整体架构
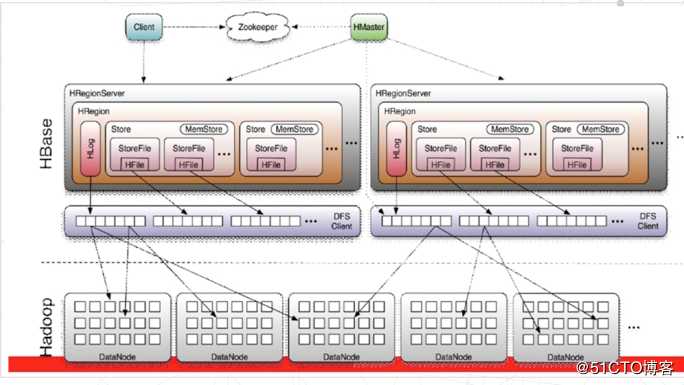
- client负责访问hbase,并维护cache
- zookeeper
负责master的主备切换;
负责监控RegionServer的状态,将Region server的上线和下线信息实时通知给Master
存储所有Region寻址入库;
保存hbase的schema,包含有哪些table,每个table有哪些列簇
- master
负责分配region到不同的RegionServer,既RegionServer的负载均衡;
负责处理schema的更新请求
- RegionServer
维护master分配的region,负责对这些region的IO请求(读写);
切分比较大的region
存储方式
- 一个table会按行分为多个region,最开始只有一个region,在region变大之后,regionserver会对region进行切分;
- 一个region有多个store,每个store存储一个列簇;store由一个在内存中的memstore和0到多个storefile组成。数据写入时是写入到memstore中,如果memstore超过了一定阈值,则会新开一个memstore,而原来的memstore则有单独的进程写到磁盘上。
- 每个storefile以HFile的格式保存到HDFS上。
- HFile由多个部分组成,其中比较重要的是DataBlock和DataBlockIndex(每条索引的key是被索引的block的第一条记录的key)组成,在读取一个HFile时,会先把DataBlockIndex加载到内存中,定位到具体的DataBlock段,然后再把此段加载到内存中
- HLog:每个Region Server维护一个Hlog,而不是每个Region一个。HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是”写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。HLog Sequece File的Value是Hbase的KeyValue对象,即对应HFile中的KeyValue
关键流程
- region定位
第一层是保存zookeeper里面的文件,它持有root region的位置。
第二层root region是.META.表的第一个region其中保存了.META.z表其它region的位置。通过root region,我们就可以访问.META.表的数据。
META.是第三层,它是一个特殊的表,保存了Hbase中所有数据表的region 位置信息。META.表每行保存一个region的位置信息,row key 采用表名+表的最后一样编码而成。保存了HRegionInfo(包含了startkey、endkey),服务器的信息
- 读流程
获取将要读取Region的位置信息;
Client向HRegionServer发出读请求。
HRegionServer先从MemStore读取数据,如未找到,再从StoreFile中读取。
- 写流程
数据在更新时首先写入Log(WAL log)和内存(MemStore)中,MemStore中的数据是排序的,当MemStore累计到一定阈值时,就会创建一个新的MemStore,并 且将老的MemStore添加到flush队列,由单独的线程flush到磁盘上,成为一个StoreFile。
Hbase
原文:https://blog.51cto.com/4876017/2395937