案例:
网易新闻的爬取:
爬取的内容为一下4大板块中的新闻内容

爬取:
特点:
动态加载数据 ,用 selenium
1. 创建项目
scrapy startproject wy
2. 创建爬虫
scrapy genspider wangyi www.wangyi.com
1. 获取板块url
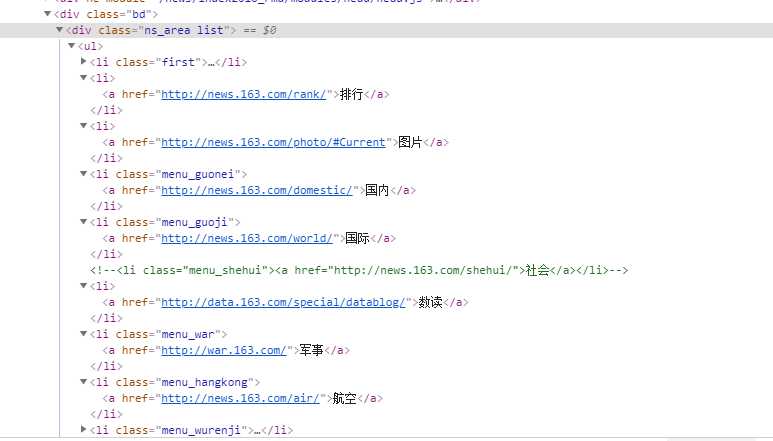

import scrapy class WangyiSpider(scrapy.Spider): name = ‘wangyi‘ # allowed_domains = [‘www.wangyi.com‘] start_urls = [‘https://news.163.com/‘] def parse(self, response): # 获取4大板块的url 国内、国际、军事、航空 li_list = response.xpath("//div[@class=‘ns_area list‘]/ul/li") item_list =[] for li in li_list: url = li.xpath("./a/@href").extract_first() title = li.xpath(‘./a/text()‘).extract_first().strip() # 过滤出 国内、国际、军事、航空 if title in [‘国内‘,‘国际‘,‘军事‘,‘航空‘]: item = {} item[‘title‘] = title item[‘url‘] = url print(item)
settings.py 文件中:
# Obey robots.txt rules ROBOTSTXT_OBEY = False
执行爬虫效果

2. 每个板块页面的爬取:
爬虫代码:
# 提取板块中的数据 def parse_content(self,response): title = response.meta.get(‘title‘) div_list =response.xpath("//div[@class=‘ndi_main‘]/div") print(len(div_list)) for div in div_list: item={} item[‘group‘] = title img_url = div.xpath(‘./a/img/@src‘).extract_first() article_url = div.xpath(‘./a/img/@href‘).extract_first() head = div.xpath(‘./a/img/@alt‘).extract_first() keywords = div.xpath(‘//div[@class="keywords"]//text()‘).extract() # 将列表内容转换成字符串 content = "".join([i.strip() for i in keywords]) item[‘img_url‘] = img_url item[‘article_url‘] = article_url item[‘head‘] = head item[‘keywords‘] = keywords yield scrapy.Request( url=article_url, callback=self.parse_detail, meta={‘item‘:copy.deepcopy(item)} )
启动爬虫时没有打印出结果:
用xpath help 插件检查,发现所写的xpath表达式没有错,说明,该页面的数据可能是动态加载的数据

xpath显示有数据
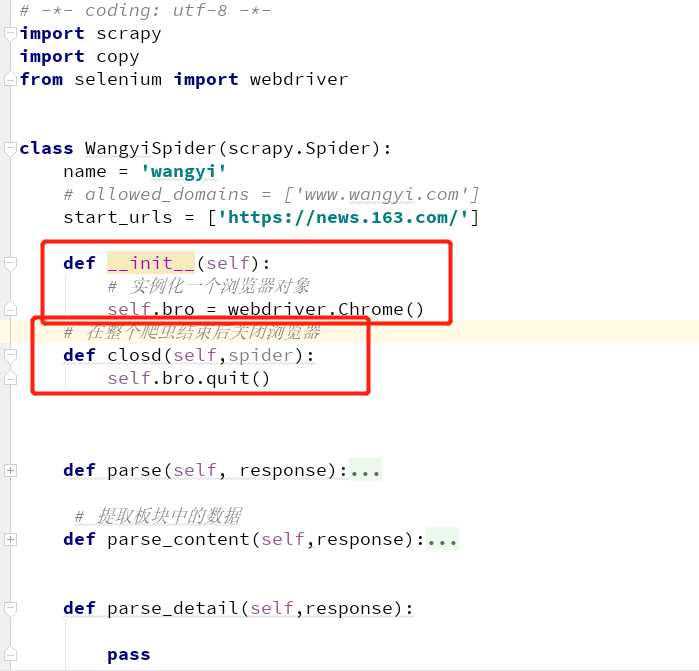
解决动态数据使用selenium:
1. 在爬虫类中,重新构造方法 __init__,和写爬虫结束时关闭浏览器
2. 在下载中间键中
from scrapy.http import HtmlResponse class WyDownloaderMiddleware(object): def process_request(self, request, spider): return None def process_response(self, request, response, spider): # 拦截 响应 if request.url in [ ‘http://news.163.com/domestic/‘,‘http://news.163.com/world/‘,‘http://war.163.com/‘,‘http://news.163.com/air/‘]: spider.bro.get(url=request.url) js = ‘window.scrollTo(0,document.body.scrollHeight)‘ spider.bro.execute_script(js) time.sleep(3) page_text=spider.bro.page_source return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding=‘utf-8‘) else: return response
3. settings.py中,开启下载中间件
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { ‘wy.middlewares.WyDownloaderMiddleware‘: 300, }
1.在中间中自定义一个user_agent 中间件类 ,继承UserAgentMiddleware
#单独给UA池封装一个 下载中间件的类 # 需要导包 userAgentMiddleware class RandomUserAgent(UserAgentMiddleware): ‘‘‘ UA池类 # 用faker 模块进行随机生成一个user_agent ‘‘‘ def process_request(self, request, spider): fake = Factory.create() # 通过 faker模块随机生成一个ua user_agent = fake.user_agent() request.headers.setdefault(‘User_Agent‘,user_agent)
2. 在settings.py 配置文件中:
DOWNLOADER_MIDDLEWARES = { ‘wy.middlewares.WyDownloaderMiddleware‘: 300, ‘wy.middlewares.RandomUserAgent‘: 543, }
1. 中间件中:
# 批量对拦截到的请求对ip 进行更换 ,自定义一个ip代理类
class Proxy(object):
def process_request(self,request,spider):
# 两种 ip 池
proxy_http=[‘206.189.231.239:8080‘,‘66.42.116.151:8080‘]
proxy_https=[‘113.140.1.82:53281‘,‘36.79.152.0:8080‘]
# request.url 返回值 :http://www.xxx.com 或 https://www.xxx.com
h = request.url.split(":")[0]
if h=="http:":
ip = random.choices(proxy_http)
request.meta[‘proxy‘]=‘http://‘+ip
else:
ip = random.choices(proxy_https)
request.meta[‘proxy‘] = ‘https://‘+ip
2. settings.py 配置
DOWNLOADER_MIDDLEWARES = {
‘wy.middlewares.WyDownloaderMiddleware‘: 543,
‘wy.middlewares.RandomUserAgent‘: 542,
‘wy.middlewares.Proxy‘: 541,
}
1. redis 配置文件redis.conf 进行修改
注释该行:#bind 127.0.0.1,表示可以让其他ip访问
将yes该为no:protected-mode no,表示可以让其他ip操作redis
2. 对爬虫进行修改
将爬虫类的父类修改成基于RedisSpider或者RedisCrawlSpider。注意:如果原始爬虫文件是基于Spider的,则应该将父类修改成RedisSpider,如果原始爬虫文件是基于CrawlSpider的,则应该将其父类修改成RedisCrawlSpider。
- 注释或者删除start_urls列表,切加入redis_key属性,属性值为scrpy-redis组件中调度器队列的名称
3. 在配置文件中进行相关配置,开启使用scrapy-redis组件中封装好的管道
ITEM_PIPELINES = { ‘scrapy_redis.pipelines.RedisPipeline‘: 400 }
4. 在配置文件中进行相关配置,开启使用scrapy-redis组件中封装好的调度器
# 使用scrapy-redis组件的去重队列 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 使用scrapy-redis组件自己的调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 是否允许暂停 SCHEDULER_PERSIST = True
5.在配置文件中进行爬虫程序链接redis的配置
REDIS_HOST = ‘redis服务的ip地址‘ REDIS_PORT = 6379 REDIS_ENCODING = ‘utf-8’ #REDIS_PARAMS = {‘password’:’123456’} # 有密码就需要写
6 开启redis服务器:redis-server 配置文件
7开启redis客户端:redis-cli
8 运行爬虫文件:scrapy runspider SpiderFile
9 向调度器队列中扔入一个起始url(在redis客户端中操作):lpush redis_key属性值 起始url
selenium、UA池、ip池、scrapy-redis的综合应用案例
原文:https://www.cnblogs.com/knighterrant/p/10745968.html
