Encoder-Decoder框架:
目前大多数注意力模型附着在Encoder-Decoder框架下,当然,其实注意力模型可以看作一种通用的思想,本身并不依赖于特定框架,这点需要注意。
抽象的文本处理领域的Encoder-Decoder框架:
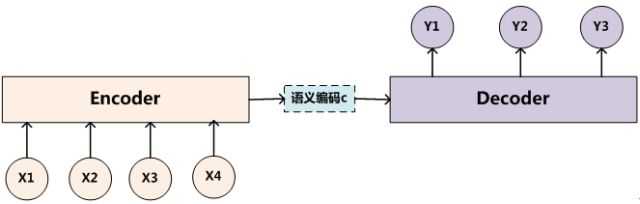
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。
Source和Target分别由各自的单词序列构成: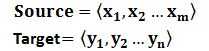
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
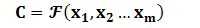
一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
参考:
https://zhuanlan.zhihu.com/p/37601161
https://github.com/Choco31415/Attention_Network_With_Keras
原文:https://www.cnblogs.com/ljygoodgoodstudydaydayup/p/10826187.html