(Learning a Deep Convolutional Network for Image Super-Resolution, ECCV2014)
摘要:我们提出了一种单图像超分辨率的深度学习方法(SR)。我们的方法直接学习在低/高分辨率图像之间的端到端映射。这个映射表现为通过一个深度的卷积神经网络CNN,把低分辨率的图像作为输入,输出高分辨率图像。我们进一步证明了基于传统的稀疏编码超分辨的方法也可以看作是一个深卷积网络。但不像传统的方法一样分离的处理每一个组成,我们的方法联合优化了所有层。我们的深度CNN有一个轻量级的结构,然而展示了最先进的修复质量,并实现了快速的实际在线使用。
1.介绍
单图像超分辨率[11]是计算机视觉中的一个经典问题。目前最先进的单图像超分辨率方法大多是基于实例的。这些方法要么利用同一图像的内部相似性,要么从外部低分辨率和高分辨率样本对学习映射函数[2, 4, 9, 13, 20, 24–26, 28]。基于外部实例的方法往往具有丰富的样本,但同时也面临着对数据进行有效、简洁的建模困难。
基于稀疏编码的方法[25,26]是基于外部实例的图像超分辨率的代表性方法之一。该方法在其管道中涉及几个步骤。首先,从图像中密集提取重叠的patch并进行预处理(减去均值)。然后用低分辨率字典对这些patches进行编码。将稀疏系数传递到高分辨率字典中,重建高分辨率patches。将重叠的重构patches聚合(或平均)以生成输出。以前的SR方法特别注重字典的学习和优化或者用其他方法对它们建模。然而,管道中的剩下的步骤很少在统一的优化框架中进行优化或考虑。
在这篇论文中,我们证明了上述管道相当于一个深卷积神经网络(更多细节见第3.2节)。出于这结果,我们直接考虑卷积神经网络,它是在低分辨率和高分辨率图像之间的端到端映射。我们的方法与现有的基于实例的外部方法有根本的不同,因为我们没有显式地学习字典[20,25,26]或复写[2,4]来建模patch空间。这些都是通过隐藏层隐式实现的。此外,patch的提取和聚集也被表示为卷积层,因此涉及到优化。在我们的方法中,整个SR管道都是通过学习得到的,几乎没有预处理/后处理。
我们命名提出的模型为 Super-Resolution Convolutional Neural Network (SRCNN)。我们提出的SRCNN有几个吸引人的特性。第一,它的结构是有意设计得简单,但与最先进的基于实例的方法相比,它提供了更高的精确度。Figure 1给出了一个例子的比较。第二,通过适当的滤波器和层数,我们的方法实现了快速的实际在线使用,甚至是在CPU上的训练。我们的方法比一系列基于实例的方法更快,因为它是完全前馈的,不需要在使用中解决任何优化问题。第三,实验表明,当给网络更多的数据集或者(和)更大的网络时,网络的恢复质量会得到更深的提高。相反,较大的数据集/模型可能对现有的基于实例的方法提出挑战。
总的来说,这项工作的贡献主要体现在三个方面:
1.我们提出了一种用于图像超分辨率的卷积神经网络。该网络直接学习低分辨率和高分辨率图像之间的端到端映射,除了优化之外,几乎没有什么预处理/后处理。
2.我们建立了基于深度学习的SR方法与传统的基于稀疏编码的SR方法之间的关系。这种关系为网络结构的设计提供了指导。
3.我们证明了深度学习在经典的超分辨率计算机视觉问题中是有用的,可以达到良好的质量和速度。
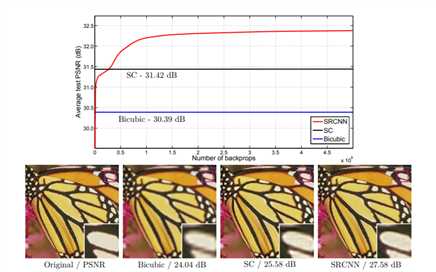
Figure 1 提出的SRCNN仅仅通过几次训练迭代就超过了双三次基线,并通过适当的训练,使其性能优于基于稀疏编码的[26]方法。随着更多的训练迭代,性能可能会进一步提高。
2.相关工作
图像超分辨率 一类最先进的SR方法[学习低/高分辨率patches之间的映射。这些研究如何学习一个紧凑的字典或多方面的空间来关联低/高分辨率的patches,以及如何在这些空间中进行表示方案方面存在差异。在Freeman开创性的工作中,字典被直接表示为低/高分辨率的patch对,在低分辨率空间中找到输入patch的最近邻(NN),用其对应的高分辨率patch进行重建。Change介绍了一种流形嵌入技术作为神经网络策略的替代方法。在Yang等人的工作中[25,26],上述NN对应关系提出了一种更为复杂的稀疏编码公式。这种基于稀疏编码的方法及其若干改进[24,20]是目前最先进的SR方法之一。在这些方法中,patches是优化的重点;将patch提取和聚集步骤视为预处理/后处理,并分别处理。
论文学习 :Learning a Deep Convolutional Network for Image Super-Resolution 2014
原文:https://www.cnblogs.com/zgqcn/p/10869381.html