# coding:utf8 # author:Jery # datetime:2019/5/1 5:16 # software:PyCharm # function:爬取瓜子二手车 import requests from lxml import etree import re import csv start_url = ‘https://www.guazi.com/www/buy/o1c-1‘ headers = { ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36‘, ‘Cookie‘: ‘uuid=6032a689-d79a-4060-c8b0-f57d8db4e245; antipas=16I7A500578955101K231sG39E; clueSourceCode=10103000312%2300; user_city_id=49; ganji_uuid=3434204287155953305008; sessionid=405f3fb6-fb90-409d-c7ed-32874a157920; lg=1; cainfo=%7B%22ca_s%22%3A%22pz_baidu%22%2C%22ca_n%22%3A%22tbmkbturl%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22-%22%2C%22ca_content%22%3A%22%22%2C%22ca_campaign%22%3A%22%22%2C%22ca_kw%22%3A%22-%22%2C%22keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%22-%22%2C%22scode%22%3A%2210103000312%22%2C%22ca_transid%22%3A%22%22%2C%22platform%22%3A%221%22%2C%22version%22%3A1%2C%22ca_i%22%3A%22-%22%2C%22ca_b%22%3A%22-%22%2C%22ca_a%22%3A%22-%22%2C%22display_finance_flag%22%3A%22-%22%2C%22client_ab%22%3A%22-%22%2C%22guid%22%3A%226032a689-d79a-4060-c8b0-f57d8db4e245%22%2C%22sessionid%22%3A%22405f3fb6-fb90-409d-c7ed-32874a157920%22%7D; cityDomain=mianyang; _gl_tracker=%7B%22ca_source%22%3A%22-%22%2C%22ca_name%22%3A%22-%22%2C%22ca_kw%22%3A%22-%22%2C%22ca_id%22%3A%22-%22%2C%22ca_s%22%3A%22self%22%2C%22ca_n%22%3A%22-%22%2C%22ca_i%22%3A%22-%22%2C%22sid%22%3A20570070983%7D; preTime=%7B%22last%22%3A1556660763%2C%22this%22%3A1556659891%2C%22pre%22%3A1556659891%7D‘ } # 获取详情页面url def get_detail_urls(url): response = requests.get(url, headers=headers) text = response.content.decode(‘utf-8‘) html = etree.HTML(text) index = html.xpath(‘//ul[@class="pageLink clearfix"]/li[@class="link-on"]/a/span/text()‘) next_url = html.xpath(‘//ul[@class="pageLink clearfix"]/li/a/@href‘)[-1] ul = html.xpath(‘//ul[@class="carlist clearfix js-top"]‘)[0] lis = ul.xpath(‘./li‘) urls = [] for li in lis: detail_url = li.xpath(‘./a/@href‘) detail_url = ‘https://www.guazi.com‘ + detail_url[0] urls.append(detail_url) return urls, index, next_url def get_info(url): response = requests.get(url, headers=headers) text = response.content.decode(‘utf-8‘) html = etree.HTML(text) infos_dict = {} city = html.xpath(‘//p[@class="city-curr"]/text()‘)[0] city = re.search(r‘[\u4e00-\u9fa5]+‘, city).group(0) infos_dict[‘city‘] = city title = html.xpath(‘//div[@class="product-textbox"]/h2/text()‘)[0] infos_dict[‘title‘] = title.replace(r‘\r\n‘, ‘‘).strip() infos = html.xpath(‘//div[@class="product-textbox"]/ul/li/span/text()‘) infos_dict[‘cardtime‘] = infos[0] infos_dict[‘kms‘] = infos[1] if len(infos) == 4: infos_dict[‘cardplace‘] = ‘‘ infos_dict[‘displacement‘] = infos[2] infos_dict[‘speedbox‘] = infos[3] else: infos_dict[‘cardplace‘] = infos[2] infos_dict[‘displacement‘] = infos[3] infos_dict[‘speedbox‘] = infos[4] price = html.xpath(‘//div[@class="product-textbox"]/div/span[@class="pricestype"]/text()‘)[0] infos_dict[‘price‘] = re.search(r‘\d+.?\d+‘, price).group(0) return infos_dict def main(): with open(r"C:\Users\Jery\Desktop\guazi.csv", ‘w‘, newline=‘‘) as f: csvwriter_head = csv.writer(f, dialect=‘excel‘) csvwriter_head.writerow([‘城市‘, ‘车型‘, ‘上牌时间‘, ‘上牌地‘, ‘表显里程‘, ‘排量‘, ‘变速箱‘, ‘价格‘]) while True: global start_url urls, index, next_url = get_detail_urls(start_url) print("当前页码:{}*****************".format(index)) # 写表头 with open(r‘C:\Users\Jery\Desktop\guazi.csv‘, ‘a‘) as f: for url in urls: print("正在爬取:{}".format(url)) infos = get_info(url) print(infos) csvwriter = csv.writer(f, dialect=‘excel‘) csvwriter.writerow( [infos[‘city‘], infos[‘title‘], infos[‘cardtime‘], infos[‘cardplace‘], infos[‘kms‘], infos[‘displacement‘], infos[‘speedbox‘], infos[‘price‘]]) if next_url: start_url = ‘https://www.guazi.com‘ + next_url if __name__ == ‘__main__‘: main()
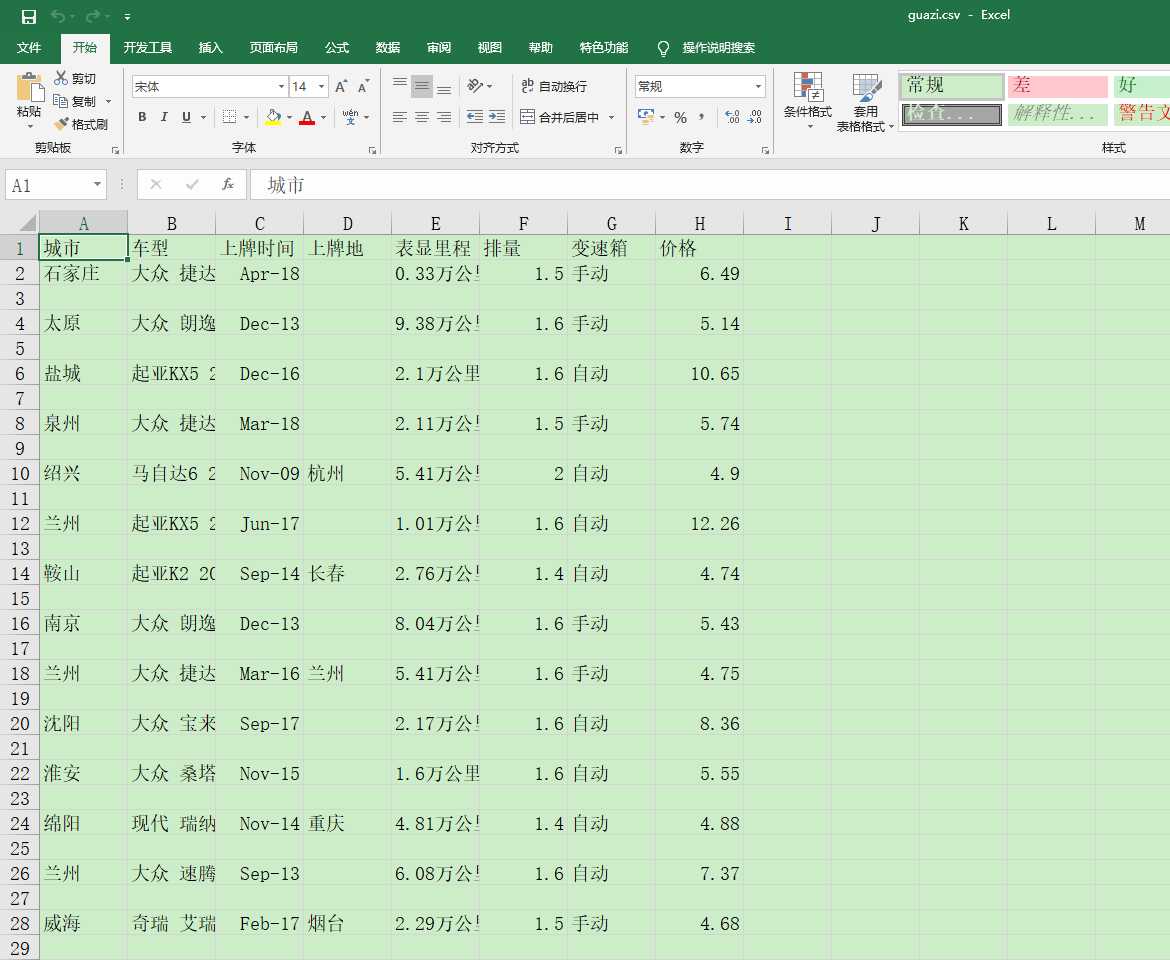
后续将进行数据分析
原文:https://www.cnblogs.com/Jery-9527/p/10799083.html