之前讲过存储过程,存储过程和自定义函数还是非常相似的,其它的可以认为和存储过程是一样的,比如含义,优点都可以按存储过程的优点来理解。
存储过程相关博客:
3、MySQL(9)---纪录一次实际开发过程中用到的复杂存储过程
它们唯一不不同点在于
存储过程:可以有0个返回,也可以有多个返回,适合做批量插入、批量更新
函数 :有且仅有1 个返回,适合做处理数据后返回一个结果。
CREATE FUNCTION 函数名(参数列表) RETURNS 返回类型
BEGIN
函数体
END
/*
注意:
1、参数列表 包含两部分:参数名 参数类型
2、函数体:肯定会有return语句,如果没有会报错
如果return语句没有放在函数体的最后也不报错,但不建议
3、函数体中仅有一句话,则可以省略begin end
4、使用 delimiter语句设置结束标记
*/SELECT 函数名(参数列表)SHOW FUNCTION STATUS;DROP FUNCTION IF EXISTS function_name;先把例子需要用到表给出
# 商品表
DROP TABLE IF EXISTS `mall_pro`;
CREATE TABLE `mall_pro` (
`mall_id` char(32) NOT NULL,
`pro_name` varchar(32) DEFAULT '' COMMENT '显示名称',
`cash_cost` double(10,1) DEFAULT '0.0' COMMENT '商品价格',
`show_member` int(1) DEFAULT '0' COMMENT '显示 0所有 1指定会员',
`status` int(1) DEFAULT '1' COMMENT '状态:1正常 0删除',
`key_id` varchar(32) DEFAULT '0' COMMENT '会员控件表key',
PRIMARY KEY (`mall_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='商品表';
INSERT INTO `mall_pro` (`mall_id`, `pro_name`, `cash_cost`, `show_member`, `status`, `key_id`)
VALUES
('1','手表',100.0,0,1,'0'),
('2','手机',888.0,1,1,'0'),
('3','电脑',3888.0,1,1,'0');#案例:返回商品的个数
DELIMITER $
DROP FUNCTION IF EXISTS myf1;
CREATE FUNCTION myf1() RETURNS INT
BEGIN
DECLARE c INT DEFAULT 0;#定义局部变量
SELECT COUNT(*) INTO c#赋值
FROM mall_pro;
RETURN c;
END $
SELECT myf1()$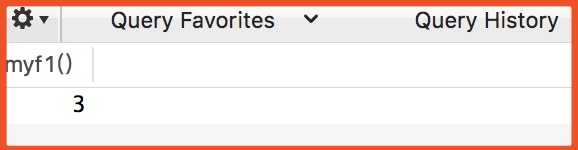
# 案例:根据商品名称返回商品价格
DELIMITER $
DROP FUNCTION IF EXISTS myf2$
CREATE FUNCTION myf2(proName VARCHAR(20)) RETURNS DOUBLE
BEGIN
SET @sal=0;#定义用户变量
SELECT cash_cost INTO @sal #赋值
FROM mall_pro
WHERE pro_name = proName;
RETURN @sal;
END $
SELECT myf2('手表') $这个会发现报异常
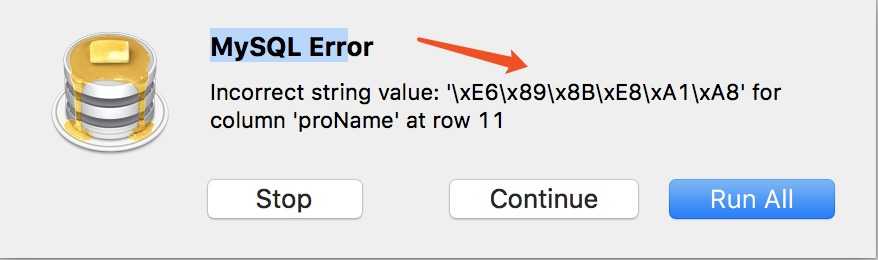
原因 在存储过程或者函数,传人参数是中文的时候,那么就需要将参数的类型VARCHAR改成NVARCHAR;

DELIMITER $
DROP FUNCTION IF EXISTS test_fun$
CREATE FUNCTION test_fun(num1 FLOAT,num2 FLOAT) RETURNS float
BEGIN
DECLARE SUM FLOAT DEFAULT 0;
SET SUM=num1+num2;
RETURN SUM;
END $
SELECT test_fun(1,2)$
总的来讲前面讲了存储过程,函数也没什么好讲的了,有什么疑问看存储过程相关文章应该都懂了。
只要自己变优秀了,其他的事情才会跟着好起来(少将11)原文:https://www.cnblogs.com/qdhxhz/p/10825538.html