
我们将数据分为训练数据与测试数据,通过该算法(LRC),测试算法的效果,并比较其他人脸识别算法的优缺点。
一共有38组数据样本(38个人),每一组样本包含22个数据(22张同一个人的照片),每张照片有896个特征值。
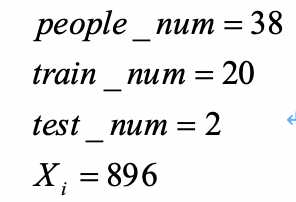
step1:图像转为向量空间,我们将需要处理的图片首先处理为一个特征向量,如一个a*b的图像采样为c*d,而后将所有列连接起来,转化为一个q*1的向量(a*b>c*d,q=c*d).
step2:我们将数据进行划分,我们按照人的种类进行划分得到每组样本,在每个人(共38人)的数据集中抽取2个数据放入测试集中进行测试(y),对剩下的数据集进行训练(X)。
step3:对每个人的训练集(Xi)计算帽子矩阵(![]() ),并存储下来。
),并存储下来。
step4:进行测试,我们将每组测试数据(y)带入残差公式中进行计算(![]() ),计算出使用不同样本(人)的H矩阵得到的残差值,从而残差值最小的位置,就是该测试集的标签。
),计算出使用不同样本(人)的H矩阵得到的残差值,从而残差值最小的位置,就是该测试集的标签。
step5:计数测试成功的个数,除以总测试数量计算识别率,而后重复几次进行交叉测试实验,求得最终的平均识别率(ave_rate).
clear all
load(‘C:\Users\apple\Desktop\Y.mat‘)%读取矩阵数据
load(‘C:\Users\apple\Desktop\X.mat‘)
people_num=length(unique(Y));%人种
train_num=20; %m为训练的照片数
test_num=22-train_num;%n为测试的照片数 38人 每个人22张
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%数据分类
kfold=22;%22叠交叉验证
ind=crossvalind(‘Kfold‘,Y,kfold);%%分成n叠,其中第一叠作为测试集合,其他的叠作为训练集
crossvalidNum=length(unique(ind));
ave_rate=0;
X=X‘;
Y=Y‘;
for j=1:crossvalidNum-2 %测试20次每次抽取一份为训练数据
indTest=(ind==j|ind==j+1);
train=X(:,~indTest); %分拣除测试数据、训练数据
test=X(:,indTest);
train_label=Y(~indTest);
test_label=Y(indTest);
% vectorize
train=normc(train);
test=normc(test);
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%进行多元线性回归
people_data_train=cell(1,people_num);%数据分组
people_data_test=cell(1,people_num);
for i=1:people_num
people_data_train{i}=train(:,train_num*i-train_num+1:train_num*i);
people_data_test{i}=test(:,test_num*i-test_num+1:test_num*i);
end
H=cell(1,people_num); %每个人的函数矩阵B
for i=1:people_num %38个人
H{i}=people_data_train{i}*pinv(people_data_train{i}‘*people_data_train{i})*people_data_train{i}‘;
end
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%测试
counter=0;%计数器,成功的个数
for p=1:people_num
for t=1:test_num
s=zeros(people_num,1);
for i=1:people_num
s(i)=norm(people_data_test{p}(:,t)-H{i}*people_data_test{p}(:,t));
end
id=find(s==min(s));
counter=counter+(id==p);
end
end
rate=counter/size(test,2);
ave_rate=ave_rate+rate;
disp([‘ LRC res=‘ num2str(rate)])
end
fprintf(1,‘mean_rate %f \n‘,ave_rate/(crossvalidNum-2));
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
第一次测试:直接运行程序
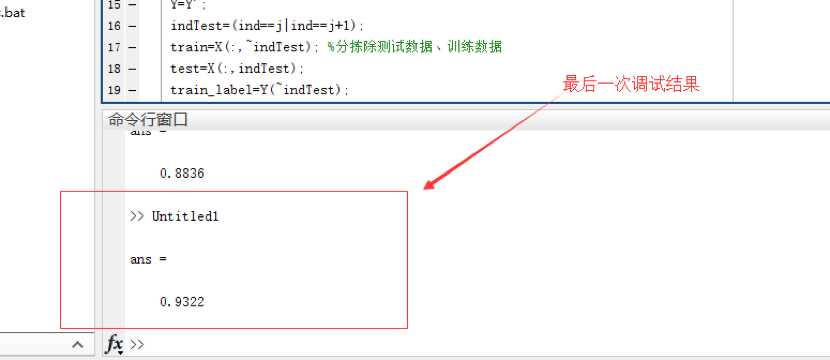
最后我们算得的识别率为93.22%,基本还算理想。
第二次测试:我将每一次内部交叉测试的结果进行了打印
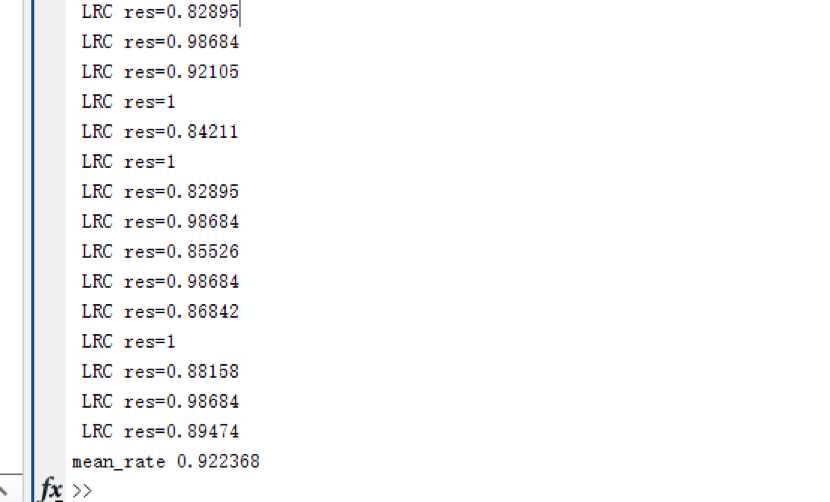
结果的识别率约为92.2%,基本也还算理想
从本次实验还算理想,在这过程中问题重重,在不断在改进,发现问题,解决问题。
问题一:由于计算的矩阵过大,在求逆的时候,计算精度受到限制,总是会报出奇异矩阵计算误差的问题。
解决方式:求伪逆,在MATLAB中有个专门计算伪逆的函数(pinv()),且成功率为98%以上。
问题二:在问题分析上出错,从而计算的结果偏差过大,一般识别率只有0.2。
解决方式:重新审视题目,明白错把y当中人脸的label,实际上y就是测试数据中的测试向量,其实回归的是同一点的特征值。
问题三:在我解决了上述两个问题后,识别率基本能够达到88.2%,但是还是未达到预期的目标(90%以上),我检查了代码的问题,以及
计算矩阵的逆时的误差。
解决方式:我检查代码时发现,我发现矩阵归一化时可能出了问题,直接调用MATLAB中的(mornc())函数进行标准化后识别率已经到达了90%以上,效果比较好
人脸识别(Linear Regression for Face Recognition)模拟实验(一)
原文:https://www.cnblogs.com/wangxingwu12138/p/10859949.html