog[a[i].x]/*缩点*/,ty=flog[a[i].y];
if(tx!=ty)
{
rd[ty]++;cd[tx]++;
}
}
for(int i=1;i<=cnt;i++)
{
if(rd[i]==0)ans1++;
if(cd[i]==0)ans2++;
}
printf("%d\n",mymax(ans1,ans2));
}
return 0;
}我们先跑一遍二分匹配,然后把原本的边反向建(母牛连向公牛),并且连一条边,公牛连向他匹配的母牛,那么再跑一边强连通,我们就会发现每个分量里面都是公牛->母牛->公牛->母牛...
也就是说每个母牛至少有两个选择,公牛也是,然后我们在找公牛能****(手动打码)的每个母牛,如果母牛跟公牛在同一分量中,那么这个母牛原本的公牛也可以在找另外一头母牛,是不是很厉害?
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<bitset>
using namespace std;
const int cc=4010;
struct node
{
int y,next;
}a[200010];int len,last[cc];
struct trlen
{
int x,y,next;
}map[200010];int tlen,tlast[cc];
int cnt,id,p;
int sta[cc],low[cc],dfn[cc],belong[cc];
int chw[cc],match[cc],n;
bool v[cc];
void ins(int x,int y)
{
len++;
a[len].y=y;a[len].next=last[x];last[x]=len;
}
void ins1(int x,int y)
{
tlen++;
map[tlen].x=x;map[tlen].y=y;map[tlen].next=tlast[x];tlast[x]=tlen;
}
bool find(int x)
{
for(int k=tlast[x];k;k=map[k].next)
{
int y=map[k].y;
if(chw[y]!=id)
{
chw[y]=id;
if(match[y]==0 || find(match[y])==true)
{
match[y]=x;
return true;
}
}
}
return false;
}
void dfs(int x)
{
low[x]=dfn[x]=++id;v[x]=true;sta[++p]=x;
for(int k=last[x];k;k=a[k].next)
{
int y=a[k].y;
if(low[y]==0)
{
dfs(y);
low[x]=min(low[x],low[y]);
}
else if(v[y]==true)low[x]=min(low[x],dfn[y]);
}
if(low[x]==dfn[x])
{
int now=0;cnt++;
do
{
now=sta[p--];
v[now]=false;
belong[now]=cnt;
}while(now!=x);
}
}
int main()
{
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
int kkk=0;scanf("%d",&kkk);
for(int j=1;j<=kkk;j++)
{
int x;scanf("%d",&x);
ins1(i,x+n);
}
}
for(int i=1;i<=n;i++)
{
id++;
find(i);
}//二分匹配
for(int i=1;i<=n;i++)ins(match[i+n],i+n);
for(int i=1;i<=tlen;i++)ins(map[i].y,map[i].x);
for(int i=1;i<=n;i++)
{
if(low[i]==0)dfs(i);
}
for(int i=1;i<=n;i++)
{
int jj=belong[i],ansl[cc];
ansl[0]=0;
for(int j=tlast[i];j;j=map[j].next)
{
if(belong[map[j].y]==jj)ansl[++ansl[0]]=map[j].y-n;
}
sort(ansl+1,ansl+1+ansl[0]);
for(int j=1;j<ansl[0];j++)printf("%d ",ansl[j]);
printf("%d\n",ansl[ansl[0]]);
}
//输出
return 0;
}这道题比较简单,如果一个强连通分量有边连向其他分量,这个分量都没用了。
#include<cstdio>
#include<cstring>
using namespace std;
inline int mymin(int x,int y){return x<y?x:y;}
int n,m;
int low[21000],dfn[21000],belong[21000],cnt,out[21000],stp;
int sta[21000],tp=0;bool v[21000];
struct node
{
int x,y,next;
}a[21000];int last[21000],len;
int ansl[21000];
void ins(int x,int y)
{
len++;
a[len].x=x;a[len].y=y;a[len].next=last[x];last[x]=len;
}
void dfs(int x)
{
low[x]=dfn[x]=++stp;v[x]=true;sta[++tp]=x;
for(int k=last[x];k;k=a[k].next)
{
int y=a[k].y;
if(low[y]==0)
{
dfs(y);
low[x]=mymin(low[x],low[y]);
}
else if(v[y]==true)low[x]=mymin(low[x],dfn[y]);
}
if(low[x]==dfn[x])
{
int now=0;cnt++;
while(now!=x)
{
now=sta[tp--];
belong[now]=cnt;
v[now]=false;
}
}
}
int main()
{
memset(v,true,sizeof(v));
while(scanf("%d",&n)!=EOF)
{
if(n==0)break;
scanf("%d",&m);
memset(low,0,sizeof(low));stp=0;
memset(last,0,sizeof(last));len=0;
memset(out,0,sizeof(out));
for(int i=1;i<=m;i++)
{
int x,y;scanf("%d%d",&x,&y);
ins(x,y);
}
for(int i=1;i<=n;i++)
{
if(low[i]==0)dfs(i);
}
for(int i=1;i<=m;i++)
{
if(belong[a[i].x]!=belong[a[i].y])out[belong[a[i].x]]++;
}
for(int i=1;i<=n;i++)
{
if(out[belong[i]]==0)ansl[++ansl[0]]=i;
}
for(int i=1;i<ansl[0];i++)printf("%d ",ansl[i]);
printf("%d\n",ansl[ansl[0]]);ansl[0]=0;
}
return 0;
}双联通分量就是无向图的强连通分量
如果原本两个点是连通的,截断一条边就使得两个点不联通了,这条边叫桥。
又是这个巨佬,边-双连通就是没有桥的分量,比如:1-2-3-1,有桥吗?没有吧。
那么,怎么做成了关键,再看Tarjan过程,我们得设立个条件,儿子不能到达父亲,然后继续看。
原本的Tarjan算法可不可以再次利用,我们继续看。
原本的强连通分量长这样:1->2->3->1
但是如果单向边全变成双向边,貌似就是边-双连通了呢。
而且我们规定儿子不能到父亲,也就是没有1-2的情况,那么就成了!
并且\(if(!v[x])\)可以去掉,为什么?因为这是无向边,不用你去找他,他就已经找了你了,如果你又找到了他,那你们肯定是一个分量的呀
这次没例题,直接放练习
像上次那样,我们记录每个分量的度(无向边),为0,ans+=2,为1,ans++
然后答案为ans/2+ans%2
#include<cstdio>
#include<cstring>
using namespace std;
inline int mymin(int x,int y){return x<y?x:y;}
int low[6000],dfn[6000],belong[6000],cnt,stp;
int sta[6000],tp;
struct node
{
int x,y,next;
}a[21000];int last[6000],len;
int ax[11000],ay[11000],n,m,io[11000],ans;
void ins(int x,int y)
{
len++;
a[len].x=x;a[len].y=y;a[len].next=last[x];last[x]=len;
}
void dfs(int x,int fa)
{
low[x]=dfn[x]=++stp;
sta[++tp]=x;
for(int k=last[x];k;k=a[k].next)
{
int y=a[k].y;
if(y!=fa)
{
if(low[y]==0)
{
dfs(y,x);
low[x]=mymin(low[x],low[y]);
}
else low[x]=mymin(low[x],dfn[y]);
}
}
if(low[x]==dfn[x])
{
int now=0;cnt++;
while(now!=x)
{
now=sta[tp--];
belong[now]=cnt;
}
}
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++)
{
scanf("%d%d",&ax[i],&ay[i]);
ins(ax[i],ay[i]);ins(ay[i],ax[i]);
}
for(int i=1;i<=n;i++)
{
if(low[i]==0)dfs(i,0);
}
if(cnt==1){printf("0\n");return 0;}//特判
for(int i=1;i<=m;i++)
{
if(belong[ax[i]]!=belong[ay[i]])io[belong[ax[i]]]++,io[belong[ay[i]]]++;
}
for(int i=1;i<=cnt;i++)
{
if(io[i]==0)ans+=2;
else if(io[i]==1)ans++;
}
printf("%d\n",ans/2+ans%2);
return 0;
}点强联通太活跃了,要根据具体题目具体定。
而且一个点强连通分量一定是个边强连通分量
一个点可能属于多个点连通,但只能属于一个边连通
就是把点割掉后,原本相连两个点(不是被割掉的点)不相连了,就割点。
这有什么好怕的?这还真的就有这么可怕。
没有例题。
自己创吧:
在一个无向图,输出所有的点双连通分量。
输入:
第一行输入点数、边数
接下来边数行,每行x,y描述一条边。
输出:
第一行,点双连通分量数量。
接下来每行输出一个点双连通分量。
输入样例:
5 6
1 2
2 3
3 1
3 4
4 5
3 5
输出样例:
2
1 2 3
3 4 5
怎么做,我们还是一个同样的味道,Tarjan算法。
比较麻烦的事,在点分量中,一个点可以重复。
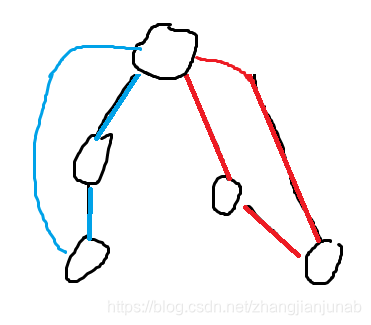
我们发现,在边分量里面,红蓝是同一分量,但是在点分量里面,是两个分量,我们容易知道,只要一个点x的儿子y的low等于x的dfn,那么x与y这颗字树同属于一个点双连通分量。
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
int dfn[61000],cnt,low[61000],n,m,id;
struct node
{
int y,next;
}a[210000];int len,last[61000];
void ins(int x,int y)
{
len++;
a[len].y=y;a[len].next=last[x];last[x]=len;
}
int sta[61000],p;
int ans[130000],wl[61000],wr[61000];
void dfs(int x,int fa)
{
dfn[x]=low[x]=++id;sta[++p]=x;
for(int k=last[x];k;k=a[k].next)
{
int y=a[k].y;
if(y!=fa)
{
if(dfn[y]==0)
{
dfs(y,x);
low[x]=min(low[x],low[y]);
if(low[y]==dfn[x])//刚好到我这里,那么你是一个点强连通
{
int now=0;cnt++;
wl[cnt]=ans[0]+1;
while(now!=x && p>0)
{
now=sta[p--];
ans[++ans[0]]=now;
}
wr[cnt]=ans[0];
sta[++p]=x;//如果我能到我的上级,我还可以包括在我的上级的分量里
}
}
else low[x]=min(low[x],dfn[y]);
}
}
if(low[x]==dfn[x])//我到不了上面,算了吧。
{
p--;
}
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++)
{
int x,y;scanf("%d%d",&x,&y);
ins(x,y);ins(y,x);
}
for(int i=1;i<=n;i++)
{
if(dfn[i]==0)dfs(i,0);
}
printf("%d\n",cnt);
for(int i=1;i<=cnt;i++)
{
for(int j=wl[i];j<wr[i];j++)printf("%d ",ans[j]);
printf("%d\n",ans[wr[i]]);
}
return 0;
}我们研究DFS序就会发现,只要一个不是根结点的其中一个儿子的low全部小于等于他的dfn,那么这个点就是割点,根节点就是他的子树数量大于等于两颗就是割点。
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
int dfn[61000],low[61000],n,m,id;
struct node
{
int y,next;
}a[210000];int len,last[61000];
void ins(int x,int y)
{
len++;
a[len].y=y;a[len].next=last[x];last[x]=len;
}
int sta[61000],p;
int ans[130000];
void dfs(int x,int fa)
{
bool bk=false;int cnt=0;
dfn[x]=low[x]=++id;sta[++p]=x;
for(int k=last[x];k;k=a[k].next)
{
int y=a[k].y;
if(y!=fa)
{
if(dfn[y]==0)
{
cnt++;
dfs(y,x);
low[x]=min(low[x],low[y]);
if(low[y]>=dfn[x]/*桥就是>*/)bk=true;
}
else low[x]=min(low[x],dfn[y]);
}
}
if(low[x]==dfn[x])
{
int now=0;
while(now!=x)now=sta[p--];
}
if(!fa)//根节点特判
{
if(cnt>=2)ans[++ans[0]]=x;
}
else if(bk==true)ans[++ans[0]]=x;
}
int main()
{
scanf("%d%d",&n,&m);
for(int i=1;i<=m;i++)
{
int x,y;scanf("%d%d",&x,&y);
ins(x,y);ins(y,x);
}
for(int i=1;i<=n;i++)
{
if(dfn[i]==0)dfs(i,0);
}
sort(ans+1,ans+ans[0]+1);
printf("%d\n",ans[0]);
for(int i=1;i<ans[0];i++)printf("%d ",ans[i]);
if(ans[0])printf("%d\n",ans[ans[0]]);
return 0;
}其实就是low不是大于等于dfn了,而是大于,以及根节点不用特判(毕竟找的是边),然后就没有然后了。
又水了一篇博客
原文:https://www.cnblogs.com/zhangjianjunab/p/10701255.html