谷歌,http://www.cs.toronto.edu/~dross/
UC Berkeley
贡献了一个新的动作分类的数据集
分类更加多,单人,多人,人和物体的动作三大类。还有时间和空间上更加精确的标定

人类动作识别数据集AVA(atomic visual actions,原子视觉动作),提供扩展视频序列中每个人的多个动作标签,精确标注多人动作,我们将动作标签限制在固定的3s时间内。
[电影」和「电视」类别,选择来自不同国家的专业演员。我们对每个视频抽取 15 分钟进行分析,并统一将 15 分钟视频分割成 300 个非重叠的 3 秒片段。采样遵循保持动作序列的时间顺序这一策略。
数据集地址:https://research.google.com/ava/ 需要科学链接
反思改进/灵感:
#############################################################
论文主要部分:

数据集的基本参数:连续三秒长,80种不同的动作类型





静态动作数据集,以及这些数据记的缺点:失去了时间的特征



3. Data collection:
4. Characteristics of the AVA dataset
5. Experiments
6. Conclusion
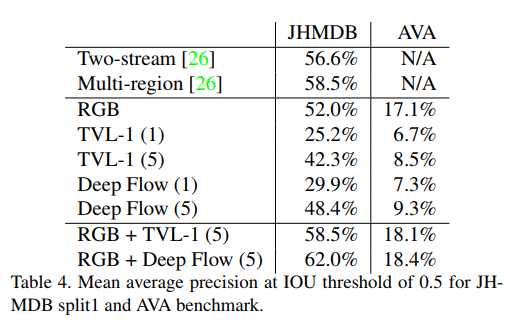
目前的研究方法,在AVA数据集都还没有取得SOFA的结果,说明视频动作分类还需要研究出更好的算法出来。
https://github.com/tensorflow/models/tree/master/research/object_detection
2018AVA: A Video Dataset of Spatio-temporally Localized Atomic Visual Actions
原文:https://www.cnblogs.com/captain-dl/p/10735415.html