正则表达式用来匹配字符串的 在python中通过re模块实现 完成模糊匹配
正则表达式中的元字符 11个
. 通配符代表所有的字符 一个点只代表一个字符 . 可以匹配除了换行符(\n)以外的任意一个字符
^ 只在字符串开始去匹配 其他位置有 不管
$ 只在字符结束去匹配,其他位置不管
* 重复匹配 重复前面的一个字符多次 0到多次 a* 等价于 {0,正无穷}
+ 重复匹配 重复前面的一个字符1到无穷多个 a+ z 等价于{1,正无穷}
?只能取0或1 对前面的一个字符 等价于{0,1}
{ } 匹配自己定义的数次 a{5} 五次 a{1,3}一次 两次 三次 贪婪匹配 p匹配最多的
[ ] 字符集 a[c,d]x cd中二选一 匹配acx adx 但不能匹配acdx [a-z]表示一个范围中随便取一个
取消元字符的特殊功能 [w,*] 这样就可以匹配*号了 \ ^ - 这三个字符例外
在[]中不用写逗号, 写了逗号之后,逗号也会进入匹配的行列
[^t]匹配除t以外的所有字符 [^4,5]匹配除(4,5,,)以外的所有字符
| 或 指明两项之间的一个选择
() 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用
\ 反斜杠后边跟元字符去除特殊功能 跟普通字符实现特殊功能
\d 匹配任何十进制数字 相当于[0-9]
\D 匹配任何非数字字符 相当于[^0-9]
\s 匹配任何空白字符 相当于[\t\n\r\f\v]
\S 匹配任何非空白字符 相当于[^\t\n\r\f\v]
\w 匹配任何字母数字字符 相当于[0-9a-zA-Z]
\W 匹配任何非字母数字字符 相当于[^0-9a-zA-Z]
\b 匹配一个特殊字符边界 也就是指字符和特殊字符间的位置
前面要加上r 的原因 是因为\b在python解释器中存在特殊意义 要加上r把原生字符串输入进去
类似于后面对\的匹配
ret = re.findall(r‘I\b‘, ‘I am a boyIa‘)
print(ret)
ret = re.findall(r‘\bI‘, ‘ I am a boyIa‘)
print(ret)
[‘I‘]
[‘I‘]
[a-z] //匹配所有的小写字母
[A-Z] //匹配所有的大写字母
[a-zA-Z] //匹配所有的字母
[0-9] //匹配所有的数字
[0-9\.\-] //匹配所有的数字,句号和减号
[ \f\r\t\n] //匹配所有的白字符
#匹配除满足条件的第一个结果 ret=re.search(‘sb‘, ‘sbtring, flagssb‘) print(ret.group()) sb
关于匹配\图解
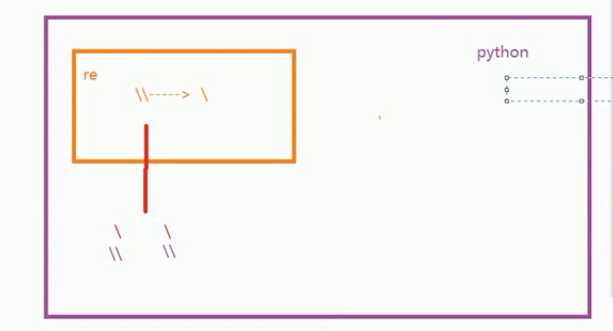
由于python解释器和re解释器中的\都有特殊意义 。 当‘\\\\‘传入python解释器中 实际传入re解释器中的就只有‘\\‘
当加上r‘\\‘ 传入python解释器的就不会变化 还是\\
原文:https://www.cnblogs.com/zhwforever/p/10705816.html