本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10737065.html
上一章CNN中各个算法都是纯手工实现的,可能存在一些难以发现的问题,这也是准确率不高的一个原因,这章主要利用tensorflow框架来实现卷积神经网络,数据源还是cifar(具体下载见上一章)
在利用tensorflow框架实现CNN时,需要注意以下几点:
1.输入数据定义时,x只是起到占位符的作用(看不到真实值,只是为了能够运行代码,获取相应的tensor节点,这一点跟我们之前代码流程完全相反, 真正数据流的执行在session会话里)
x:输入数据,y_: 标签数据,keep_prob: 概率因子,防止过拟合。
定义,且是全局变量。
x = tf.placeholder(tf.float32, [None, 3072], name=‘x‘)
y_ = tf.placeholder(tf.float32, [None, 10], name=‘y_‘)
keep_prob = tf.placeholder(tf.float32)
后面在session里必须要初始化
sess.run(tf.global_variables_initializer())
在session run时必须要传得到该tensor节点含有参数值(x, y_, keep_prob)
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0})
2.原始数据集标签要向量化;
例如cifar有10个类别,如果类别标签是 6 对应向量[0,0,0,0,0,1,0,0,0,0]
3.知道每一步操作的数据大小的变化,不然,报错的时候很难定位(个人认为这也是tensorflow的弊端,无法实时追踪定位);
注意padding = ‘SAME‘和‘VALID‘的区别
padding = ‘SAME‘ => Height_后 = Height_前/Strides 跟padding无关 向上取整
padding = ‘VALID‘=> Height_后 = (Height_前 - Filter + 1)/Strides 向上取整
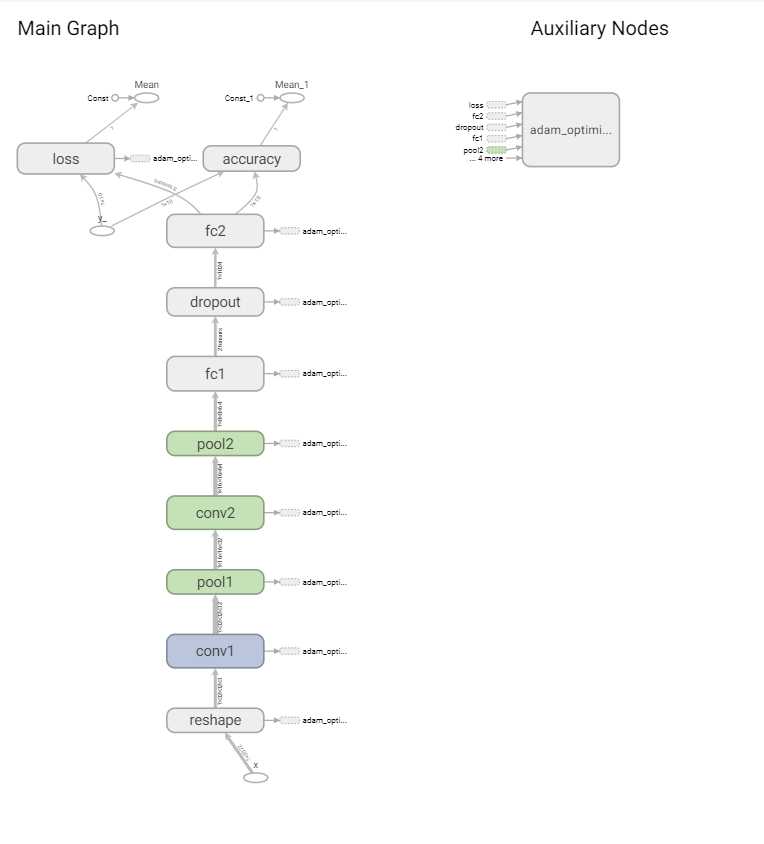
4.打印tensorboard流程图,可以直观看到每步操作数据大小的变化;
tensorboard就是一个数据结构流程图的可视化工具,通过tensorboard流程图,可以直观看到神经网络的每一步操作以及数据流的变化。
操作步骤:
1. 在session会话里加入如下代码,打印结果会在当前代码文件相同路径的tensorboard文件下,默认是
tf.summary.FileWriter("tensorboard/", sess.graph)
2. 在运行里输入cmd,然后输入(前提是安装好了tensorboard => pip install tensorboard)
tensorboard --logdir=D:\Project\python\myProject\CNN\tensorflow\captchaIdentify\tensorboard --host=127.0.0.1
‘D:\Project\python\myProject\CNN\tensorflow\captchaIdentify\tensorboard‘ 是我生成的tensorboard文件的绝对路径,你替换成你自己的就可以了。
正确运行后会显示 ‘Tensorboard at http://127.0.0.1:6006’,说明tensorboard服务已经起来了,在浏览器页面输入
http://127.0.0.1:6006即可显示流程图。
代码逻辑实现相对比较简单,在一些重要逻辑实现上,我已做了注释,如果大家有什么疑义,可以留言给我,我们一起交流。
因为原始图片数据集太大,不好上传,大家可以直接在http://www.cs.toronto.edu/~kriz/cifar.html下载CIFAR-10 python version,
有163M,放在代码文件同路径下即可。
cifar放置路径
start.py

1 # coding=utf-8 2 # Disable linter warnings to maintain consistency with tutorial. 3 # pylint: disable=invalid-name 4 # pylint: disable=g-bad-import-order 5 from __future__ import absolute_import 6 from __future__ import division 7 from __future__ import print_function 8 import argparse 9 import sys 10 import tempfile 11 #from tensorflow.examples.tutorials.mnist import input_data 12 import tensorflow as tf 13 ‘‘‘ 14 卷积神经网络实现10类(airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck) 15 60000张图片的识别 16 5000次,准确率有 58%; 17 20000次,准确率有 68.89%; 18 相比mnist数字图片识别准确度低,原因有: 19 mnist训练图片是灰度图片,纹理简单,数字的可变性小,而cifar是彩色图片,纹理复杂,动物可变性大; 20 ‘‘‘ 21 try: 22 from . import datesets 23 except Exception: 24 import datesets 25 26 FLAGS = None 27 28 def deepnn(x): 29 with tf.name_scope(‘reshape‘): 30 x_image = tf.reshape(x, [-1, 32, 32, 3]) 31 ## 第一层卷积操作 ## 32 with tf.name_scope(‘conv1‘): 33 W_conv1 = weight_variable([5, 5, 3, 32]) 34 b_conv1 = bias_variable([32]) 35 h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) 36 37 with tf.name_scope(‘pool1‘): 38 h_pool1 = max_pool_2x2(h_conv1) 39 40 # Second convolutional layer -- maps 32 feature maps to 64. 41 ## 第二层卷积操作 ## 42 with tf.name_scope(‘conv2‘): 43 W_conv2 = weight_variable([5, 5, 32, 64]) 44 b_conv2 = bias_variable([64]) 45 h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) 46 47 with tf.name_scope(‘pool2‘): 48 h_pool2 = max_pool_2x2(h_conv2) 49 50 ## 第三层全连接操作 ## 51 with tf.name_scope(‘fc1‘): 52 W_fc1 = weight_variable([8 * 8 * 64, 1024]) 53 b_fc1 = bias_variable([1024]) 54 h_pool2_flat = tf.reshape(h_pool2, [-1, 8 * 8 * 64]) 55 h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) 56 57 with tf.name_scope(‘dropout‘): 58 keep_prob = tf.placeholder(tf.float32) 59 h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) 60 61 ## 第四层输出操作 ## 62 with tf.name_scope(‘fc2‘): 63 W_fc2 = weight_variable([1024, 10]) 64 b_fc2 = bias_variable([10]) 65 y_conv = tf.matmul(h_fc1_drop, W_fc2) + b_fc2 66 return y_conv, keep_prob 67 68 def conv2d(x, W): 69 return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding=‘SAME‘) 70 71 def max_pool_2x2(x): 72 return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], 73 strides=[1, 2, 2, 1], padding=‘SAME‘) 74 75 def weight_variable(shape): 76 initial = tf.truncated_normal(shape, stddev=0.1) 77 return tf.Variable(initial) 78 79 def bias_variable(shape): 80 initial = tf.constant(0.1, shape=shape) 81 return tf.Variable(initial) 82 83 def main(_): 84 # Import data 85 mnist = datesets.read_data_sets(train_dir = ‘.\\cifar-10-batches-py\\‘, one_hot=True) 86 87 # Create the model 88 # 声明一个占位符,None表示输入图片的数量不定,28*28图片分辨率 89 x = tf.placeholder(tf.float32, [None, 3072], name=‘x‘) 90 91 # 类别是0-9总共10个类别,对应输出分类结果 92 y_ = tf.placeholder(tf.float32, [None, 10], name=‘y_‘) 93 y_conv, keep_prob = deepnn(x) 94 # 通过softmax-loss求交叉熵 95 with tf.name_scope(‘loss‘): 96 cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y_conv) 97 # 求均值 98 cross_entropy = tf.reduce_mean(cross_entropy) 99 # 计算梯度,更新参数值 100 with tf.name_scope(‘adam_optimizer‘): 101 train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) 102 103 with tf.name_scope(‘accuracy‘): 104 correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) 105 correct_prediction = tf.cast(correct_prediction, tf.float32) 106 accuracy = tf.reduce_mean(correct_prediction) 107 108 # graph_location = tempfile.mkdtemp() 109 # print(‘Saving graph to: %s‘ % graph_location) 110 # train_writer.add_graph(tf.get_default_graph()) 111 112 with tf.Session() as sess: 113 # 打印流程图 114 writer = tf.summary.FileWriter("tensorboard/", sess.graph) 115 sess.run(tf.global_variables_initializer()) 116 for i in range(20000): 117 batch = mnist.train.next_batch(50) 118 if i % 1000 == 0: 119 train_accuracy = accuracy.eval(feed_dict={ 120 x: batch[0], y_: batch[1], keep_prob: 1.0}) 121 print(‘step %d, training accuracy %g‘ % (i, train_accuracy)) 122 train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5}) 123 124 print(‘test accuracy %g‘ % accuracy.eval(feed_dict={ 125 x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})) 126 127 if __name__ == ‘__main__‘: 128 parser = argparse.ArgumentParser() 129 parser.add_argument(‘--data_dir‘, type=str, 130 default=‘/tmp/tensorflow/mnist/input_data‘, 131 help=‘Directory for storing input data‘) 132 FLAGS, unparsed = parser.parse_known_args() 133 tf.app.run(main=main, argv=[sys.argv[0]] + unparsed)
datasets.py
1 import numpy 2 from tensorflow.python.framework import dtypes 3 from tensorflow.python.framework import random_seed 4 from six.moves import xrange 5 from tensorflow.contrib.learn.python.learn.datasets import base 6 import pickle 7 import os 8 9 class DataSet(object): 10 """Container class for a dataset (deprecated). 11 12 THIS CLASS IS DEPRECATED. See 13 [contrib/learn/README.md](https://www.tensorflow.org/code/tensorflow/contrib/learn/README.md) 14 for general migration instructions. 15 """ 16 def __init__(self, 17 images, 18 labels, 19 fake_data=False, 20 one_hot=False, 21 dtype=dtypes.float32, 22 reshape=True, 23 seed=None): 24 """Construct a DataSet. 25 one_hot arg is used only if fake_data is true. `dtype` can be either 26 `uint8` to leave the input as `[0, 255]`, or `float32` to rescale into 27 `[0, 1]`. Seed arg provides for convenient deterministic testing. 28 """ 29 seed1, seed2 = random_seed.get_seed(seed) 30 # If op level seed is not set, use whatever graph level seed is returned 31 numpy.random.seed(seed1 if seed is None else seed2) 32 dtype = dtypes.as_dtype(dtype).base_dtype 33 if dtype not in (dtypes.uint8, dtypes.float32): 34 raise TypeError( 35 ‘Invalid image dtype %r, expected uint8 or float32‘ % dtype) 36 if fake_data: 37 self._num_examples = 10000 38 self.one_hot = one_hot 39 else: 40 assert images.shape[0] == labels.shape[0], ( 41 ‘images.shape: %s labels.shape: %s‘ % (images.shape, labels.shape)) 42 self._num_examples = images.shape[0] 43 44 # Convert shape from [num examples, rows, columns, depth] 45 # to [num examples, rows*columns] (assuming depth == 1) 46 if reshape: 47 assert images.shape[3] == 3 48 images = images.reshape(images.shape[0], 49 images.shape[1] * images.shape[2] * images.shape[3]) 50 if dtype == dtypes.float32: 51 # Convert from [0, 255] -> [0.0, 1.0]. 52 images = images.astype(numpy.float32) 53 images = numpy.multiply(images, 1.0 / 255.0) 54 self._images = images 55 self._labels = labels 56 self._epochs_completed = 0 57 self._index_in_epoch = 0 58 59 @property 60 def images(self): 61 return self._images 62 63 @property 64 def labels(self): 65 return self._labels 66 67 @property 68 def num_examples(self): 69 return self._num_examples 70 71 @property 72 def epochs_completed(self): 73 return self._epochs_completed 74 75 def next_batch(self, batch_size, fake_data=False, shuffle=True): 76 """Return the next `batch_size` examples from this data set.""" 77 if fake_data: 78 fake_image = [1] * 784 79 if self.one_hot: 80 fake_label = [1] + [0] * 9 81 else: 82 fake_label = 0 83 return [fake_image for _ in xrange(batch_size)], [ 84 fake_label for _ in xrange(batch_size) 85 ] 86 start = self._index_in_epoch 87 # Shuffle for the first epoch 88 if self._epochs_completed == 0 and start == 0 and shuffle: 89 perm0 = numpy.arange(self._num_examples) 90 numpy.random.shuffle(perm0) 91 self._images = self.images[perm0] 92 self._labels = self.labels[perm0] 93 # Go to the next epoch 94 if start + batch_size > self._num_examples: 95 # Finished epoch 96 self._epochs_completed += 1 97 # Get the rest examples in this epoch 98 rest_num_examples = self._num_examples - start 99 images_rest_part = self._images[start:self._num_examples] 100 labels_rest_part = self._labels[start:self._num_examples] 101 # Shuffle the data 102 if shuffle: 103 perm = numpy.arange(self._num_examples) 104 numpy.random.shuffle(perm) 105 self._images = self.images[perm] 106 self._labels = self.labels[perm] 107 # Start next epoch 108 start = 0 109 self._index_in_epoch = batch_size - rest_num_examples 110 end = self._index_in_epoch 111 images_new_part = self._images[start:end] 112 labels_new_part = self._labels[start:end] 113 return numpy.concatenate( 114 (images_rest_part, images_new_part), axis=0), numpy.concatenate( 115 (labels_rest_part, labels_new_part), axis=0) 116 else: 117 self._index_in_epoch += batch_size 118 end = self._index_in_epoch 119 return self._images[start:end], self._labels[start:end] 120 121 def read_data_sets(train_dir, 122 one_hot=False, 123 dtype=dtypes.float32, 124 reshape=True, 125 validation_size=5000, 126 seed=None): 127 128 129 130 131 train_images,train_labels,test_images,test_labels = load_CIFAR10(train_dir) 132 if not 0 <= validation_size <= len(train_images): 133 raise ValueError(‘Validation size should be between 0 and {}. Received: {}.‘ 134 .format(len(train_images), validation_size)) 135 136 validation_images = train_images[:validation_size] 137 validation_labels = train_labels[:validation_size] 138 validation_labels = dense_to_one_hot(validation_labels, 10) 139 train_images = train_images[validation_size:] 140 train_labels = train_labels[validation_size:] 141 train_labels = dense_to_one_hot(train_labels, 10) 142 143 test_labels = dense_to_one_hot(test_labels, 10) 144 145 options = dict(dtype=dtype, reshape=reshape, seed=seed) 146 train = DataSet(train_images, train_labels, **options) 147 validation = DataSet(validation_images, validation_labels, **options) 148 test = DataSet(test_images, test_labels, **options) 149 150 return base.Datasets(train=train, validation=validation, test=test) 151 152 153 def load_CIFAR_batch(filename): 154 """ load single batch of cifar """ 155 with open(filename, ‘rb‘) as f: 156 datadict = pickle.load(f, encoding=‘bytes‘) 157 X = datadict[b‘data‘] 158 Y = datadict[b‘labels‘] 159 X = X.reshape(10000, 3, 32, 32).transpose(0,2,3,1).astype("float") 160 Y = numpy.array(Y) 161 return X, Y 162 163 def load_CIFAR10(ROOT): 164 """ load all of cifar """ 165 xs = [] 166 ys = [] 167 for b in range(1,6): 168 f = os.path.join(ROOT, ‘data_batch_%d‘ % (b, )) 169 X, Y = load_CIFAR_batch(f) 170 xs.append(X) 171 ys.append(Y) 172 Xtr = numpy.concatenate(xs) 173 Ytr = numpy.concatenate(ys) 174 del X, Y 175 Xte, Yte = load_CIFAR_batch(os.path.join(ROOT, ‘test_batch‘)) 176 return Xtr, Ytr, Xte, Yte 177 178 def dense_to_one_hot(labels_dense, num_classes): 179 """Convert class labels from scalars to one-hot vectors.""" 180 num_labels = labels_dense.shape[0] 181 index_offset = numpy.arange(num_labels) * num_classes 182 labels_one_hot = numpy.zeros((num_labels, num_classes)) 183 labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1 184 return labels_one_hot
这里选取55000张图片作为训练样本,测试样本选取5000张。
tensorboard可视流程图
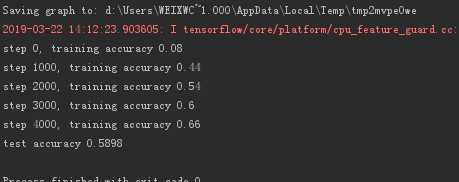
运行5000次,准确率:58%
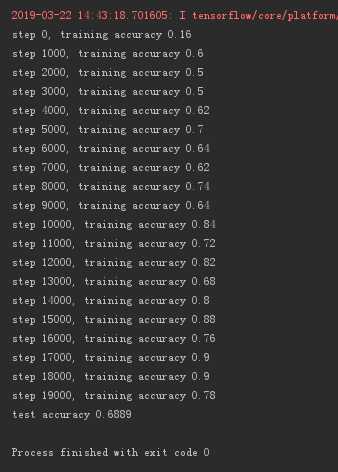
运行20000次,准确率:68.89%
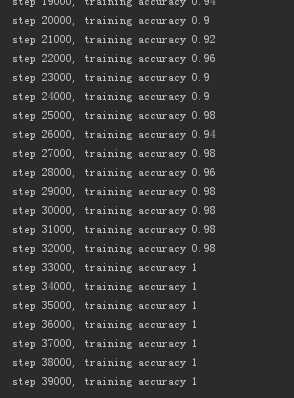
运行40000次,准确率:100%
不要让懒惰占据你的大脑,不要让妥协拖垮了你的人生。青春就是一张票,能不能赶上时代的快车,你的步伐就掌握在你的脚下。
原文:https://www.cnblogs.com/further-further-further/p/10737065.html
