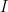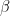在最近的一篇文章中,我描述了一个Metropolis-in-Gibbs采样器,用于估计贝叶斯逻辑回归模型的参数。
结论是,对数后验的评估是一个重要的运行时间瓶颈。在每次迭代中,对数后验被评估两次:一次在当前抽取,另一次在拟议的抽取。
这篇文章就此问题进行了研究,以展示Rcpp如何帮助克服这一瓶颈。 TLDR:只需用C ++编写log-posterior而不是矢量化R函数,我们就可以大大减少运行时间。R实现运行速度慢大约4-7倍。如果您正在为自己的采样器编写代码,那么分析代码并重写Rcpp中的瓶颈可能会非常有益。
我模拟了与上一篇文章类似的模型中的数据:
![]() ?
?
![]() ?
?
![]() ?
?
对于这个分析,我编写了两个Metropolis-Hastings(MH)采样器:sample_mh()和sample_mh_cpp()。前者使用对数后验编码作为向量化R函数。后者使用C ++(log_post.cpp)中的log-posterior编码,并使用Rcpp编译成R函数。Armadillo库对C ++中的矩阵和向量类很有用。
那么让我们看看使用C ++的采样器是如何做的。我运行100,000次MH迭代,其跳跃分布协方差![]() ?,其中
?,其中![]() ?是
?是![]() ?单位矩阵。因此,在每次迭代中,提出了系数向量。从这个意义上说,采样器是一个“阻塞”的MH。下面用红线表示链,表示生成数据的参数值。
?单位矩阵。因此,在每次迭代中,提出了系数向量。从这个意义上说,采样器是一个“阻塞”的MH。下面用红线表示链,表示生成数据的参数值。

![]() ?
?
似乎趋同。平均接受概率在采样运行中收敛到约20%。
旁注:在这种情况下,在哪里![]() ?是4维,MH运作良好。但众所周知,在更高的维度上,MH不能很好地工作(它慢慢地探索后部)。在那种情况下,自适应MH工作得更好,哈密尔顿蒙特卡罗(HMC)可能效果最好。
?是4维,MH运作良好。但众所周知,在更高的维度上,MH不能很好地工作(它慢慢地探索后部)。在那种情况下,自适应MH工作得更好,哈密尔顿蒙特卡罗(HMC)可能效果最好。
自适应MH包括调整周期,其中我们更新提议分布的方差 - 根据接受概率是高还是低来适当地缩放提议方差。
HMC使用额外的“动量”变量来使后验的探索更有效。我可能会在以后的帖子中讨论这些。
那么Rcpp实现与R实现相比如何呢?Rcpp的运行时间明显较低。当log-posterior被编码为矢量化R函数时,采样器相对于Rcpp实现运行速度大约慢7倍(样本大小为100)。下图显示了样本大小为100到5000的相对运行时间,增量为500。
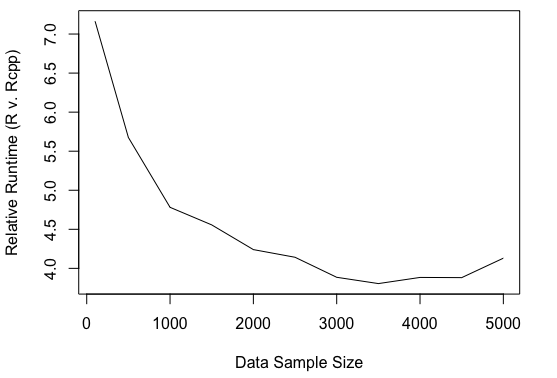
![]() ?
?
我不太确定究竟 如何解释这个练级了相对运行时间为样本容量增大。它似乎达到大约4的相对运行时间。
直观地说,C ++带来了一些固定的效率增益。可能值得更多地研究这一点,并准确理解效率增益的来源以及为什么它会逐渐消失。但很明显,Rcpp是解决代码瓶颈的好方法。如果您正在开发需要自定义采样器的新贝叶斯方法 。
大数据部落 -中国专业的第三方数据服务提供商,提供定制化的一站式数据挖掘和统计分析咨询服务
统计分析和数据挖掘咨询服务:y0.cn/teradat(咨询服务请联系官网客服)
![]() ?QQ:3025393450
?QQ:3025393450

![]() ?
?
【服务场景】
科研项目; 公司项目外包;线上线下一对一培训;数据采集;学术研究;报告撰写;市场调查。
【大数据部落】提供定制化的一站式数据挖掘和统计分析咨询服务
![]() ?
?
R语言用Rcpp加速Metropolis-Hastings抽样估计贝叶斯逻辑回归模型的参数
原文:https://www.cnblogs.com/tecdat/p/10751763.html