1.什么是人工智能?
顾名思义就是由人创造的"智慧能力",具备听说看理解等能力.
听 ==语音识别
说 ==语音合成
看 ==图像视频文字识别
理解 ==语言(文字)图像视频理解等逻辑处理
思考 ==理解后的逻辑处理
2.目前人工智能做了什么?
语音识别:小米的小爱同学,苹果 的siri,微软的Cortana
语音合成:小米的小爱同学,苹果 的siri,微软的Cortana
图像识别:交通摄像头拍违章,刷脸解锁手机等
视频识别:抖音内容审核,视频社交APP的审核机制
文字识别:从身份证照片提取身份证号码,扫一扫翻译
3.人工智能平台 --百度AI:ai.baidu.com
![]() >>>>>
>>>>> >>>>>>>
>>>>>>> >>>>>>>
>>>>>>> >>>>
>>>>


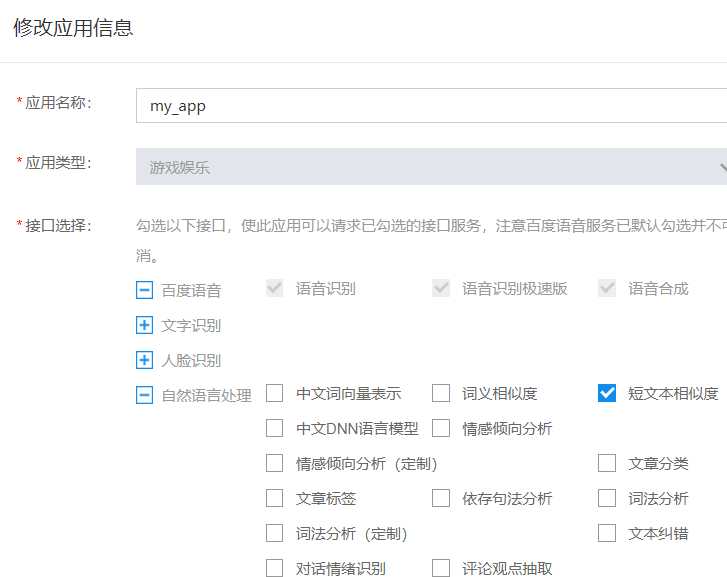
4.语音合成的实例:把文本合成语音
语音合成文档>>>>>>sdk文档>>>>>>>.Python文档(仔细阅读文档)
1.Python SDK 接口能力:将文字转换成音频文件的技术
2.注意事项 合成文本长度必须小于1024字节,如果本文长度较长,可以采用多次请求的方式。切忌文本长度超过限制
3.安装语音合成Python SDK
pip install baidu-aip即可。python setup.py install即可。4.新建AipSpeech
AipSpeech是语音合成的Python SDK客户端,为使用语音合成的开发人员提供了一系列的交互方法。
from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = ‘你的 App ID‘ API_KEY = ‘你的 Api Key‘ SECRET_KEY = ‘你的 Secret Key‘ client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
5.把一段文字合成为语音文件(实例):
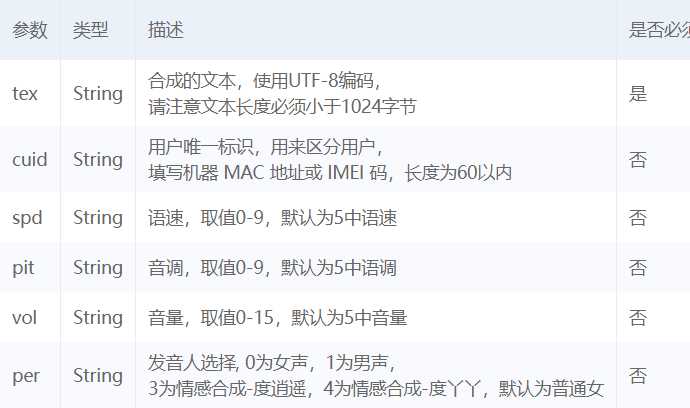
result = client.synthesis(‘你好百度‘, ‘zh‘, 1, { ‘vol‘: 5, #音量大小 "spd":5, #语速 "pit":5, #语调 "per":1, #情感发音 }) # 识别正确返回语音二进制 错误则返回dict 参照下面错误码 if not isinstance(result, dict): with open(‘audio.mp3‘, ‘wb‘) as f: f.write(result)
5. 语音识别:将一个可读的语音文件转换成计算机可识别的字符串序列
原始 PCM 的录音参数必须符合 8k/16k 采样率、16bit 位深、单声道,支持的格式有:pcm(不压缩)、wav(不压缩,pcm编码)、amr(压缩格式)。
5.1.安装语音合成Python SDK
pip install baidu-aip即可。python setup.py install即可。5.2.新建AipSpeech
from aip import AipSpeech """ 你的 APPID AK SK """ APP_ID = ‘你的 App ID‘ API_KEY = ‘你的 Api Key‘ SECRET_KEY = ‘你的 Secret Key‘ client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
5.3.要对保存有一段语音的语音文件进行识别(实例):
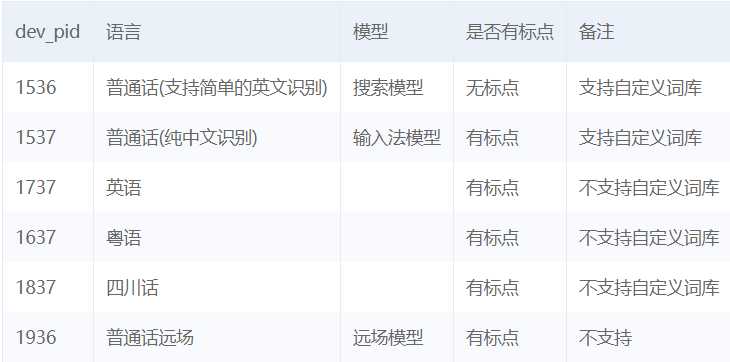
# 读取文件 def get_file_content(filePath): with open(filePath, ‘rb‘) as fp: return fp.read() # 识别本地文件 client.asr(get_file_content(‘audio.pcm‘), ‘pcm‘, 16000, { ‘dev_pid‘: 1536, })
音频文件转换格式使用软件ffmpeg,使用说明:
原文:https://www.cnblogs.com/l1222514/p/10718452.html