众所周知,不管是机器学习还是深度学习本质上都是对数字的数字,Word Embedding(词嵌入)做的事情就是将单词映射到向量空间里,并用向量来表示
对应的词所在的位置设为1,其他为0;
例如:King, Queen, Man and Woman这句里面Queen对应的向量就是[0,1,0,0][0,1,0,0]
不足:难以发现词之间的关系,以及难以捕捉句法(结构)和语义(意思)之间的关系
基本思想是把每个词表征为KK维的实数向量(每个实数都对应着一个特征,可以是和其他单词之间的联系),将相似的单词分组映射到向量空间的不同部分。也就是Word2Vec能在没有人为干涉下学习到单词之间的关系。
举个最经典的例子:
king- man + woman = queen
实际上的处理是:从king提取了maleness的含义,加上了woman具有的femaleness的意思,最后答案就是queen.
借助表格来理解就是:
| animal | pet | |
|---|---|---|
| dog | -0.4 | 0.02 |
| lion | 0.2 | 0.35 |
比如,animal那一列表示的就是左边的词与animal这个概念的相关性
原理:拥有差不多上下文的两个单词的意思往往是相近的
Continuous Bag-of-Words(CBOW)
功能:通过上下文预测当前词出现的概率
BOW的思想:v(“abc”)=1/3(v(“a”)+v(“b”)+v(“c”))v(“abc”)=1/3(v(“a”)+v(“b”)+v(“c”))
原理分析
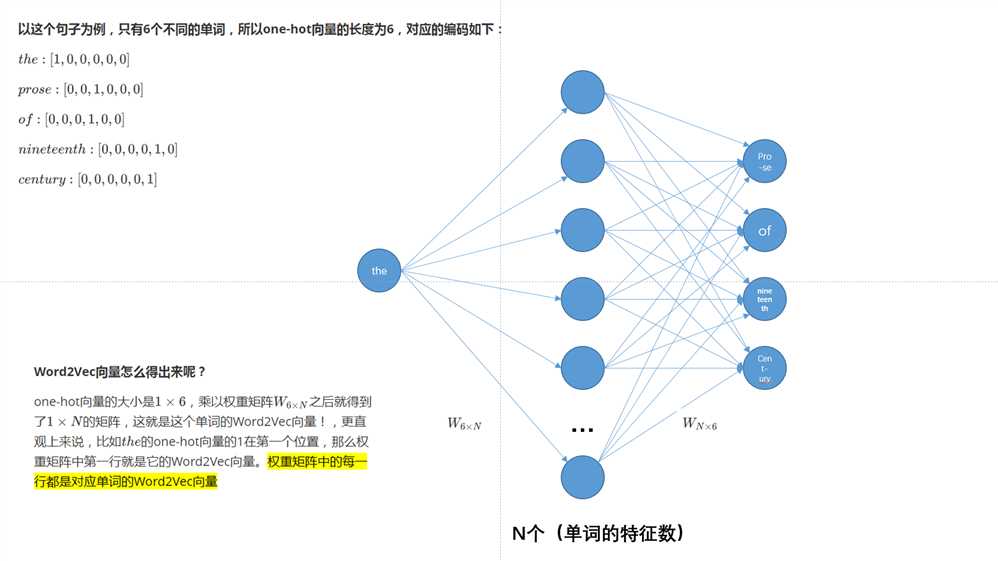
假设文本如下:“the florid prose of the nineteenth century.”
想象有个滑动窗口,中间的词是关键词,两边为相等长度(m,是超参数)的文本来帮助分析。文本的长度为7,就得到了7个one-hot向量,作为神经网络的输入向量,训练目标是:最大化在给定前后文本7情况下输出正确关键词的概率,比如给定("prose","of","nineteenth","century")的情况下,要最大化输出"the"的概率,用公式表示就是P("the"|("prose","of","nineteenth","century"))P("the"|("prose","of","nineteenth","century"))
特性
Skip-gram
不足
原文:https://www.cnblogs.com/lzc978/p/10774665.html