想起以前NOIP考试前死记硬背,然而并没有什么……
字符串匹配很容易就能写出蛮力算法,即枚举主串中每个位置,把模式串放在这个位置,然后依次比对每一位,比对到不同的地方马上往后跳
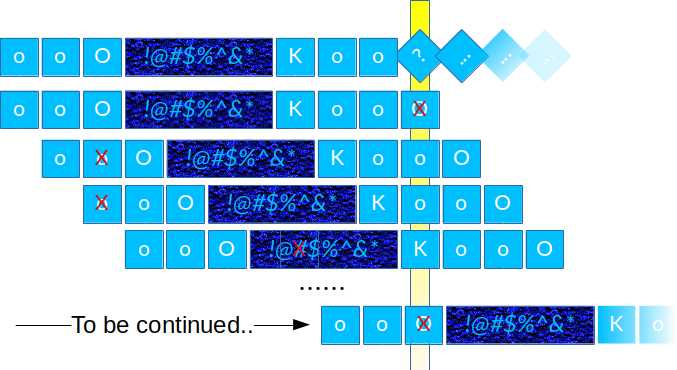
运气好(数据随机、构成字符串的字符种类多),仅仅一次比对就可以发现错误,可是对于最坏情况就会浪费很多时间(如直到最后一个才成功),虽然这样的情况很少,导致期望水平都是线性,但某些条件下不好的情况还是多一些……比如DNA序列中只有四个字母,浪费时间的几率就会增加
因此需要把模式串快速移动到某个位置,使到匹配失败的前缀等于已经匹配了的某个后缀,如上图第一行后缀与最后一行前缀
为了不漏掉中间的这种情况,需要保证匹配得最长
鸽了:(
原文:https://www.cnblogs.com/sahdsg/p/10865489.html