先看一下实验的两张表:

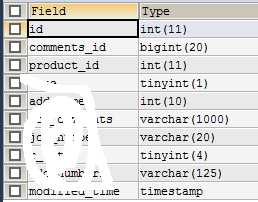
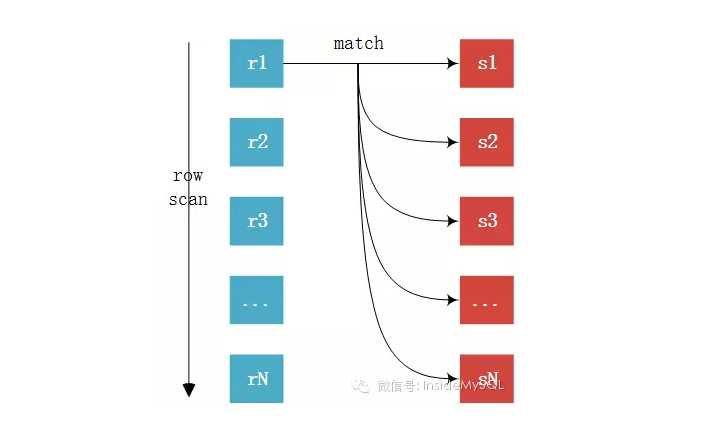
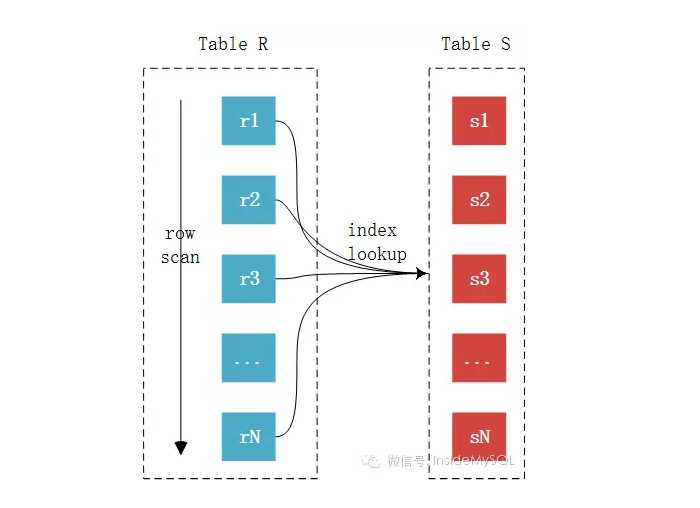

EXPLAIN SELECT * FROM comments gc JOIN comments_for gcf ON gc.comments_id=gcf.comments_id;

SELECT * FROM comments gc JOIN comments_for gcf ON gc.comments_id=gcf.comments_id WHERE gc.comments_id =2056

EXPLAIN SELECT * FROM comments gc JOIN comments_for gcf ON gc.order_id=gcf.product_id

EXPLAIN SELECT * FROM comments gc LEFT JOIN comments_for gcf ON gc.comments_id=gcf.comments_id

EXPLAIN SELECT * FROM comments_for gcf LEFT JOIN comments gc ON gc.comments_id=gcf.comments_id WHERE gcf.comments_id =2056
 此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。
此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。原文:https://www.cnblogs.com/zping/p/10875977.html