spark项目中通常我们需要将我们处理之后数据保存到文件中,比如将处理之后的RDD保存到hdfs上指定的目录中,亦或是保存在本地
1、rdd.saveAsTextFile("file:///E:/dataFile/result")
2、rdd.saveAsHadoopFile("file:///E:/dataFile/result",classOf[T],classOf[T],classOf[outputFormat.class])
3、df.write.format("csv").save("file:///E:/dataFile/result")
以上都简单的,最普遍的保存文件的方式,有时候是不能够满足我们的需求,上述的文件保存方式中,保存之后,文件名通常是part-00000的方式保存在result文件夹中,但是,我希望能够根据需求自己来定义这个文件名,并且指定的保存的文件夹必须事先不能存在,如果存在的话保存文件会报错。
此时就需要我们自定义文件保存名。
需要自定义保存的文件名的话,就需要我们重新对输出的文件的方式进行一个格式化,也就是说不能够使用系统默认的输出文件的方式,需要我们自定义输出格式,需要重写outputFormat类。
需求:需要将数据库中的数据通过sparksql读取之后进行计算,然后进行计算,最终以指定的文件名写入到指定的目录下面:
数据库内容:
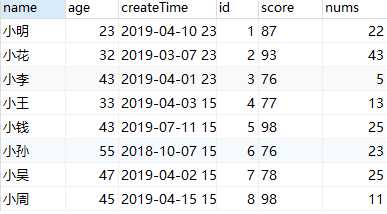
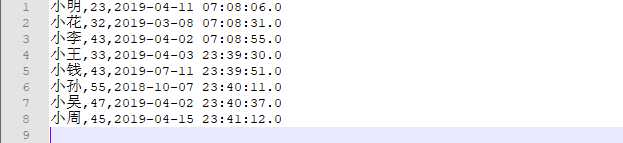
保存之后的文件:
保存路径:本地“E:/dataFile/result”,该目录下,文件名为person.txt
保存之后文件名:

保存后文件内容:
需要自定一个一个类重写outputFormat类中的方法
这里我使用saveAsHadoopFile的方式进行保存文件,如果是使用saveAsTextFile的方式的话,因为只有能传入一个参数,
saveAsHadoopFile的形式保存文件,该方式是针对<k,v>对的RDD进行保存,保存的文件中内容是key和value,以空格分开,相同的key或保存在同一个文件中
上代码:
第一步:重写FileoutputFormat类
package cn.com.xxx.audit
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.hadoop.mapred.{FileOutputFormat, JobConf}
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat
class CustomOutputFormat extends MultipleTextOutputFormat[Any, Any] {
//重写generateFileNameForKeyValue方法,该方法是负责自定义生成文件的文件名
override def generateFileNameForKeyValue(key: Any, value: Any, name: String): String = {
//这里的key和value指的就是要写入文件的rdd对,再此,我定义文件名以key.txt来命名,当然也可以根据其他的需求来进行生成文件名
val fileName = key.asInstanceOf[String] + ".txt"
fileName
}
/**
*因为saveAsHadoopFile是以key,value的形式保存文件,写入文件之后的内容也是,按照key value的形式写入,k,v之间用空格隔开,这里我只需要写入value的值,不需要将key的值写入到文件中个,所以我需要重写
*该方法,让输入到文件中的key为空即可,当然也可以进行领过的变通,也可以重写generateActuralValue(key:Any,value:Any),根据自己的需求来实现
*/
override def generateActualKey(key: Any, value: Any): String = {
null
}
//对生成的value进行转换为字符串,当然源码中默认也是直接返回value值,如果对value没有特殊处理的话,不需要重写该方法
override def generateAcutalValue(key: Any, value: Any): String = {
return value.asInstance[String]
}
/**
* 该方法使用来检查我们输出的文件目录是否存在,源码中,是这样判断的,如果写入的父目录已经存在的话,则抛出异常
* 在这里我们冲写这个方法,修改文件目录的判断方式,如果传入的文件写入目录已存在的话,直接将其设置为输出目录即可,
* 不会抛出异常
*/
override def checkOutputSpecs(ignored: FileSystem, job: JobConf): Unit = {
var outDir: Path = FileOutputFormat.getOutputPath(job)
if (outDir != null) {
val fs: FileSystem = ignored
outDir = fs.makeQualified(outDir)
FileOutputFormat.setOutputPath(job, outDir)
}
}
}
第二步:
package scala.spark._sql
import java.util.Properties
import mysqlUtils.OperatorMySql
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat
import org.apache.hadoop.mapred.{FileOutputFormat, JobConf}
import org.apache.spark.sql.{DataFrame, SQLContext}
import org.apache.spark.{SparkConf, SparkContext, TaskContext}
object DataFrameToMySql {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName(this.getClass.getName).setMaster("local[2]")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//配置输出文件不生成success文件
sc.hadoopConfiguration.set("mapreduce.fileoutputcommitter.marksuccessfuljobs", "false")
//配置一些参数
//如果设置为true,sparkSql将会根据数据统计信息,自动为每一列选择单独的压缩编码方式
sqlContext.setConf("spark.sql.inMemoryColumnarStorage.compressed", "true")
//控制列式缓存批量的大小。增大批量大小可以提高内存的利用率和压缩率,但同时也会带来OOM的风险
sqlContext.setConf("spark.sql.inMemoryColumnarStorage.batchSize", "1000")
sqlContext.setConf("spark.sql.autoBroadcastJoinThreshold", "10485760")
//设为true,则启用优化的Tungsten物理执行后端。Tungsten会显示的管理内存,并动态生成表达式求值得字节码
sqlContext.setConf("spark.sql.tungsten.enabled", "true")
//配置shuffle是的使用的分区数
sqlContext.setConf("spark.sql.shuffle.partitions", "200")
sc.setLogLevel("WARN")
val pro = new Properties()
pro.put("user", "root")
pro.put("password", "123456")
pro.put("driver", "com.mysql.jdbc.Driver")
val url = "jdbc:mysql://localhost:3306/test?serverTimezone=UTC"
val rdf = sqlContext.read /*.jdbc(url,"person1",pro)*/
.format("jdbc")
.options(Map(
"url" -> url,
"dbtable" -> "person",
"driver" -> "com.mysql.jdbc.Driver",
"user" -> "root",
"password" -> "123456",
"fetchSize" -> "10",
"partitionColumn" -> "age",
"lowerBound" -> "0",
"upperBound" -> "1000",
"numPartitions" -> "2"
)).load()
//将读取的文件尽心个计算,并且以pairRDD的形式写入文件中,这里在写入文件的时候,会将key当做文件名来进行写入,也就是说相同的key对应的value都会写入到相同的文件中
val x = rdf.groupBy(substring(col("score"), 0, 5) as ("score")).agg(max("age") as ("max"), avg("age") as ("avg"))
.rdd.map(x => ("person", x(0) + "," + x(1) + "," + x(2)))
//这里partitionBy,只是来增加文件文件写入的并行度,可以根据需求进行设置,影响的是文件写入的性能,我个人是这么理解的,如果有不对的还请指正
.partitionBy(new HashPartitioner(10))
//这里写入的时候,要指定我们自定义的PairRDDMultipleTextOutputFormat类
.saveAsHadoopFile("file:///E:/dataFile/res", classOf[String], classOf[String], classOf[PairRDDMultipleTextOutputFormat])
sc.stop()
}
文件内容:
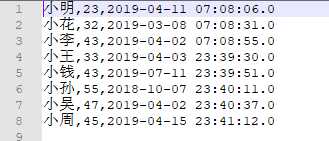
文件名称:

文件夹名称:
E:\dataFile\res
改文件夹事先已经存在,因为重写了checkOutputSpecs方法,做了处理,所以不会抛出异常,如果改文件夹目录实现不存在的话,程序会自动去创建一个该文件夹
主要来看下我们重写的这几个方法,源码中都做了些什么:
类名:MultipleOutputFormat
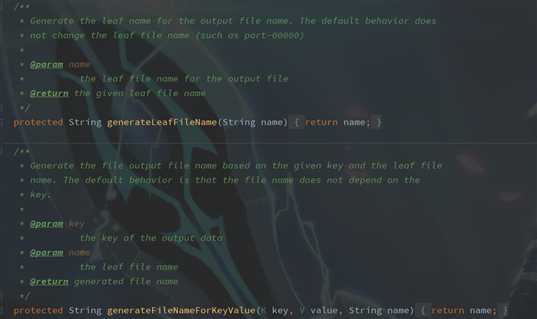
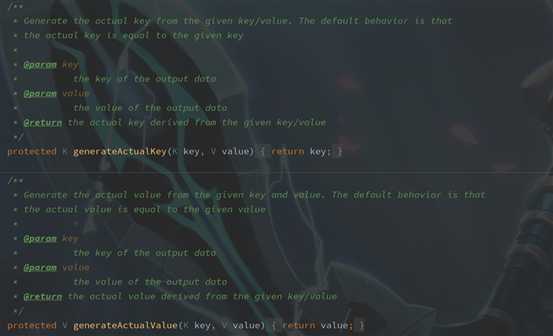
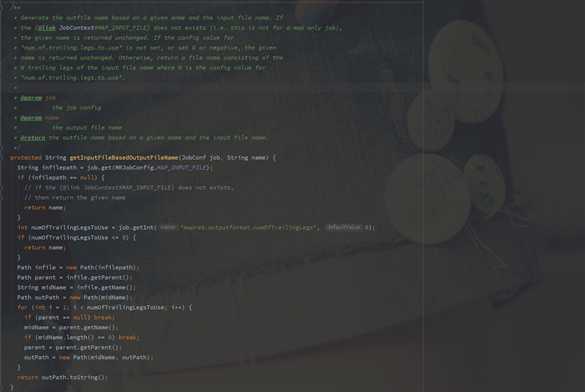
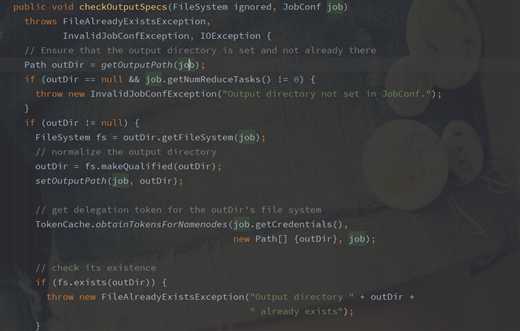
从源码中可以很容易的看到各个类的实现。
这样我们就可以根据我们的需求,将spark计算之后的数据写入到我们指定的文件夹下面,并且指定生成的文件名。
这个问题搞了我两三天了,网上各种找,都说是要重写什么getRecordWriter方法,理清了思路之后,才发现,不是我需要的,在此记录一下
关于spark写入文件至文件系统并制定文件名之自定义outputFormat
原文:https://www.cnblogs.com/Gxiaobai/p/10705712.html