高维数据的高速近期邻算法FLANN
1.?????简单介绍
? ? ? ? ?在计算机视觉和机器学习中,对于一个高维特征,找到训练数据中的近期邻计算代价是昂贵的。对于高维特征,眼下来说最有效的方法是 the randomized k-d forest和the priority search k-means tree,而对于二值特征的匹配 multiple hierarchical clusteringtrees则比LSH方法更加有效。
? ? ? ? 眼下来说。fast library for approximate nearest neighbors (FLANN)库能够较好地解决这些问题。
2.?????高速近似NN匹配(FAST APPROXIMATE NN MATCHING)
2.1?随机k-d树算法(The Randomized k-d TreeAlgorithm)
a. Classick-d tree
? ? ? ? 找出数据集中方差最高的维度,利用这个维度的数值将数据划分为两个部分,对每一个子集反复同样的过程。
? ? ? ? 參考http://www.cnblogs.com/eyeszjwang/articles/2429382.html。
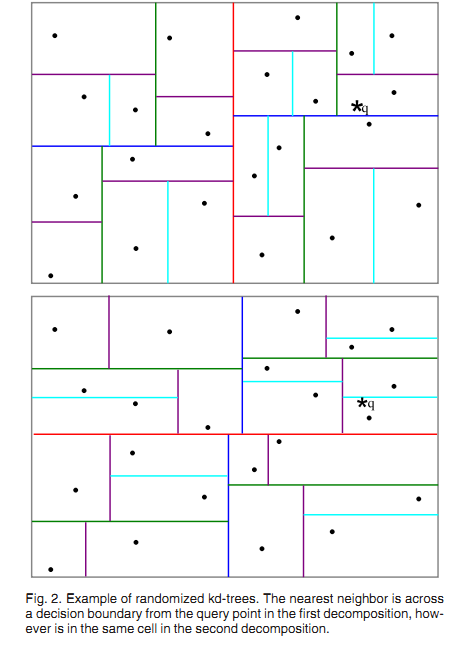
b. ?Randomizedk-d tree
? ? ? ? 建立多棵随机k-d树。从具有最高方差的N_d维中随机选取若干维度,用来做划分。在对随机k-d森林进行搜索时候。全部的随机k-d树将共享一个优先队列。
? ? ? ?添加树的数量能加快搜索速度。但因为内存负载的问题。树的数量仅仅能控制在一定范围内,比方20,假设超过一定范围,那么搜索速度不会添加甚至会减慢。
2.2? 优先搜索k-means树算法(The Priority Search K-MeansTree Algorithm)
? ? ? ? 随机k-d森林在很多情形下都非常有效,可是对于须要高精度的情形,优先搜索k-means树更加有效。 K-means tree 利用了数据固有的结构信息,它依据数据的全部维度进行聚类,而随机k-d tree一次仅仅利用了一个维度进行划分。
2.2.1 ?算法描写叙述
算法1 建立优先搜索k-means tree:
(1)??建立一个层次化的k-means 树;
(2)??每一个层次的聚类中心,作为树的节点;
(3)??当某个cluster内的点数量小于K时。那么这些数据节点将做为叶子节点。
算法2 在优先搜索k-means tree中进行搜索:
(1)??从根节点N開始检索。
(2)??假设是N叶子节点则将同层次的叶子节点都添加到搜索结果中。count += |N|。
(3)??假设N不是叶子节点。则将它的子节点与query Q比較。找出近期的那个节点Cq。同层次的其它节点添加到优先队列中。
(4)??对Cq节点进行递归搜索;
(5)??假设优先队列不为空且 count<L。那么从取优先队列的第一个元素赋值给N,然后反复步骤(1)。
? ? ? ? 聚类的个数K,也称为branching factor 是个非常基本的參数。
? ? ? ? 建树的时间复杂度 = O( ndKI ( log(n)/log(K) ))? n为数据点的总个数,I为K-means的迭代次数。搜索的时间复杂度 = O( L/K * Kd * ( log(n)/(log(K) ) ) = O(Ld ( log(n)/(log(K) ) )。
2.3?层次聚类树 (The Hierarchical ClusteringTree)
? ? ? ? 层次聚类树採用k-medoids的聚类方法。而不是k-means。
即它的聚类中心总是输入数据的某个点,可是在本算法中,并没有像k-medoids聚类算法那样去最小化方差求聚类中心,而是直接从输入数据中随机选取聚类中心点,这个方案在建立树时更加简单有效,同一时候又保持多棵树之间的独立性。
? ? ? ? 同一时候建立多棵树,在搜索阶段并行地搜索它们能大大提高搜索性能(归功于随机地选择聚类中心。而不须要多次迭代去获得更好的聚类中心)。建立多棵随机树的方法对k-d tree也十分有效,但对于k-means tree却不适用。
3.????? 參考文献
(1)??ScalableNearest Neighbor Algorithms for High Dimensional Data. Marius Muja, Member,IEEE and David G. Lowe, Member, IEEE.
(2)??OptimisedKD-trees for fast image descriptor matching. Chanop Silpa-Anan, Richard Hartley.
(3)??FastMatching of Binary Features. Marius Muja and David G. Lowe.
原文:https://www.cnblogs.com/xfgnongmin/p/10738936.html