信息标记的三种形式:
XML(扩展标记语言)
JSON(js中面向对象的信息表达形式,由类型的(string)键值对组成)
"name":"北京理工大学"
YAML(无类型的键值对组成)
name:北京理工大学
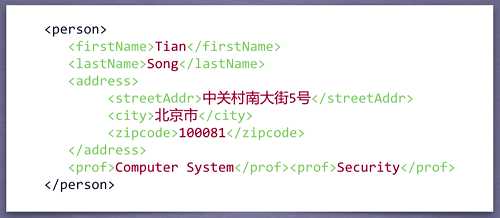


三种信息标记方式的应用区别
XML:internet上的信息传递与交互
JSON:移动应用云端的和几点的信息通信,无注释
YAML:各系统的配置文件,有注释、易读
结合形式解析与搜索的方法,获取指点标签里的内容
#!/usr/bin/python3 import requests from bs4 import BeautifulSoup url=‘http://python123.io/ws/demo.html‘ r=requests.get(url) if r.status_code==200: print(‘网络请求成功‘) demo=r.text soup=BeautifulSoup(demo,‘html.parser‘) for link in soup.find_all(‘a‘): print(link.get(‘href‘))
如果find_all()参数为True,所有标签将被打印出来
for tag in soup.find_all(True): print(tag.name)
原文:https://www.cnblogs.com/liberate20/p/10778524.html