一、问题:
在进行爬虫的时候我们会用到xpath解析html文件,但是会有一种情况就是在xpath选择器中可以使用,但是在代码中就无法使用的情况。

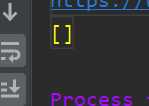
二、原因:
1.是元素中有tbody的原因,这个元素是html生成时产生的,在使用xpath解析的时候无法解析,因此返回的列表为空值。
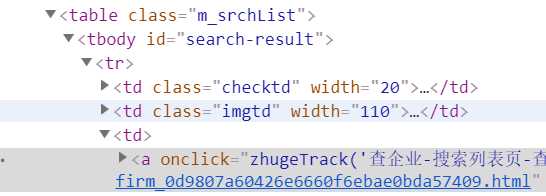
2.是因为没有写入获取的内容。比如在xpath选择其中可以使用但是在解析中没有带入//text()
三、解决办法:
1.因此解决办法便是删除掉tbody这个标签元素,因为它含有一个id的属性,所以不能使用这个属性。

2.解析中带上//text()
1 content_text = ‘‘.join(content.xpath(‘*//article[@class]/p[position()>2]//text()‘)).replace(‘\n‘, ‘‘).replace(‘ ‘, ‘‘) 2 time_ = ‘‘.join(content.xpath(‘//*[@id="news-time"]//text()‘)) 3 origin = ‘‘.join(content.xpath(‘//*[@id="user-info"]/h4/a//text()‘))
四、参考: