官网:https://azkaban.readthedocs.io/en/latest/
Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,主要用于在一个工作流内以一个特定的顺序运行一组工作和流程,它的配置是通过简单的key:value对的方式,通过配置中的dependencies 来设置依赖关系,这个依赖关系必须是无环的,否则会被视为无效的工作流。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
在介绍Azkaban之前,我们先来看一下现有的两个工作流任务调度系统。知名度比较高的应该是Apache Oozie,但是其配置工作流的过程是编写大量的XML配置,而且代码复杂度比较高,不易于二次开发。另外一个应用也比较广泛的调度系统是Airflow,但是其开发语言是Python。由于我们团队内部使用Java作为主流开发语言,所以选型的时候就被淘汰掉了。我们选择Azkaban的原因基于以下几点:
实际项目中经常有这些场景:每天有一个大任务,这个大任务可以分成A,B,C,D四个小任务,A,B任务之间没有依赖关系,C任务依赖A,B任务的结果,D任务依赖C任务的结果。一般的做法是,开两个终端同时执行A,B,两个都执行完了再执行C,最后再执行D。这样的话,整个的执行过程都需要人工参加,并且得盯着各任务的进度。但是我们的很多任务都是在深更半夜执行的,通过写脚本设置crontab执行。其实,整个过程类似于一个有向无环图(DAG)。每个子任务相当于大任务中的一个流,任务的起点可以从没有度的节点开始执行,任何没有通路的节点之间可以同时执行,比如上述的A,B。总结起来的话,我们需要的就是一个工作流的调度器,而Azkaban就是能解决上述问题的一个调度器。
Azkaban在LinkedIn上实施,以解决Hadoop作业依赖问题。我们有工作需要按顺序运行,从ETL工作到数据分析产品。最初是单一服务器解决方案,随着多年来Hadoop用户数量的增加,Azkaban 已经发展成为一个更强大的解决方案。
Azkaban由三个关键组件构成:
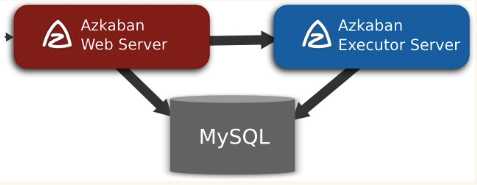
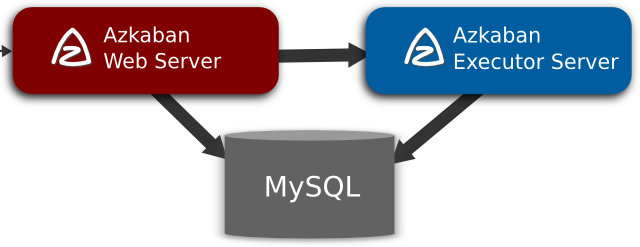
3.1 关系型数据库(MySQL)
Azkaban使用数据库存储大部分状态,AzkabanWebServer和AzkabanExecutorServer都需要访问数据库。
AzkabanWebServer使用数据库的原因如下:
AzkabanExecutorServer使用数据库的原因如下:
3.2 AzkabanWebServer
AzkabanWebServer是整个Azkaban工作流系统的主要管理者,它负责project管理、用户登录认证、定时执行工作流、跟踪工作流执行进度等一系列任务。同时,它还提供Web服务操作的接口,利用该接口,用户可以使用curl或其他ajax的方式,来执行azkaban的相关操作。操作包括:用户登录、创建project、上传workflow、执行workflow、查询workflow的执行进度、杀掉workflow等一系列操作,且这些操作的返回结果均是json的格式。并且Azkaban使用方便,Azkaban使用以.job为后缀名的键值属性文件来定义工作流中的各个任务,以及使用dependencies属性来定义作业间的依赖关系链。这些作业文件和关联的代码最终以*.zip的方式通过Azkaban UI上传到Web服务器上。
3.3 AzkabanExecutorServer
以前版本的Azkaban在单个服务中具有AzkabanWebServer和AzkabanExecutorServer功能,目前Azkaban已将AzkabanExecutorServer分离成独立的服务器,拆分AzkabanExecutorServer的原因有如下几点:
AzkabanExecutorServer主要负责具体的工作流的提交、执行,可以启动多个执行服务器,它们通过mysql数据库来协调任务的执行。
在版本3.0中,Azkaban提供了以下三种模式:
原文:https://www.cnblogs.com/pu20065226/p/10782604.html