pip install scrapy-redis
从GitHub 上拷贝源码:
clone github scrapy-redis源码文件 git clone https://github.com/rolando/scrapy-redis.git
1.domz爬虫:

2.配置中:

3.执行domz的爬虫,会发现redis中多了一下三个键

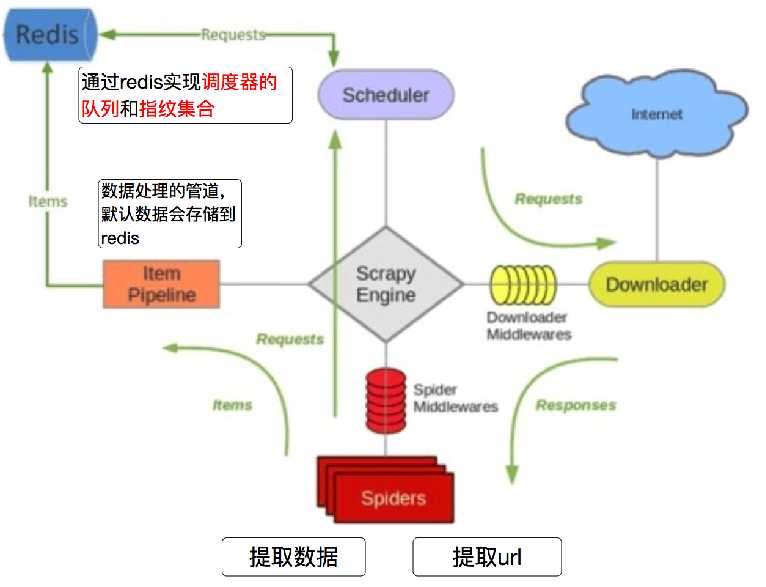
redispipeline中仅仅实现了item数据存储到redis的过程,我们可以新建一个pipeline(或者修改默认的ExamplePipeline),可以让数据存储到任意地方。



domz相比于之前的spider多了持久化和request去重的功能,setting中的配置都是可以自己设定的,
意味着我们的可以重写去重和调度器的方法,包括是否要把数据存储到redis(pipeline)




dont_filter = True ,构造请求的时候,把dont_filter置为True,该url会被反复抓取(url地址对应的内容会更新的情况)
一个全新的url地址被抓到的时候,构造request请求
url地址在start_urls中的时候,会入队,不管之前是否请求过
构造start_url地址的请求时候,dont_filter = True
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
# dont_filter=False Ture True request指纹已经存在 #不会入队
# dont_filter=False Ture False request指纹已经存在 全新的url #会入队
# dont_filter=Ture False #会入队
self.df.log(request, self.spider)
return False
self.queue.push(request) #入队
return True
使用sha1加密request得到指纹
把指纹存在redis的集合中
下一次新来一个request,同样的方式生成指纹,判断指纹是否存在reids的集合中
fp = hashlib.sha1()
fp.update(to_bytes(request.method)) #请求方法
fp.update(to_bytes(canonicalize_url(request.url))) #url
fp.update(request.body or b‘‘) #请求体
return fp.hexdigest()
added = self.server.sadd(self.key, fp) return added != 0
原文:https://www.cnblogs.com/knighterrant/p/10707492.html