机器学习
针对经验E和一系列任务T和一定表现的衡量P,如果随着经验E的积累,针对定义好的任务T可以提高其表现P,则说明机器有学习能力
Sklearn库 基本使用
包含了所有机器学习算法 ——> 分类 回归 非监督分类 数据降维 数据预处理
1. 构建机器学习模型
A. 逻辑回归
B. 支持向量机
C. 决策树
D. 神经网络
在给定的数据上做解决分类的问题
导入样本数据

代码:
from sklearn import datasets
wine = datasets.load_wine()
print(wine)
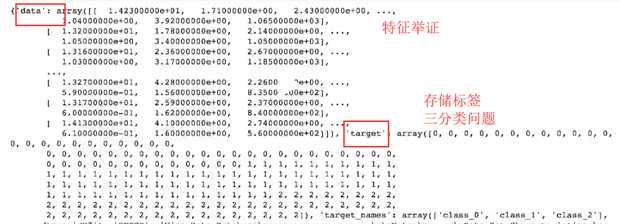
补充:y是样本的标签!每个分类的个数是类似的,所以不会存在不平衡的问题!
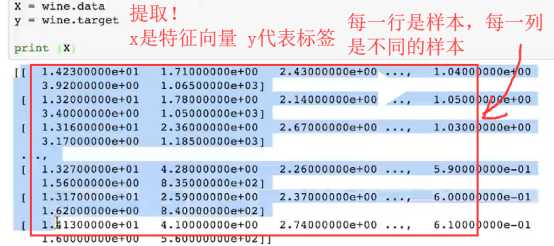
通过numpy包的shape()方法输入data和target的大小:

代码:
import numpy as np
print(np.shape(x),np.shape(y))
其中,
(178,13)----代表178*13的矩阵【意思是178个样本,每个样本有13个特征(或13个特征矩阵)】
(178,) -----代表长度是178的一个一维向量
把数据分成训练数据和测试数据 -----搭建模型后用一种机制评估模型

代码:
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.2,random_state=42)
print(np.shape(x_train),np.shape(x_test))
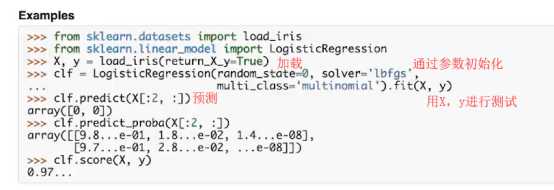
用sklearn搭建 逻辑回归模型 并在数据上训练+测试
代码:
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
X,y = load_iris(return_X_y=True)
clf = LogisticRegression(random_state=0,solver=‘lbfgs‘,multi_class=‘multinomial‘).fit(X,y)
clf.predict(X[:2,:])
clf.predict_proba(X[:2,:])
clf.score(X,y)
在y数据上搭建逻辑回归模型:
1. 加入相应的库
2. 初始化一个逻辑回归模型并训练
3. 评估模型表现

代码:
print("利用逻辑回归模型来做训练")
from sklearn.linear_model import LogisticRegression
model = LogisticRegression().fit(x_train,y_train)
print("训练数据上的准确率为:%f" % (model.score(x_train,y_train)))
print("测试数据上的准确率为:%f" % (model.score(x_test,y_test)))
使用逻辑回归提示FutureWarning:Specify a solver to silence warning的解决:
https://cloud.tencent.com/developer/news/397742
通过sklearn搭建支持向量机模型

代码:
import numpy as np
x = np.array([[-1,-1],[-2,-1],[1,1],[2,1]])
y = np.array([1,1,2,2])
from sklearn.svm import SVC
clf = SVC(gamma=‘auto‘)
clf.fit(x,y)
print(clf.predict([[-0.8,-1]]))
重要参数:
1.kernel ---和函数,任何时候都要用【线性~非线性~】
2.gamma ----调值至max优

代码:
print("利用支持向量机模型来做训练")
from sklearn import svm
model = svm.SVC().fit(x_train,y_train)
print("训练数据上的准确率为:%f" % (model.score(x_train,y_train)))
print("测试数据上的准确率为:%f" % (model.score(x_test,y_test)))
构建决策树模型

代码:
print("利用决策树模型来做训练")
from sklearn import tree
model = tree.DecisionTreeClassifier().fit(x_train,y_train)
print("训练数据上的准确率为:%f" % (model.score(x_train,y_train)))
print("测试数据上的准确率为:%f" % (model.score(x_test,y_test)))
搭建神经网络模型
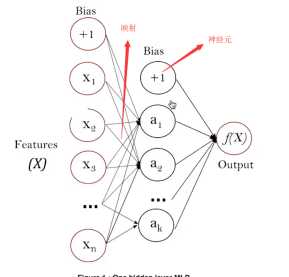

代码:
print("利用神经网络模型来做训练")
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(alpha=1e-5,hidden_layer_sizes=(200),solver=‘lbfgs‘,random_state=1).fit(x_train,y_train)
print("训练数据上的准确率为:%f" % (model.score(x_train,y_train)))
print("测试数据上的准确率为:%f" % (model.score(x_test,y_test)))
AI评估方法
准确率

不适合于:不均衡样本 比如90%+ 负-10%
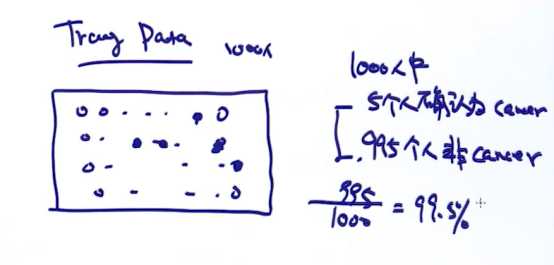
【即没经过学习,根据现象直接预测】
精确率+召回率

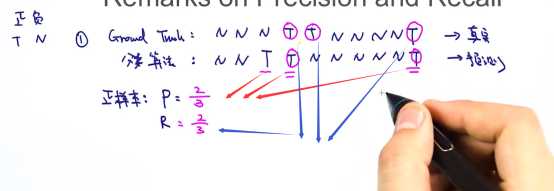
精确率:真正的正样本 / 分类(预测)的总正样本数
召回率:被发现的正样本 / 总真正的正样本数
二者之间互斥!!!! 不可兼得,一个增,另一个必然减 ——> 最佳点! 阈值点
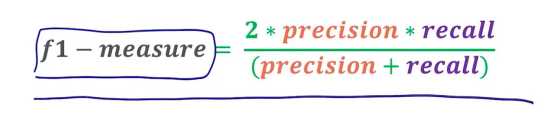
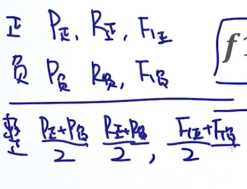
练习:

原文:https://www.cnblogs.com/expedition/p/10703629.html