说明:这份数据集是金融数据(非原始数据,已经处理过了),我们要做的是预测贷款用户是否会逾期。表格中 "status" 是结果标签:0表示未逾期,1表示逾期。
描述:任务、遇到的问题、实现代码和参考资料
因为时间也比较仓促,而且人笨了,这么多特征(英文多)实在想不出怎么做特征衍生,以后慢慢学习吧!!
首先处理一下数据
%matplotlib inline import matplotlib.pyplot as plt import pandas as pd import numpy as np df = pd.read_csv(‘data.csv‘) df_raw = df.copy() df.dropna(axis=0,inplace=True) df.drop([‘custid‘,‘trade_no‘,‘bank_card_no‘,‘source‘,‘id_name‘],axis=1,inplace=True) df.drop([‘consume_top_time_last_1_month‘,‘consume_top_time_last_6_month‘],axis=1,inplace=True) #这两个特征重复了 new_df = pd.DataFrame(pd.to_datetime(df[‘loans_latest_time‘]) - pd.to_datetime(df[‘loans_latest_time‘].min())) df[‘loans_latest_time‘] = new_df df[‘loans_latest_time‘] = df[‘loans_latest_time‘].map(lambda x:x.days) new_df = pd.DataFrame(pd.to_datetime(df[‘latest_query_time‘]) - pd.to_datetime(df[‘latest_query_time‘].min())) df[‘latest_query_time‘] = new_df df[‘latest_query_time‘] = df[‘latest_query_time‘].map(lambda x:x.days) #一样的操作 from sklearn import preprocessing label = preprocessing.LabelEncoder() reg = label.fit_transform(df[‘reg_preference_for_trad‘]) df[‘reg_preference_for_trad‘] = reg
#特征选择 #1根据相关系数 coor = df.corr() corr_status = abs(coor[‘status‘]) corr_status_sorted = corr_status.sort_values(ascending=False) corr_status_sorted = corr_status_sorted[corr_status_sorted.values>0.1] #根据相关系数大于0.1,最终选择出12个特征 features_index = corr_status_sorted.index corr_status_sorted
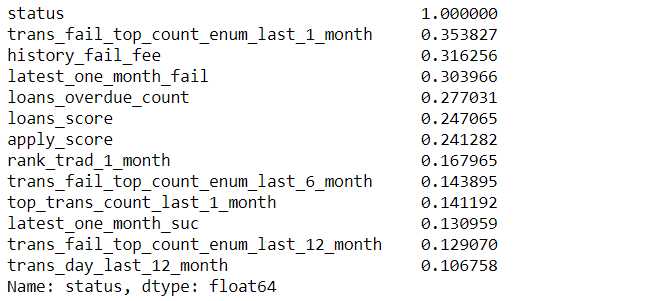
自己对IV值的理解就是计算特征基于特定分组后的分类与目标特征的正确分类之间的差距值,注意特征的分组方式可以有很多,所以要将所有计算的IV加起来,就是该特征的IV值
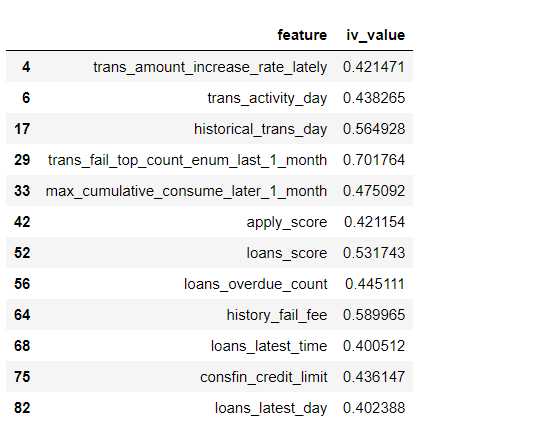
#2根据IV(信息价值) #此函数借鉴于别人,因为自己也是才学习到IV这个概念 def calc_iv(df, feature, target, pr=False): """ Set pr=True to enable printing of output. Output: * iv: float, * data: pandas.DataFrame """ lst = [] df[feature] = df[feature].fillna(‘NULL‘) for i in range(df[feature].nunique()): # nuinque()是查看该序列(axis=0/1对应着列或行)的不同值的数量个数 val = list(df[feature].unique())[i] #这里是讲特征里的每个值作为分组,也可以分段分组 lst.append([feature, val, # Value df[df[feature] == val].count()[feature], # 特征中等于分组值的计数 df[(df[feature] == val) & (df[target] == 0)].count()[feature], # good rate df[(df[feature] == val) & (df[target] == 1)].count()[feature]]) # bad rate data = pd.DataFrame(lst, columns=[‘Variable‘, ‘Value‘, ‘All‘, ‘Good‘, ‘Bad‘]) data[‘Share‘] = data[‘All‘] / data[‘All‘].sum() data[‘Bad Rate‘] = data[‘Bad‘] / data[‘All‘] data[‘Distribution Good‘] = (data[‘All‘] - data[‘Bad‘]) / (data[‘All‘].sum() - data[‘Bad‘].sum()) data[‘Distribution Bad‘] = data[‘Bad‘] / data[‘Bad‘].sum() data[‘WoE‘] = np.log(data[‘Distribution Good‘] / data[‘Distribution Bad‘]) #woe计算式为log((根据分组值选出的好的/所有的好的)/ #(根据分组值选出的坏的的/所有的坏的) data = data.replace({‘WoE‘: {np.inf: 0, -np.inf: 0}}) data[‘IV‘] = data[‘WoE‘] * (data[‘Distribution Good‘] - data[‘Distribution Bad‘]) #计算iv要乘后面那个是为了保证用比率来限制iv #并且iv值范围为【0,+无穷】 data = data.sort_values(by=[‘Variable‘, ‘Value‘], ascending=[True, True]) data.index = range(len(data.index)) if pr: print(data) print("IV = ", data[‘IV‘].sum()) iv = data[‘IV‘].sum() #所有分组值的iv求和就是该特征的iv值 return iv, data column_headers = list(df.columns.values) # print(column_headers) d=[] for x in column_headers: #输入每个特征,单独计算IV值 IV_1, data = calc_iv(df, x, ‘status‘) d.append(IV_1) #整理成Series类型并合并 column_headers=pd.Series(column_headers,name=‘feature‘) d=pd.Series(d,name=‘iv_value‘) # print(column_headers) iv_result=pd.concat([column_headers,d],axis=1) iv_result.sort_values(by=‘iv_value‘,ascending=False)
iv_result[iv_result[‘iv_value‘]>0.4] #选择大于0.4值的作为特征
#3利用随机深林的算法算出特征的重要性 y = df[‘status‘] X = df[df.loc[:,df.columns != ‘status‘].columns] from sklearn.ensemble import RandomForestClassifier forest_clf = RandomForestClassifier() forest_clf.fit(X,y) features_weights = dict(zip(df.columns,forest_clf.feature_importances_)) features_weights_sorted = sorted(features_weights.items(),key = lambda x:x[1],reverse = True) #根据值排序,并选择前15个 for item in range(15): print(features_weights_sorted[item][0],‘:‘,features_weights_sorted[item][1])

原文:https://www.cnblogs.com/Hero1best/p/10864846.html