1 import requests 2 import time 3 import schedule 4 import smtplib 5 import numpy 6 from urllib.request import quote 7 from bs4 import BeautifulSoup 8 from email.mime.text import MIMEText 9 from email.header import Header 10 11 def fun_top250_3(): 12 13 movie_names = [] 14 15 for i in numpy.random.randint(0,249,3): 16 res = requests.get(‘https://movie.douban.com/top250?start={}‘.format(i)) 17 soup = BeautifulSoup(res.text,‘html.parser‘) 18 item = soup.find(‘div‘,class_=‘item‘).find(‘span‘).text 19 movie_names.append(item) 20 21 return movie_names 22 23 def fun_download_url(): 24 25 movie_names = fun_top250_3() 26 27 movie_names_urls = ‘‘ 28 29 for i in movie_names: 30 key_word = quote(i,encoding=‘gbk‘) 31 res = requests.get(‘http://s.ygdy8.com/plus/so.php?typeid=1&keyword={}‘.format(key_word)) 32 res.encoding=‘gbk‘ 33 soup = BeautifulSoup(res.text,‘html.parser‘) 34 check_none = soup.find(‘div‘,class_=‘co_content8‘).find(‘table‘) 35 36 if check_none: 37 item = soup.find(‘td‘,width=‘55%‘).find(‘b‘).find(‘a‘) 38 res = requests.get(‘https://www.ygdy8.com‘+item[‘href‘]) 39 res.encoding=‘gbk‘ 40 soup = BeautifulSoup(res.text,‘html.parser‘) 41 item = soup.find(‘td‘,style=‘WORD-WRAP: break-word‘).find(‘a‘).text 42 movie_names_urls += ‘电影名:{}\t下载链接:{}\n‘.format(i,item) 43 else: 44 movie_names_urls += ‘电影名:{}\t下载链接:没有找到\n‘.format(i) 45 46 return movie_names_urls 47 48 def fun_sendmail(): 49 50 movie_names_urls = fun_download_url() 51 52 mail_user = ‘www1707@xxx.cn‘ 53 mail_pwd = ‘yyy‘ 54 receiver = ‘user01@xxx.cn‘ 55 subject = time.strftime(‘%Y{}%W{}%S‘).format(‘年 第‘,‘周 推荐电影‘) 56 content = movie_names_urls 57 58 alimail = smtplib.SMTP() 59 alimail.connect(‘smtp.qiye.aliyun.com‘,25) 60 alimail.login(mail_user,mail_pwd) 61 62 message = MIMEText(content,‘plain‘,‘utf-8‘) 63 message[‘Subject‘] = Header(subject,‘utf-8‘) 64 message[‘From‘] = Header(mail_user,‘utf-8‘) 65 message[‘To‘] = Header(receiver,‘utf-8‘) 66 67 alimail.sendmail(mail_user,receiver,message.as_string()) 68 alimail.quit() 69 70 print(movie_names_urls) 71 72 #schedule.every().friday.do(fun_sendmail()) 73 schedule.every(10).seconds.do(fun_sendmail) 74 75 while True: 76 schedule.run_pending() 77 time.sleep(1)
1 import requests,csv,random,smtplib,schedule,time 2 from bs4 import BeautifulSoup 3 from urllib.request import quote 4 from email.mime.text import MIMEText 5 from email.header import Header 6 7 def get_movielist(): 8 csv_file=open(‘movieTop.csv‘, ‘w‘, newline=‘‘,encoding=‘utf-8‘) 9 writer = csv.writer(csv_file) 10 for x in range(10): 11 url = ‘https://movie.douban.com/top250?start=‘ + str(x*25) + ‘&filter=‘ 12 res = requests.get(url) 13 bs = BeautifulSoup(res.text, ‘html.parser‘) 14 bs = bs.find(‘ol‘, class_="grid_view") 15 for titles in bs.find_all(‘li‘): 16 title = titles.find(‘span‘, class_="title").text 17 list1 = [title] 18 writer.writerow(list1) 19 csv_file.close() 20 21 def get_randommovie(): 22 movielist=[] 23 csv_file=open(‘movieTop.csv‘,‘r‘,newline=‘‘,encoding=‘utf-8‘) 24 reader=csv.reader(csv_file) 25 for row in reader: 26 movielist.append(row[0]) 27 three_movies=random.sample(movielist,3) 28 contents=‘‘ 29 for movie in three_movies: 30 gbkmovie = movie.encode(‘gbk‘) 31 urlsearch = ‘http://s.ygdy8.com/plus/so.php?typeid=1&keyword=‘+quote(gbkmovie) 32 res = requests.get(urlsearch) 33 res.encoding=‘gbk‘ 34 soup_movie = BeautifulSoup(res.text,‘html.parser‘) 35 urlpart=soup_movie.find(class_="co_content8").find_all(‘table‘) 36 if urlpart: 37 urlpart=urlpart[0].find(‘a‘)[‘href‘] 38 urlmovie=‘https://www.ygdy8.com/‘+urlpart 39 res1=requests.get(urlmovie) 40 res1.encoding=‘gbk‘ 41 soup_movie1=BeautifulSoup(res1.text,‘html.parser‘) 42 urldownload=soup_movie1.find(‘div‘,id="Zoom").find(‘span‘).find(‘table‘).find(‘a‘)[‘href‘] 43 content=movie+‘\n‘+urldownload+‘\n\n‘ 44 print(content) 45 contents=contents+content 46 else: 47 content=‘没有‘+movie+‘的下载链接‘ 48 print(content) 49 return contents 50 51 def send_movielink(contents): 52 mailhost=‘smtp.qq.com‘ 53 qqmail = smtplib.SMTP() 54 qqmail.connect(mailhost,25) 55 account = ‘×××××××××@qq.com‘ # 因为是自己发给自己,所以邮箱账号、密码都可以提前设置好,当然,也可以发给别人啦 56 password = ‘××××××××××××××ב # 因为是自己发给自己,所以邮箱账号、密码都可以提前设置好,当然,也可以发给别人啦。 57 qqmail.login(account,password) 58 receiver=‘×××××××××@qq.com‘ # 因为是自己发给自己,所以邮箱账号、密码都可以提前设置好,当然,也可以发给别人啦。 59 message = MIMEText(contents, ‘plain‘, ‘utf-8‘) 60 subject = ‘电影链接‘ 61 message[‘Subject‘] = Header(subject, ‘utf-8‘) 62 try: 63 qqmail.sendmail(account, receiver, message.as_string()) 64 print (‘邮件发送成功‘) 65 except: 66 print (‘邮件发送失败‘) 67 qqmail.quit() 68 69 def job(): 70 get_movielist() 71 contents=get_randommovie() 72 send_movielink(contents) 73 74 schedule.every().friday.at("18:00").do(job)while True: 75 schedule.run_pending() 76 time.sleep(1)

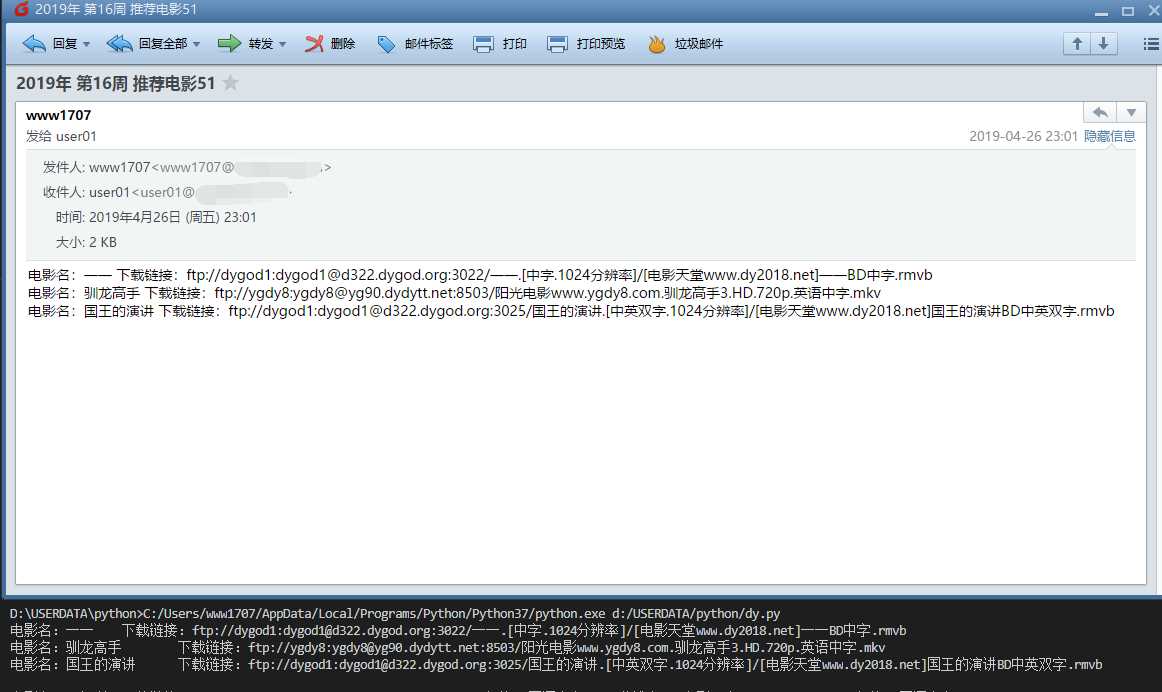
28、周末看电影(每周五自动从top250中随机选取三部电影,并将下载链接发到邮箱里)
原文:https://www.cnblogs.com/www1707/p/10850662.html