写了一个练手的爬虫...在输出的时候出现了让人很不愉♂悦的问题
像这样:
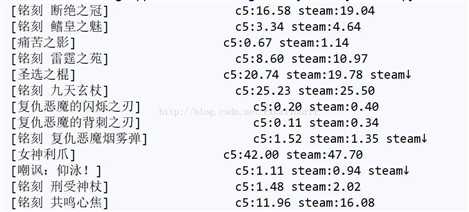
令人十分难受啊!
#-------------------------------------------------------------------------------------------------



还是有一些迷之问题导致1-0.5字节长度的偏差,猜测是由于中文字体不是等宽字体的缘故?
然而不用多虑,这里就可以使用一记粗暴的制表符\t解决问题了
print(‘[{name:<{len}}\tx‘.format(name=name+‘]‘,len=22-len(name.encode(‘GBK‘))+len(name)))
作者:killercars
来源:CSDN
原文:https://blog.csdn.net/excaliburrr/article/details/76794451
版权声明:本文为博主原创文章,转载请附上博文链接!
原文:https://www.cnblogs.com/Black-Ice/p/10846848.html