这里的实例不是类产生的实例对象,而是Linux系统下的一种机制
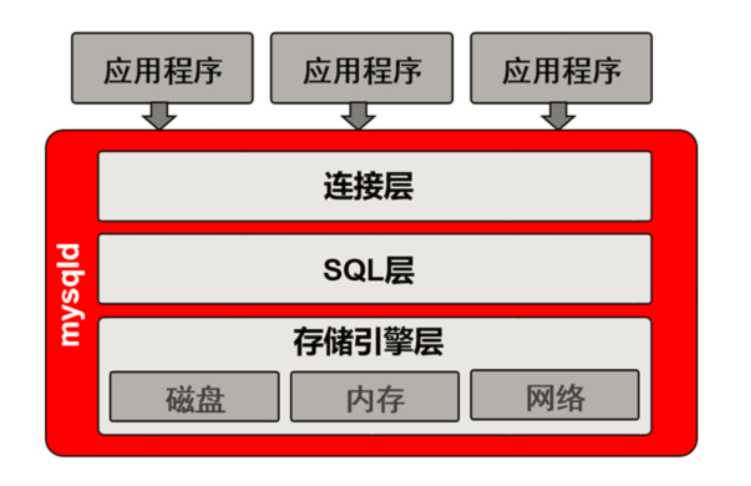
1.提供链接协议(socket,tcp/ip) #这里的socket也不是网络连接的socket,mysql的socket连接只能连接本地
2.验证用户的合法性(用户名,密码,白名单)
3.提供一个专用连接线程(接收sql,返回结果,将sql语句交给sql层继续处理)
1.接收到sql语句,语法判断
2.判断语义(判断语句类型:DML,DDL,DCL,DQL)
3.解析SQL语句,生成多种执行计划
4.优化器,选择它认为成本最低的执行计划(通俗讲就是选择速度快,消耗低的sql语句类型)
5.执行器根据优化器的选择,按照优化器建议执行sql语句,得到去哪儿找sql语句需要访问的数据
5.1.具体:在哪个数据文件上的哪个数据页中
5.2.将以上结果充送给下层继续处理
6.接收存储引擎层的数据,结构化成表的形式,通过连接层提供的专用线程
7.提供查询缓存
7.1.query_cache使用memcached或Redis代替
8.日志记录(binlog)
1.接收上层的执行结果
2.取出磁盘文件和相应数据
3.返回给sql层,结构化之后生成表格,由专用线程返回给客户端
MySQL的逻辑对象:做为管理人员或者开发人员操作的对象
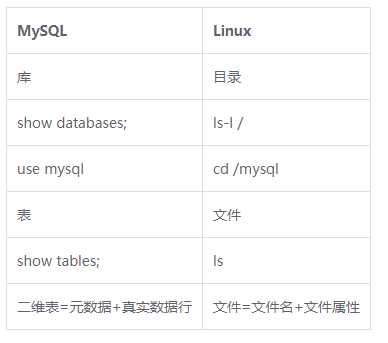
1.库
2.表:元数据+真实数据行
3.元数据:列+其他属性(行数+占用空间大小+权限)
4.列:列名字+数据类型+其他约束(非空,唯一,主键,非负数,自增长,默认值)
最直观的数据:二维表,必须用库来存放
MySQL逻辑结构与Linux系统对比
1)MySQL的最底层的物理结构是数据文件,也就是说,存储引擎层,打交道的文件,是数据文件。
2)存储引擎分为很多种类(Linux中的FS)
3)不同存储引擎的区别:存储方式、安全性、性能
段、区、页(块)
原文:https://www.cnblogs.com/angelyan/p/10713009.html