零个或多个数据元素的有限序列。
首先它是一个序列。也就是说,元素之间是有顺序的,若元素存在多个,则第一个元素无前驱,最后一个元素无后继,其它元素都有且只有一个前驱一个后继。
然后,线性表强调是有限的,即元素个数是有限的。
对于一个线性表来说,插入或者删除数据都是必须的操作,因此线性表的抽象数据类型定义如下:
ADT线性表(List) Data 线性表的数据对象集合为 (a1, a2, a3, ……, an), 每个元素的类型均为 DataType。其中,除第一个元素外,每个元素有且只有一个直接前驱元素;除了最后一个元素外,每个元素有且只有一个直接后继元素。数据元素之间的关系是一对一的关系。 Operation InitList (*L) : 初始化操作,建立一个空的线性表L。 ListEmpty (L): 若线性表为空,返回 true,否则返回 false。 ClearList (*L): 将线性表清空。 GetElem (L, i, *e): 将线性表 L 中的第 i 个元素值返回给 e。 LocateElem (L, e): 在线性表 L 中查找与给定值 e 相等的元素,如果查找成功,返回该元素在表中序号表示成功;否则,返回 0 表示失败。 ListInsert (*L, i, e): 在线性表 L 中的第 i 个位置插入新元素 e。 ListDelete (*L, i, *e): 删除线性表 L 中第 i 个位置元素,并用 e 返回其值。 ListLength (L): 返回线性表 L 的元素个数。 endADT
对于不同的应用,线性表的基本操作是不同的,上述操作是最基本的,对于实际问题中涉及的关于线性表的更复杂操作,完全可以用这些基本操作的组合来实现。

线性表的顺序存储结构,就是在内存中找了块地儿,通过占位的形式,把一定内存空间给占了,然后把相同数据类型的数据元素依次存放在这块空地中。既然线性表的每个数据元素的类型都相同,所以可以用 C 语言(其它语言也相同)的一维数组来实现顺序存储结构,即把第一个数据元素存到数组下标为 0 的位置中,接着把线性表相邻的元素存储在数组中相邻的位置。
/* 存储空间初始分配量 */ #define MAXSIZE 20 /* ElemType 类型根据实际情况而定,这里假设为 int */ typedef int ElemType; //是不是维护起来比较方便 typedef struct { /* 数组存储数据元素,最大值为 MAXSIZE */ ElemType data [MAXSIZE]; /* 线性表当前长度 */ int length; }SqList;
data, 它的存储位置就是存储空间的存储位置。MAXSIZE。length。数组长度指的是存放线性表的存储空间的长度,存储分配后这个量一般是不变的(一般高级语言,比如 C,VB, C++都可以用编程手段实现动态分配数组长度,不过这回带来性能上的损耗)。
线性表的长度指的是线性表中数据元素的个数,随着线性表插入和删除操作的进行,这个量是变化的。
在任何时刻,线性表的长度都应该小于等于数组的长度。
C 语言中的数组是从 0 开始第一个下标的,线性表的第 i 个元素是要存储在数组下标为i - 1的位置,即数据元素的序号和存放它的数组下标之间存在对应关系(如下图)。

用数组存储顺序表意味着要分配固定长度的数组空间,由于线性表中可以进行插入和删除操作,因此分配的数组空间要大于等于当前线性表的长度。
先来看最好情况,如果元素要插入到最后一个位置,或者删除最后一个元素,此时时间复杂度为O(1),因为不需要移动元素的。
最坏的情况,就是元素要插入到第一个位置,或者删除第一个元素,此时所有元素都要移动,时间复杂度为 O(n)。
平均移动次数为(n - 1) / 2,可以得出平均时间复杂度是O(n)。

顺序存储结构最大的缺点就是插入和删除时需要移动大量元素,这显然就需要耗费时间。
线性表的链式存储结构的特点是用一组任意的存储单元存储线性表的数据元素,这组存储单元可以是连续的,也可以是不连续的。这就意味着,这些数据元素可以存在内存未被占用的任意位置。
在顺序结构中,每个数据元素只需要存数据元素信息就可以了,但在链式结构中,除了要存数据元素信息外,还要存储它的后继元素的存储地址。
为了表示每个数据元素 a(i) 与其直接后继数据元素 a(i+1) 之间的逻辑关系,对数据元素a(i)来说,除了存储其本身的信息之外,还需存储一个指示其直接后继的信息(即直接后继的存储位置)。我们把存储数据元素信息的域称为数据域,把存储直接后继位置的域称为指针域。指针域中存储的信息称作指针或链。这两部分信息组成数据元素a(i)的存储映像,称为结点(Node)。
N 个结点链接成一个链表,即为线性表(a1,a2,…,a(n))的链式存储结构,因为此链表的每个结点中只包含一个指针域,所以叫做单链表。单链表正是通过每个结点的指针域将线性表的数据元素按其逻辑次序链接在一起。如下图所示:

对于线性表来说,总得有个头有个尾,链表也不例外。我们把链表中第一个结点的存储位置叫做头指针,那么整个链表的存取就必须是从头指针开始进行了。之后的每一个结点,其实就是上一个的后继指针指向的位置。最后一个结点指针为“空”,如下图所示:

有时,我们为了更加方便地对链表进行操作,会在单链表的第一个结点前附设一个结点,称为头结点。头结点的数据域可以不存储任何信息,也可以存储诸如线性表的长度等附加信息,头结点的指针域存储指向第一个结点的指针。如下图所示:


3.6.4 线性链表存储结构的代码描述

在线性表的顺序存储结构中,我们要计算任意一个元素的存储位置是很容易的,但在单链表中,必须得从头开始找。因此,对于单链表实现获取第 i 个元素的数据的操作 GetElem ,在算法上,相对要麻烦一些。


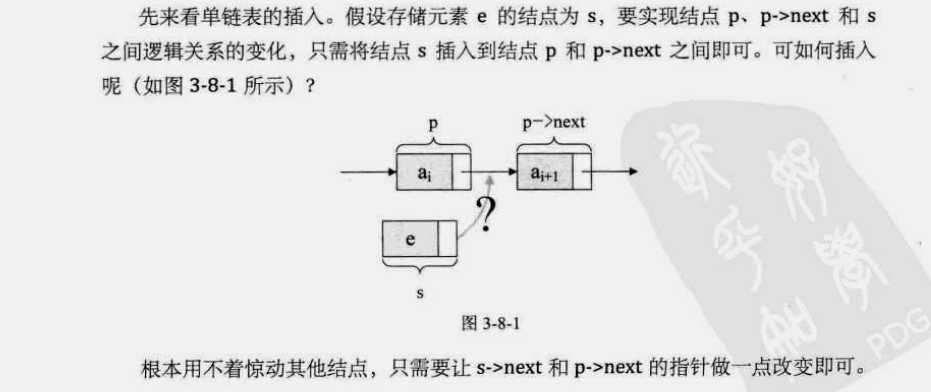
用不着惊动其它结点,只需让 s->next 和 p->next 的指针做一点改变即可。
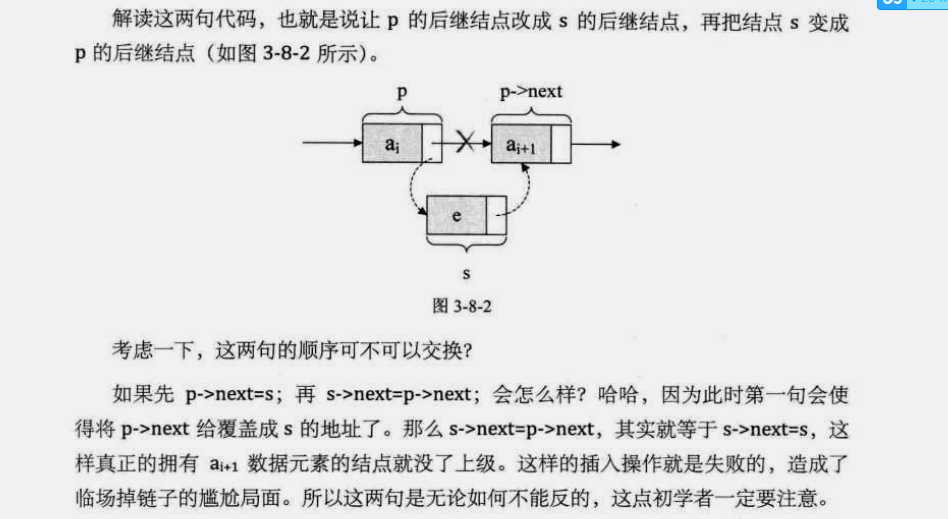
s->next=p->next; p->next=s;


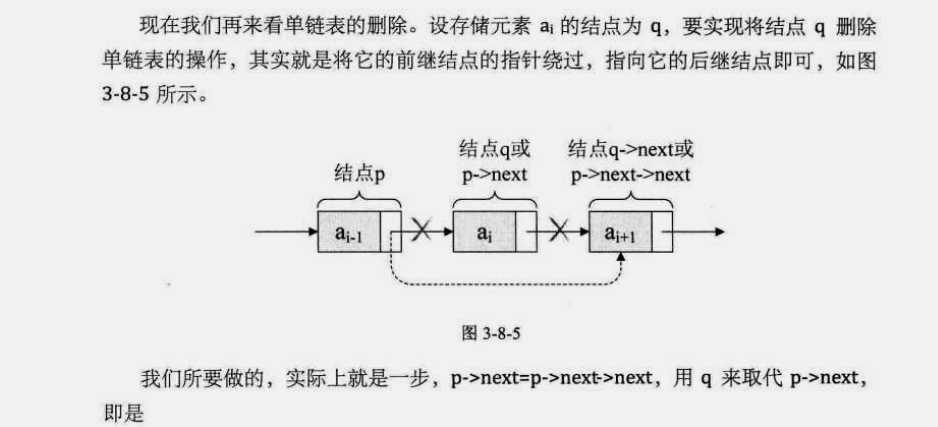
q=p->next; p->next=q->next;
解读代码:让 p 的后继结的后继结点改成 p 的后继结点。


顺序存储结构的创建,其实就是一个数组的初始化,即声明一个类型和大小的数组并赋值的过程。而链表和顺序存储结构不一样,它不像顺序存储结构这么集中,它可以很散,是一种动态结构。对每个链表来说,它所占用空间的大小和位置是不需要预先分配划定的,可以根据系统的情况和实际的需求即时生成。
所以创建单链表的过程就是一个动态生成链表的过程。即从“空表”的初始化状态起,依次建立各元素结点,并逐个插入链表。


当我们不打算使用这个单链表时,我们需要把它销毁,其实也就是在内存中将它释放掉,以便留出空间给其它程序或软件使用。


原文:https://www.cnblogs.com/xinmomoyan/p/10720316.html